 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3rd Place Solution for MOSE Track in CVPR 2024 PVUW workshop: Complex Video Object Segmentation
Jun 06, 2024



Video Object Segmentation (VOS) is a vital task in computer vision, focusing on distinguishing foreground objects from the background across video frames. Our work draws inspiration from the Cutie model, and we investigate the effects of object memory, the total number of memory frames, and input resolution on segmentation performance. This report validates the effectiveness of our inference method on the coMplex video Object SEgmentation (MOSE) dataset, which features complex occlusions. Our experimental results demonstrate that our approach achieves a J\&F score of 0.8139 on the test set, securing the third position in the final ranking. These findings highlight the robustness and accuracy of our method in handling challenging VOS scenarios.
Compass: A Decentralized Scheduler for Latency-Sensitive ML Workflows
Feb 28, 2024



We consider ML query processing in distributed systems where GPU-enabled workers coordinate to execute complex queries: a computing style often seen in applications that interact with users in support of image processing and natural language processing. In such systems, coscheduling of GPU memory management and task placement represents a promising opportunity. We propose Compass, a novel framework that unifies these functions to reduce job latency while using resources efficiently, placing tasks where data dependencies will be satisfied, collocating tasks from the same job (when this will not overload the host or its GPU), and efficiently managing GPU memory. Comparison with other state of the art schedulers shows a significant reduction in completion times while requiring the same amount or even fewer resources. In one case, just half the servers were needed for processing the same workload.
Towards Efficient Verification of Quantized Neural Networks
Dec 27, 2023



Quantization replaces floating point arithmetic with integer arithmetic in deep neural network models, providing more efficient on-device inference with less power and memory. In this work, we propose a framework for formally verifying properties of quantized neural networks. Our baseline technique is based on integer linear programming which guarantees both soundness and completeness. We then show how efficiency can be improved by utilizing gradient-based heuristic search methods and also bound-propagation techniques. We evaluate our approach on perception networks quantized with PyTorch. Our results show that we can verify quantized networks with better scalability and efficiency than the previous state of the art.
Cascade: A Platform for Delay-Sensitive Edge Intelligence
Nov 29, 2023



Interactive intelligent computing applications are increasingly prevalent, creating a need for AI/ML platforms optimized to reduce per-event latency while maintaining high throughput and efficient resource management. Yet many intelligent applications run on AI/ML platforms that optimize for high throughput even at the cost of high tail-latency. Cascade is a new AI/ML hosting platform intended to untangle this puzzle. Innovations include a legacy-friendly storage layer that moves data with minimal copying and a "fast path" that collocates data and computation to maximize responsiveness. Our evaluation shows that Cascade reduces latency by orders of magnitude with no loss of throughput.
LAE-ST-MoE: Boosted Language-Aware Encoder Using Speech Translation Auxiliary Task for E2E Code-switching ASR
Oct 07, 2023



Recently, to mitigate the confusion between different languages in code-switching (CS) automatic speech recognition (ASR), the conditionally factorized models, such as the language-aware encoder (LAE), explicitly disregard the contextual information between different languages. However, this information may be helpful for ASR modeling. To alleviate this issue, we propose the LAE-ST-MoE framework. It incorporates speech translation (ST) tasks into LAE and utilizes ST to learn the contextual information between different languages. It introduces a task-based mixture of expert modules, employing separate feed-forward networks for the ASR and ST tasks. Experimental results on the ASRU 2019 Mandarin-English CS challenge dataset demonstrate that, compared to the LAE-based CTC, the LAE-ST-MoE model achieves a 9.26% mix error reduction on the CS test with the same decoding parameter. Moreover, the well-trained LAE-ST-MoE model can perform ST tasks from CS speech to Mandarin or English text.
The Robust Semantic Segmentation UNCV2023 Challenge Results
Sep 27, 2023



This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and journals over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.
Enhancing the Unified Streaming and Non-streaming Model with Contrastive Learning
Jun 01, 2023



The unified streaming and non-streaming speech recognition model has achieved great success due to its comprehensive capabilities. In this paper, we propose to improve the accuracy of the unified model by bridging the inherent representation gap between the streaming and non-streaming modes with a contrastive objective. Specifically, the top-layer hidden representation at the same frame of the streaming and non-streaming modes are regarded as a positive pair, encouraging the representation of the streaming mode close to its non-streaming counterpart. The multiple negative samples are randomly selected from the rest frames of the same sample under the non-streaming mode. Experimental results demonstrate that the proposed method achieves consistent improvements toward the unified model in both streaming and non-streaming modes. Our method achieves CER of 4.66% in the streaming mode and CER of 4.31% in the non-streaming mode, which sets a new state-of-the-art on the AISHELL-1 benchmark.
FreConv: Frequency Branch-and-Integration Convolutional Networks
Apr 10, 2023



Recent researches indicate that utilizing the frequency information of input data can enhance the performance of networks. However, the existing popular convolutional structure is not designed specifically for utilizing the frequency information contained in datasets. In this paper, we propose a novel and effective module, named FreConv (frequency branch-and-integration convolution), to replace the vanilla convolution. FreConv adopts a dual-branch architecture to extract and integrate high- and low-frequency information. In the high-frequency branch, a derivative-filter-like architecture is designed to extract the high-frequency information while a light extractor is employed in the low-frequency branch because the low-frequency information is usually redundant. FreConv is able to exploit the frequency information of input data in a more reasonable way to enhance feature representation ability and reduce the memory and computational cost significantly. Without any bells and whistles, experimental results on various tasks demonstrate that FreConv-equipped networks consistently outperform state-of-the-art baselines.
HUSP-SP: Faster Utility Mining on Sequence Data
Dec 29, 2022



