 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Multimodal Large Language Model Editing via Invariant Trajectory Learning
Jan 30, 2026Knowledge editing emerges as a crucial technique for efficiently correcting incorrect or outdated knowledge in large language models (LLM). Existing editing methods rely on a rigid mapping from parameter or module modifications to output, which causes the generalization limitation in Multimodal LLM (MLLM). In this paper, we reformulate MLLM editing as an out-of-distribution (OOD) generalization problem, where the goal is to discern semantic shift with factual shift and thus achieve robust editing among diverse cross-modal prompting. The key challenge of this OOD problem lies in identifying invariant causal trajectories that generalize accurately while suppressing spurious correlations. To address it, we propose ODEdit, a plug-and-play invariant learning based framework that optimizes the tripartite OOD risk objective to simultaneously enhance editing reliability, locality, and generality.We further introduce an edit trajectory invariant learning method, which integrates a total variation penalty into the risk minimization objective to stabilize edit trajectories against environmental variations. Theoretical analysis and extensive experiments demonstrate the effectiveness of ODEdit.
ThinkTank-ME: A Multi-Expert Framework for Middle East Event Forecasting
Jan 22, 2026Event forecasting is inherently influenced by multifaceted considerations, including international relations, regional historical dynamics, and cultural contexts. However, existing LLM-based approaches employ single-model architectures that generate predictions along a singular explicit trajectory, constraining their ability to capture diverse geopolitical nuances across complex regional contexts. To address this limitation, we introduce ThinkTank-ME, a novel Think Tank framework for Middle East event forecasting that emulates collaborative expert analysis in real-world strategic decision-making. To facilitate expert specialization and rigorous evaluation, we construct POLECAT-FOR-ME, a Middle East-focused event forecasting benchmark. Experimental results demonstrate the superiority of multi-expert collaboration in handling complex temporal geopolitical forecasting tasks. The code is available at https://github.com/LuminosityX/ThinkTank-ME.
iTIMO: An LLM-empowered Synthesis Dataset for Travel Itinerary Modification
Jan 15, 2026Addressing itinerary modification is crucial for enhancing the travel experience as it is a frequent requirement during traveling. However, existing research mainly focuses on fixed itinerary planning, leaving modification underexplored. To bridge this gap, we formally define the itinerary modification task and introduce iTIMO, a dataset specifically tailored for this purpose. We identify the lack of {\itshape need-to-modify} itinerary data as the critical bottleneck hindering research on this task and propose a general pipeline to overcome it. This pipeline frames the generation of such data as an intent-driven perturbation task. It instructs large language models to perturb real world itineraries using three atomic editing operations: REPLACE, ADD, and DELETE. Each perturbation is grounded in three intents, including disruptions of popularity, spatial distance, and category diversity. Furthermore, a hybrid evaluation metric is designed to ensure perturbation effectiveness. We conduct comprehensive experiments on iTIMO, revealing the limitations of current LLMs and lead to several valuable directions for future research. Dataset and corresponding code are available at https://github.com/zelo2/iTIMO.
Frozen LVLMs for Micro-Video Recommendation: A Systematic Study of Feature Extraction and Fusion
Dec 26, 2025Frozen Large Video Language Models (LVLMs) are increasingly employed in micro-video recommendation due to their strong multimodal understanding. However, their integration lacks systematic empirical evaluation: practitioners typically deploy LVLMs as fixed black-box feature extractors without systematically comparing alternative representation strategies. To address this gap, we present the first systematic empirical study along two key design dimensions: (i) integration strategies with ID embeddings, specifically replacement versus fusion, and (ii) feature extraction paradigms, comparing LVLM-generated captions with intermediate decoder hidden states. Extensive experiments on representative LVLMs reveal three key principles: (1) intermediate hidden states consistently outperform caption-based representations, as natural-language summarization inevitably discards fine-grained visual semantics crucial for recommendation; (2) ID embeddings capture irreplaceable collaborative signals, rendering fusion strictly superior to replacement; and (3) the effectiveness of intermediate decoder features varies significantly across layers. Guided by these insights, we propose the Dual Feature Fusion (DFF) Framework, a lightweight and plug-and-play approach that adaptively fuses multi-layer representations from frozen LVLMs with item ID embeddings. DFF achieves state-of-the-art performance on two real-world micro-video recommendation benchmarks, consistently outperforming strong baselines and providing a principled approach to integrating off-the-shelf large vision-language models into micro-video recommender systems.
