 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting the Brain-like Representation by an Improved Self-Organizing Map for Image Classification
Mar 16, 2023



Backpropagation-based supervised learning has achieved great success in computer vision tasks. However, its biological plausibility is always controversial. Recently, the bio-inspired Hebbian learning rule (HLR) has received extensive attention. Self-Organizing Map (SOM) uses the competitive HLR to establish connections between neurons, obtaining visual features in an unsupervised way. Although the representation of SOM neurons shows some brain-like characteristics, it is still quite different from the neuron representation in the human visual cortex. This paper proposes an improved SOM with multi-winner, multi-code, and local receptive field, named mlSOM. We observe that the neuron representation of mlSOM is similar to the human visual cortex. Furthermore, mlSOM shows a sparse distributed representation of objects, which has also been found in the human inferior temporal area. In addition, experiments show that mlSOM achieves better classification accuracy than the original SOM and other state-of-the-art HLR-based methods. The code is accessible at https://github.com/JiaHongZ/mlSOM.
BIFRNet: A Brain-Inspired Feature Restoration DNN for Partially Occluded Image Recognition
Mar 16, 2023



The partially occluded image recognition (POIR) problem has been a challenge for artificial intelligence for a long time. A common strategy to handle the POIR problem is using the non-occluded features for classification. Unfortunately, this strategy will lose effectiveness when the image is severely occluded, since the visible parts can only provide limited information. Several studies in neuroscience reveal that feature restoration which fills in the occluded information and is called amodal completion is essential for human brains to recognize partially occluded images. However, feature restoration is commonly ignored by CNNs, which may be the reason why CNNs are ineffective for the POIR problem. Inspired by this, we propose a novel brain-inspired feature restoration network (BIFRNet) to solve the POIR problem. It mimics a ventral visual pathway to extract image features and a dorsal visual pathway to distinguish occluded and visible image regions. In addition, it also uses a knowledge module to store object prior knowledge and uses a completion module to restore occluded features based on visible features and prior knowledge. Thorough experiments on synthetic and real-world occluded image datasets show that BIFRNet outperforms the existing methods in solving the POIR problem. Especially for severely occluded images, BIRFRNet surpasses other methods by a large margin and is close to the human brain performance. Furthermore, the brain-inspired design makes BIFRNet more interpretable.
A Multi-Head Convolutional Neural Network With Multi-path Attention improves Image Denoising
Apr 27, 2022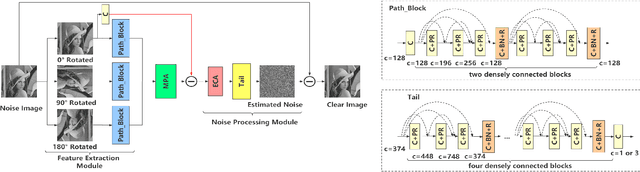
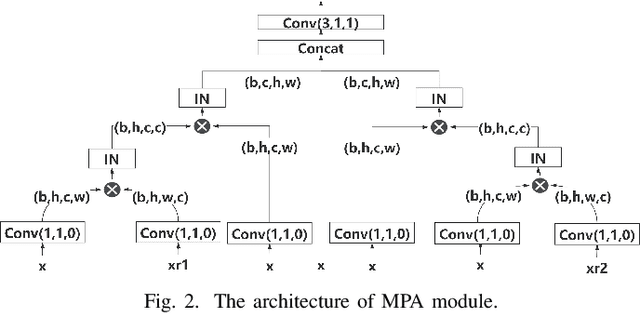