High-utility sequential pattern mining (HUSPM) has emerged as an important topic due to its wide application and considerable popularity. However, due to the combinatorial explosion of the search space when the HUSPM problem encounters a low utility threshold or large-scale data, it may be time-consuming and memory-costly to address the HUSPM problem. Several algorithms have been proposed for addressing this problem, but they still cost a lot in terms of running time and memory usage. In this paper, to further solve this problem efficiently, we design a compact structure called sequence projection (seqPro) and propose an efficient algorithm, namely discovering high-utility sequential patterns with the seqPro structure (HUSP-SP). HUSP-SP utilizes the compact seq-array to store the necessary information in a sequence database. The seqPro structure is designed to efficiently calculate candidate patterns' utilities and upper bound values. Furthermore, a new upper bound on utility, namely tighter reduced sequence utility (TRSU) and two pruning strategies in search space, are utilized to improve the mining performance of HUSP-SP. Experimental results on both synthetic and real-life datasets show that HUSP-SP can significantly outperform the state-of-the-art algorithms in terms of running time, memory usage, search space pruning efficiency, and scalability.
Improving CTC-based ASR Models with Gated Interlayer Collaboration
May 25, 2022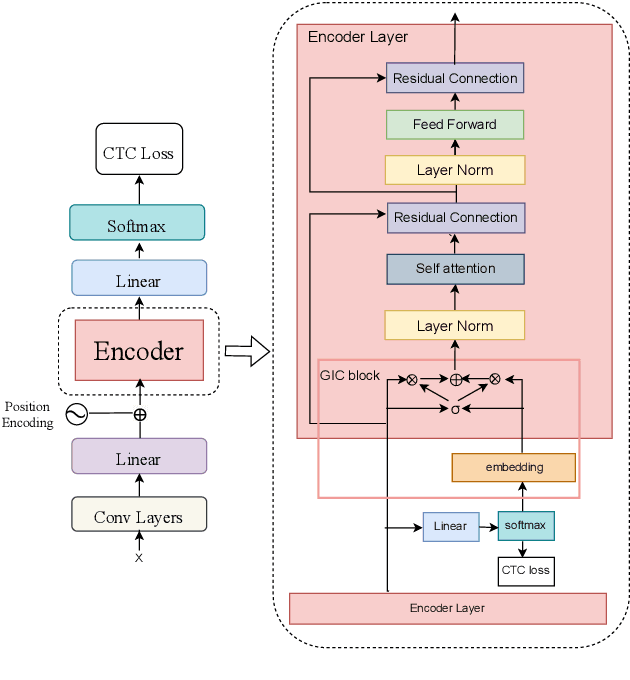
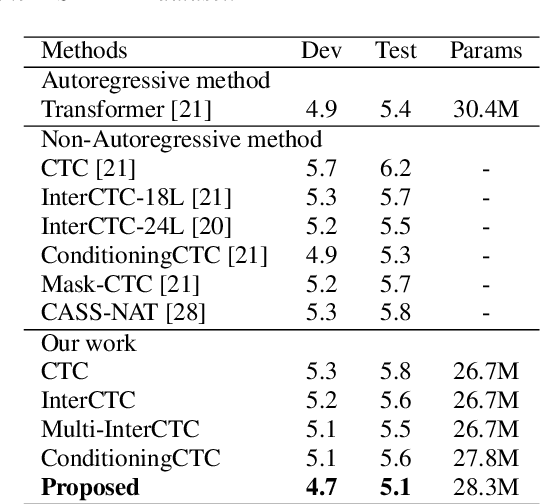
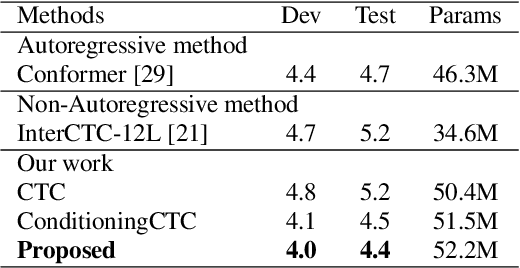
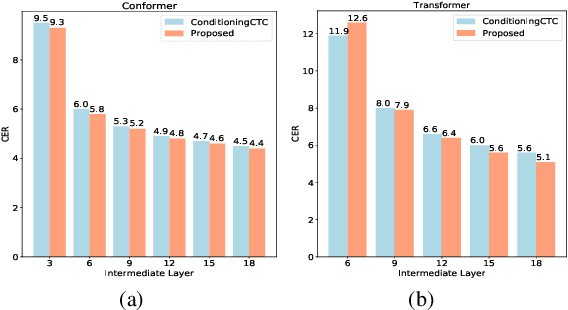
For Automatic Speech Recognition (ASR), the CTC-based methods have become a dominant paradigm due to its simple architecture and efficient non-autoregressive inference manner. However, these methods without external language models usually lack the capacity of modeling the conditional dependencies and the textual interaction. In this work, we present a Gated Interlayer Collaboration (GIC) mechanism which introduces the contextual information into the models and relaxes the conditional independence assumption of the CTC-based models. Specifically, we train the model with intermediate CTC losses calculated by the interlayer outputs of the model, in which the probability distributions of the intermediate layers naturally serve as soft label sequences. The GIC block consists of an embedding layer to obtain the textual embedding of the soft label at each position, and a gate unit to fuse the textual embedding and the acoustic features. Experiments on AISHELL-1 and AIDATATANG benchmarks show that the proposed method outperforms the recently published CTC-based ASR models. Specifically, our method achieves CER of 4.0%/4.4% on AISHELL-1 dev/test sets and CER of 3.8%/4.4% on AIDATATANG dev/test sets using CTC greedy search decoding without external language models.