HV-Attack: Hierarchical Visual Attack for Multimodal Retrieval Augmented Generation
Nov 19, 2025Advanced multimodal Retrieval-Augmented Generation (MRAG) techniques have been widely applied to enhance the capabilities of Large Multimodal Models (LMMs), but they also bring along novel safety issues. Existing adversarial research has revealed the vulnerability of MRAG systems to knowledge poisoning attacks, which fool the retriever into recalling injected poisoned contents. However, our work considers a different setting: visual attack of MRAG by solely adding imperceptible perturbations at the image inputs of users, without manipulating any other components. This is challenging due to the robustness of fine-tuned retrievers and large-scale generators, and the effect of visual perturbation may be further weakened by propagation through the RAG chain. We propose a novel Hierarchical Visual Attack that misaligns and disrupts the two inputs (the multimodal query and the augmented knowledge) of MRAG's generator to confuse its generation. We further design a hierarchical two-stage strategy to obtain misaligned augmented knowledge. We disrupt the image input of the retriever to make it recall irrelevant knowledge from the original database, by optimizing the perturbation which first breaks the cross-modal alignment and then disrupts the multimodal semantic alignment. We conduct extensive experiments on two widely-used MRAG datasets: OK-VQA and InfoSeek. We use CLIP-based retrievers and two LMMs BLIP-2 and LLaVA as generators. Results demonstrate the effectiveness of our visual attack on MRAG through the significant decrease in both retrieval and generation performance.
Potent but Stealthy: Rethink Profile Pollution against Sequential Recommendation via Bi-level Constrained Reinforcement Paradigm
Nov 14, 2025Sequential Recommenders, which exploit dynamic user intents through interaction sequences, is vulnerable to adversarial attacks. While existing attacks primarily rely on data poisoning, they require large-scale user access or fake profiles thus lacking practicality. In this paper, we focus on the Profile Pollution Attack that subtly contaminates partial user interactions to induce targeted mispredictions. Previous PPA methods suffer from two limitations, i.e., i) over-reliance on sequence horizon impact restricts fine-grained perturbations on item transitions, and ii) holistic modifications cause detectable distribution shifts. To address these challenges, we propose a constrained reinforcement driven attack CREAT that synergizes a bi-level optimization framework with multi-reward reinforcement learning to balance adversarial efficacy and stealthiness. We first develop a Pattern Balanced Rewarding Policy, which integrates pattern inversion rewards to invert critical patterns and distribution consistency rewards to minimize detectable shifts via unbalanced co-optimal transport. Then we employ a Constrained Group Relative Reinforcement Learning paradigm, enabling step-wise perturbations through dynamic barrier constraints and group-shared experience replay, achieving targeted pollution with minimal detectability. Extensive experiments demonstrate the effectiveness of CREAT.
A Remarkably Efficient Paradigm to Multimodal Large Language Models for Sequential Recommendation
Nov 11, 2025

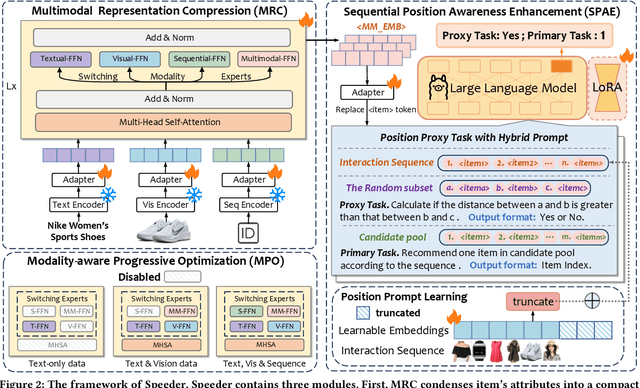
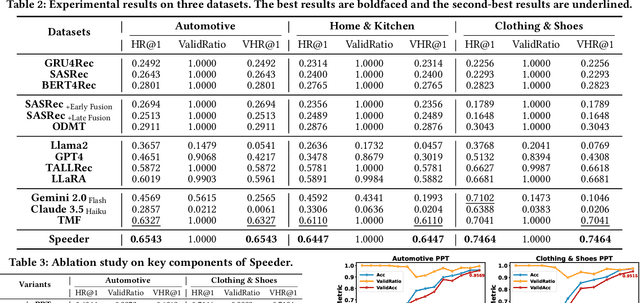
Sequential recommendations (SR) predict users' future interactions based on their historical behavior. The rise of Large Language Models (LLMs) has brought powerful generative and reasoning capabilities, significantly enhancing SR performance, while Multimodal LLMs (MLLMs) further extend this by introducing data like images and interactive relationships. However, critical issues remain, i.e., (a) Suboptimal item representations caused by lengthy and redundant descriptions, leading to inefficiencies in both training and inference; (b) Modality-related cognitive bias, as LLMs are predominantly pretrained on textual data, limiting their ability to effectively integrate and utilize non-textual modalities; (c) Weakening sequential perception in long interaction sequences, where attention mechanisms struggle to capture earlier interactions, hindering the modeling of long-range dependencies. To address these issues, we propose Speeder, an efficient MLLM-based paradigm for SR featuring three key innovations: 1) Multimodal Representation Compression (MRC), which condenses item attributes into concise yet informative tokens, reducing redundancy and computational cost; 2) Modality-aware Progressive Optimization (MPO), enabling gradual learning of multimodal representations; 3) Sequential Position Awareness Enhancement (SPAE), improving the LLM's capability to capture both relative and absolute sequential dependencies in long interaction sequences. Extensive experiments on real-world datasets demonstrate the effectiveness and efficiency of Speeder. Speeder increases training speed to 250% of the original while reducing inference time to 25% on the Amazon dataset.
