 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Prediction as Implicit Classification to Identify LLM-Generated Text
Nov 15, 2023



This paper introduces a novel approach for identifying the possible large language models (LLMs) involved in text generation. Instead of adding an additional classification layer to a base LM, we reframe the classification task as a next-token prediction task and directly fine-tune the base LM to perform it. We utilize the Text-to-Text Transfer Transformer (T5) model as the backbone for our experiments. We compared our approach to the more direct approach of utilizing hidden states for classification. Evaluation shows the exceptional performance of our method in the text classification task, highlighting its simplicity and efficiency. Furthermore, interpretability studies on the features extracted by our model reveal its ability to differentiate distinctive writing styles among various LLMs even in the absence of an explicit classifier. We also collected a dataset named OpenLLMText, containing approximately 340k text samples from human and LLMs, including GPT3.5, PaLM, LLaMA, and GPT2.
PyPose v0.6: The Imperative Programming Interface for Robotics
Sep 22, 2023



PyPose is an open-source library for robot learning. It combines a learning-based approach with physics-based optimization, which enables seamless end-to-end robot learning. It has been used in many tasks due to its meticulously designed application programming interface (API) and efficient implementation. From its initial launch in early 2022, PyPose has experienced significant enhancements, incorporating a wide variety of new features into its platform. To satisfy the growing demand for understanding and utilizing the library and reduce the learning curve of new users, we present the fundamental design principle of the imperative programming interface, and showcase the flexible usage of diverse functionalities and modules using an extremely simple Dubins car example. We also demonstrate that the PyPose can be easily used to navigate a real quadruped robot with a few lines of code.
$\pi2\text{vec}$: Policy Representations with Successor Features
Jun 16, 2023



This paper describes $\pi2\text{vec}$, a method for representing behaviors of black box policies as feature vectors. The policy representations capture how the statistics of foundation model features change in response to the policy behavior in a task agnostic way, and can be trained from offline data, allowing them to be used in offline policy selection. This work provides a key piece of a recipe for fusing together three modern lines of research: Offline policy evaluation as a counterpart to offline RL, foundation models as generic and powerful state representations, and efficient policy selection in resource constrained environments.
GPT-Sentinel: Distinguishing Human and ChatGPT Generated Content
May 17, 2023This paper presents a novel approach for detecting ChatGPT-generated vs. human-written text using language models. To this end, we first collected and released a pre-processed dataset named OpenGPTText, which consists of rephrased content generated using ChatGPT. We then designed, implemented, and trained two different models for text classification, using Robustly Optimized BERT Pretraining Approach (RoBERTa) and Text-to-Text Transfer Transformer (T5), respectively. Our models achieved remarkable results, with an accuracy of over 97% on the test dataset, as evaluated through various metrics. Furthermore, we conducted an interpretability study to showcase our model's ability to extract and differentiate key features between human-written and ChatGPT-generated text. Our findings provide important insights into the effective use of language models to detect generated text.
Discovering Attention-Based Genetic Algorithms via Meta-Black-Box Optimization
Apr 08, 2023



Genetic algorithms constitute a family of black-box optimization algorithms, which take inspiration from the principles of biological evolution. While they provide a general-purpose tool for optimization, their particular instantiations can be heuristic and motivated by loose biological intuition. In this work we explore a fundamentally different approach: Given a sufficiently flexible parametrization of the genetic operators, we discover entirely new genetic algorithms in a data-driven fashion. More specifically, we parametrize selection and mutation rate adaptation as cross- and self-attention modules and use Meta-Black-Box-Optimization to evolve their parameters on a set of diverse optimization tasks. The resulting Learned Genetic Algorithm outperforms state-of-the-art adaptive baseline genetic algorithms and generalizes far beyond its meta-training settings. The learned algorithm can be applied to previously unseen optimization problems, search dimensions & evaluation budgets. We conduct extensive analysis of the discovered operators and provide ablation experiments, which highlight the benefits of flexible module parametrization and the ability to transfer (`plug-in') the learned operators to conventional genetic algorithms.
Discovering Evolution Strategies via Meta-Black-Box Optimization
Nov 25, 2022