Recently, convolutional neural networks (CNNs) and attention mechanisms have been widely used in image denoising and achieved satisfactory performance. However, the previous works mostly use a single head to receive the noisy image, limiting the richness of extracted features. Therefore, a novel CNN with multiple heads (MH) named MHCNN is proposed in this paper, whose heads will receive the input images rotated by different rotation angles. MH makes MHCNN simultaneously utilize features of rotated images to remove noise. We also present a novel multi-path attention mechanism (MPA) to integrate these features effectively. Unlike previous attention mechanisms that handle pixel-level, channel-level, and patch-level features, MPA focuses on features at the image level. Experiments show MHCNN surpasses other state-of-the-art CNN models on additive white Gaussian noise (AWGN) denoising and real-world image denoising. Its peak signal-to-noise ratio (PSNR) results are higher than other networks, such as DnCNN, BRDNet, RIDNet, PAN-Net, and CSANN. It is also demonstrated that the proposed MH with MPA mechanism can be used as a pluggable component.
A biological plausible audio-visual integration model for continual lifelong learning
Jul 17, 2020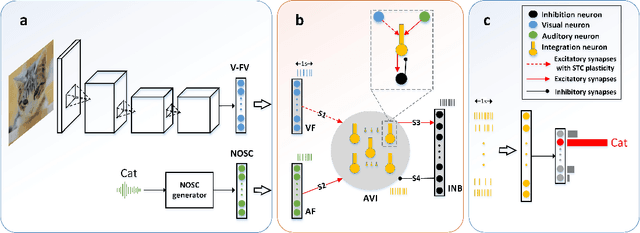
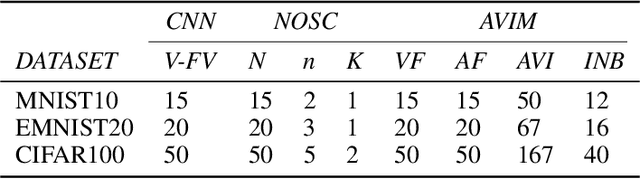
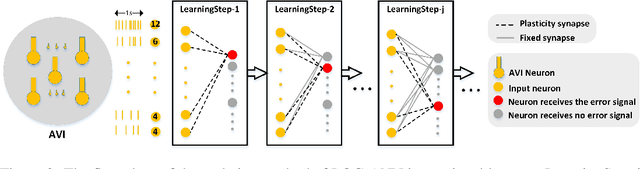
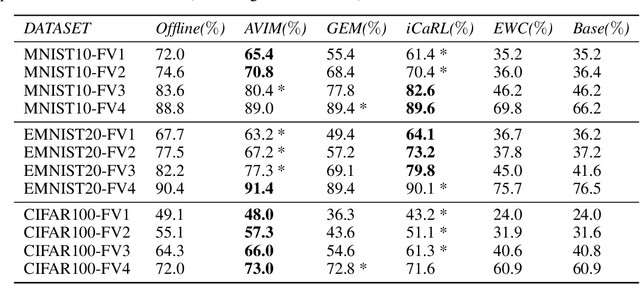
The problem of catastrophic forgetting can be traced back to the 1980s, but it has not been completely solved. Since human brains are good at continual lifelong learning, brain-inspired methods may provide solutions to this problem. The end result of learning different objects in different categories is the formation of concepts in the brain. Experiments showed that concepts are likely encoded by concept cells in the medial temporal lobe (MTL) of the human brain. Furthermore, concept cells encode concepts sparsely and are responsive to multi-modal stimuli. However, it is unknown how concepts are formed in the MTL. Here we assume that the integration of audio and visual perceptual information in the MTL during learning is a crucial step to form concepts and make continual learning possible, and we propose a biological plausible audio-visual integration model (AVIM), which is a spiking neural network with multi-compartmental neuron model and a calcium based synaptic tagging and capture plasticity model, as a possible mechanism of concept formation. We then build such a model and run on different datasets to test its ability of continual learning. Our simulation results show that the AVIM not only achieves state-of-the-art performance compared with other advanced methods but also the output of AVIM for each concept has stable representations during the continual learning process. These results support our assumption that concept formation is essential for continuous lifelong learning, and suggest the AVIM we propose here is a possible mechanism of concept formation, and hence is a brain-like solution to the problem of catastrophic forgetting.