Reasoning on Time-Series for Financial Technical Analysis
Nov 06, 2025While Large Language Models have been used to produce interpretable stock forecasts, they mainly focus on analyzing textual reports but not historical price data, also known as Technical Analysis. This task is challenging as it switches between domains: the stock price inputs and outputs lie in the time-series domain, while the reasoning step should be in natural language. In this work, we introduce Verbal Technical Analysis (VTA), a novel framework that combine verbal and latent reasoning to produce stock time-series forecasts that are both accurate and interpretable. To reason over time-series, we convert stock price data into textual annotations and optimize the reasoning trace using an inverse Mean Squared Error (MSE) reward objective. To produce time-series outputs from textual reasoning, we condition the outputs of a time-series backbone model on the reasoning-based attributes. Experiments on stock datasets across U.S., Chinese, and European markets show that VTA achieves state-of-the-art forecasting accuracy, while the reasoning traces also perform well on evaluation by industry experts.
SemCORE: A Semantic-Enhanced Generative Cross-Modal Retrieval Framework with MLLMs
Apr 17, 2025Cross-modal retrieval (CMR) is a fundamental task in multimedia research, focused on retrieving semantically relevant targets across different modalities. While traditional CMR methods match text and image via embedding-based similarity calculations, recent advancements in pre-trained generative models have established generative retrieval as a promising alternative. This paradigm assigns each target a unique identifier and leverages a generative model to directly predict identifiers corresponding to input queries without explicit indexing. Despite its great potential, current generative CMR approaches still face semantic information insufficiency in both identifier construction and generation processes. To address these limitations, we propose a novel unified Semantic-enhanced generative Cross-mOdal REtrieval framework (SemCORE), designed to unleash the semantic understanding capabilities in generative cross-modal retrieval task. Specifically, we first construct a Structured natural language IDentifier (SID) that effectively aligns target identifiers with generative models optimized for natural language comprehension and generation. Furthermore, we introduce a Generative Semantic Verification (GSV) strategy enabling fine-grained target discrimination. Additionally, to the best of our knowledge, SemCORE is the first framework to simultaneously consider both text-to-image and image-to-text retrieval tasks within generative cross-modal retrieval. Extensive experiments demonstrate that our framework outperforms state-of-the-art generative cross-modal retrieval methods. Notably, SemCORE achieves substantial improvements across benchmark datasets, with an average increase of 8.65 points in Recall@1 for text-to-image retrieval.
FashionDPO:Fine-tune Fashion Outfit Generation Model using Direct Preference Optimization
Apr 17, 2025Personalized outfit generation aims to construct a set of compatible and personalized fashion items as an outfit. Recently, generative AI models have received widespread attention, as they can generate fashion items for users to complete an incomplete outfit or create a complete outfit. However, they have limitations in terms of lacking diversity and relying on the supervised learning paradigm. Recognizing this gap, we propose a novel framework FashionDPO, which fine-tunes the fashion outfit generation model using direct preference optimization. This framework aims to provide a general fine-tuning approach to fashion generative models, refining a pre-trained fashion outfit generation model using automatically generated feedback, without the need to design a task-specific reward function. To make sure that the feedback is comprehensive and objective, we design a multi-expert feedback generation module which covers three evaluation perspectives, \ie quality, compatibility and personalization. Experiments on two established datasets, \ie iFashion and Polyvore-U, demonstrate the effectiveness of our framework in enhancing the model's ability to align with users' personalized preferences while adhering to fashion compatibility principles. Our code and model checkpoints are available at https://github.com/Yzcreator/FashionDPO.