Optimizing functions without access to gradients is the remit of black-box methods such as evolution strategies. While highly general, their learning dynamics are often times heuristic and inflexible - exactly the limitations that meta-learning can address. Hence, we propose to discover effective update rules for evolution strategies via meta-learning. Concretely, our approach employs a search strategy parametrized by a self-attention-based architecture, which guarantees the update rule is invariant to the ordering of the candidate solutions. We show that meta-evolving this system on a small set of representative low-dimensional analytic optimization problems is sufficient to discover new evolution strategies capable of generalizing to unseen optimization problems, population sizes and optimization horizons. Furthermore, the same learned evolution strategy can outperform established neuroevolution baselines on supervised and continuous control tasks. As additional contributions, we ablate the individual neural network components of our method; reverse engineer the learned strategy into an explicit heuristic form, which remains highly competitive; and show that it is possible to self-referentially train an evolution strategy from scratch, with the learned update rule used to drive the outer meta-learning loop.
NEVIS'22: A Stream of 100 Tasks Sampled from 30 Years of Computer Vision Research
Nov 15, 2022We introduce the Never Ending VIsual-classification Stream (NEVIS'22), a benchmark consisting of a stream of over 100 visual classification tasks, sorted chronologically and extracted from papers sampled uniformly from computer vision proceedings spanning the last three decades. The resulting stream reflects what the research community thought was meaningful at any point in time. Despite being limited to classification, the resulting stream has a rich diversity of tasks from OCR, to texture analysis, crowd counting, scene recognition, and so forth. The diversity is also reflected in the wide range of dataset sizes, spanning over four orders of magnitude. Overall, NEVIS'22 poses an unprecedented challenge for current sequential learning approaches due to the scale and diversity of tasks, yet with a low entry barrier as it is limited to a single modality and each task is a classical supervised learning problem. Moreover, we provide a reference implementation including strong baselines and a simple evaluation protocol to compare methods in terms of their trade-off between accuracy and compute. We hope that NEVIS'22 can be useful to researchers working on continual learning, meta-learning, AutoML and more generally sequential learning, and help these communities join forces towards more robust and efficient models that efficiently adapt to a never ending stream of data. Implementations have been made available at https://github.com/deepmind/dm_nevis.
Multi-step Planning for Automated Hyperparameter Optimization with OptFormer
Oct 10, 2022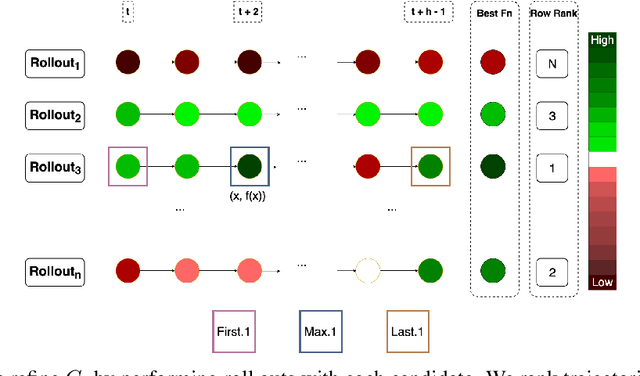
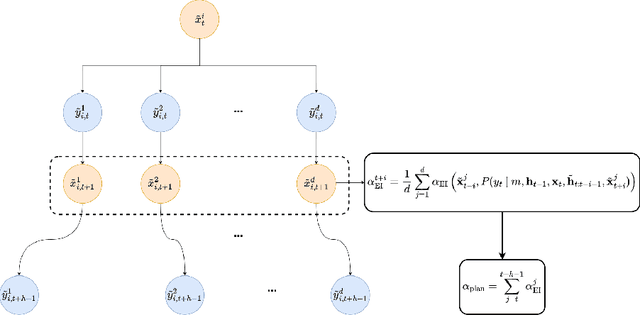
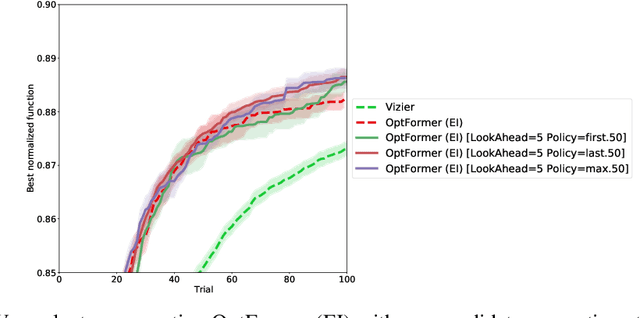
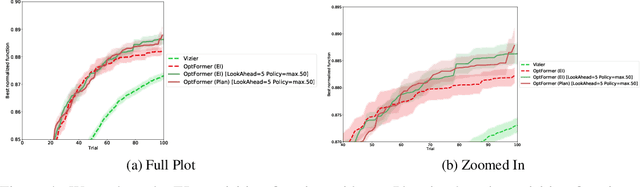
As machine learning permeates more industries and models become more expensive and time consuming to train, the need for efficient automated hyperparameter optimization (HPO) has never been more pressing. Multi-step planning based approaches to hyperparameter optimization promise improved efficiency over myopic alternatives by more effectively balancing out exploration and exploitation. However, the potential of these approaches has not been fully realized due to their technical complexity and computational intensity. In this work, we leverage recent advances in Transformer-based, natural-language-interfaced hyperparameter optimization to circumvent these barriers. We build on top of the recently proposed OptFormer which casts both hyperparameter suggestion and target function approximation as autoregressive generation thus making planning via rollouts simple and efficient. We conduct extensive exploration of different strategies for performing multi-step planning on top of the OptFormer model to highlight its potential for use in constructing non-myopic HPO strategies.
Towards Learning Universal Hyperparameter Optimizers with Transformers
May 26, 2022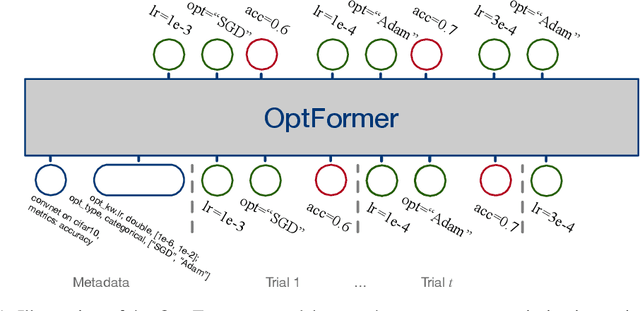


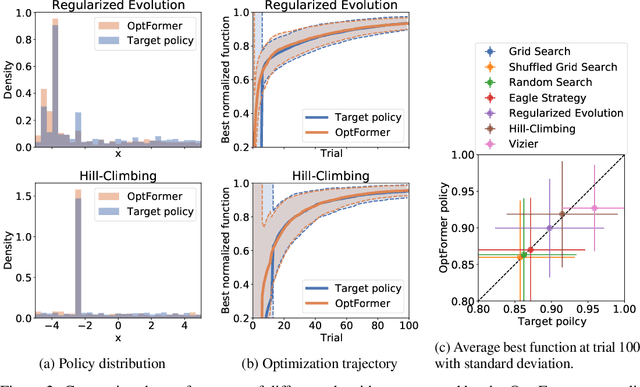
Meta-learning hyperparameter optimization (HPO) algorithms from prior experiments is a promising approach to improve optimization efficiency over objective functions from a similar distribution. However, existing methods are restricted to learning from experiments sharing the same set of hyperparameters. In this paper, we introduce the OptFormer, the first text-based Transformer HPO framework that provides a universal end-to-end interface for jointly learning policy and function prediction when trained on vast tuning data from the wild. Our extensive experiments demonstrate that the OptFormer can imitate at least 7 different HPO algorithms, which can be further improved via its function uncertainty estimates. Compared to a Gaussian Process, the OptFormer also learns a robust prior distribution for hyperparameter response functions, and can thereby provide more accurate and better calibrated predictions. This work paves the path to future extensions for training a Transformer-based model as a general HPO optimizer.
A Generalist Agent
May 19, 2022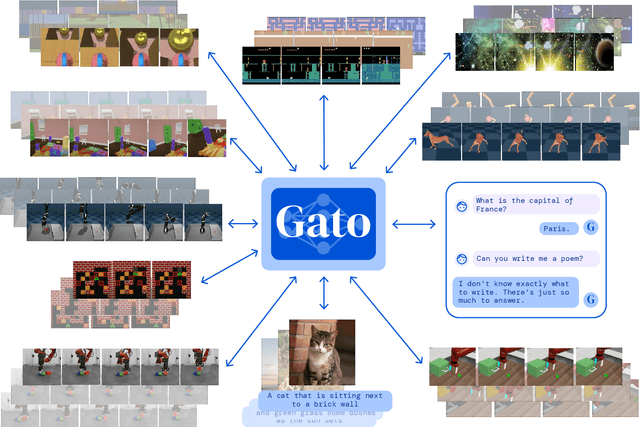
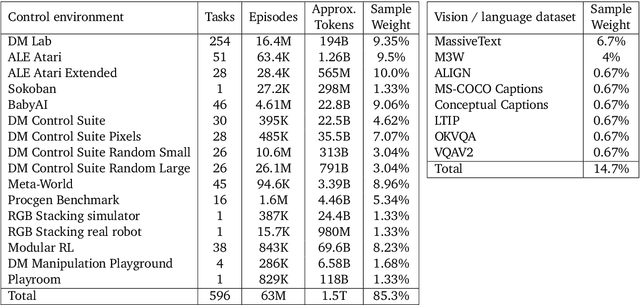
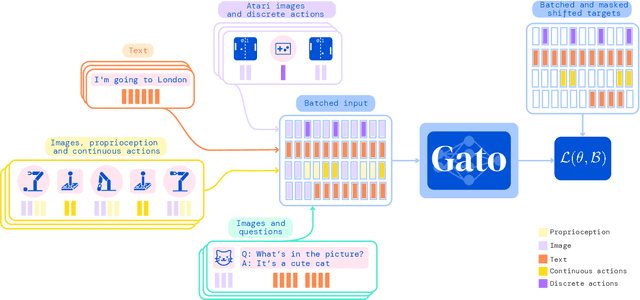

Inspired by progress in large-scale language modeling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens. In this report we describe the model and the data, and document the current capabilities of Gato.