 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldReel: 4D Video Generation with Consistent Geometry and Motion Modeling
Dec 08, 2025Recent video generators achieve striking photorealism, yet remain fundamentally inconsistent in 3D. We present WorldReel, a 4D video generator that is natively spatio-temporally consistent. WorldReel jointly produces RGB frames together with 4D scene representations, including pointmaps, camera trajectory, and dense flow mapping, enabling coherent geometry and appearance modeling over time. Our explicit 4D representation enforces a single underlying scene that persists across viewpoints and dynamic content, yielding videos that remain consistent even under large non-rigid motion and significant camera movement. We train WorldReel by carefully combining synthetic and real data: synthetic data providing precise 4D supervision (geometry, motion, and camera), while real videos contribute visual diversity and realism. This blend allows WorldReel to generalize to in-the-wild footage while preserving strong geometric fidelity. Extensive experiments demonstrate that WorldReel sets a new state-of-the-art for consistent video generation with dynamic scenes and moving cameras, improving metrics of geometric consistency, motion coherence, and reducing view-time artifacts over competing methods. We believe that WorldReel brings video generation closer to 4D-consistent world modeling, where agents can render, interact, and reason about scenes through a single and stable spatiotemporal representation.
FedRSU: Federated Learning for Scene Flow Estimation on Roadside Units
Jan 23, 2024Roadside unit (RSU) can significantly improve the safety and robustness of autonomous vehicles through Vehicle-to-Everything (V2X) communication. Currently, the usage of a single RSU mainly focuses on real-time inference and V2X collaboration, while neglecting the potential value of the high-quality data collected by RSU sensors. Integrating the vast amounts of data from numerous RSUs can provide a rich source of data for model training. However, the absence of ground truth annotations and the difficulty of transmitting enormous volumes of data are two inevitable barriers to fully exploiting this hidden value. In this paper, we introduce FedRSU, an innovative federated learning framework for self-supervised scene flow estimation. In FedRSU, we present a recurrent self-supervision training paradigm, where for each RSU, the scene flow prediction of points at every timestamp can be supervised by its subsequent future multi-modality observation. Another key component of FedRSU is federated learning, where multiple devices collaboratively train an ML model while keeping the training data local and private. With the power of the recurrent self-supervised learning paradigm, FL is able to leverage innumerable underutilized data from RSU. To verify the FedRSU framework, we construct a large-scale multi-modality dataset RSU-SF. The dataset consists of 17 RSU clients, covering various scenarios, modalities, and sensor settings. Based on RSU-SF, we show that FedRSU can greatly improve model performance in ITS and provide a comprehensive benchmark under diverse FL scenarios. To the best of our knowledge, we provide the first real-world LiDAR-camera multi-modal dataset and benchmark for the FL community.
Self-Supervised Bird's Eye View Motion Prediction with Cross-Modality Signals
Jan 21, 2024



Learning the dense bird's eye view (BEV) motion flow in a self-supervised manner is an emerging research for robotics and autonomous driving. Current self-supervised methods mainly rely on point correspondences between point clouds, which may introduce the problems of fake flow and inconsistency, hindering the model's ability to learn accurate and realistic motion. In this paper, we introduce a novel cross-modality self-supervised training framework that effectively addresses these issues by leveraging multi-modality data to obtain supervision signals. We design three innovative supervision signals to preserve the inherent properties of scene motion, including the masked Chamfer distance loss, the piecewise rigidity loss, and the temporal consistency loss. Through extensive experiments, we demonstrate that our proposed self-supervised framework outperforms all previous self-supervision methods for the motion prediction task.
TBP-Former: Learning Temporal Bird's-Eye-View Pyramid for Joint Perception and Prediction in Vision-Centric Autonomous Driving
Mar 22, 2023



Vision-centric joint perception and prediction (PnP) has become an emerging trend in autonomous driving research. It predicts the future states of the traffic participants in the surrounding environment from raw RGB images. However, it is still a critical challenge to synchronize features obtained at multiple camera views and timestamps due to inevitable geometric distortions and further exploit those spatial-temporal features. To address this issue, we propose a temporal bird's-eye-view pyramid transformer (TBP-Former) for vision-centric PnP, which includes two novel designs. First, a pose-synchronized BEV encoder is proposed to map raw image inputs with any camera pose at any time to a shared and synchronized BEV space for better spatial-temporal synchronization. Second, a spatial-temporal pyramid transformer is introduced to comprehensively extract multi-scale BEV features and predict future BEV states with the support of spatial-temporal priors. Extensive experiments on nuScenes dataset show that our proposed framework overall outperforms all state-of-the-art vision-based prediction methods.
Where2comm: Communication-Efficient Collaborative Perception via Spatial Confidence Maps
Sep 26, 2022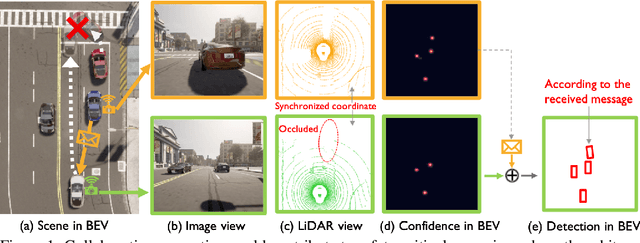

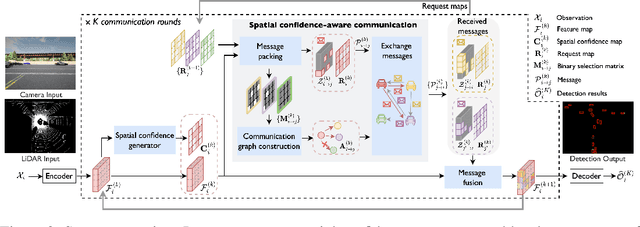
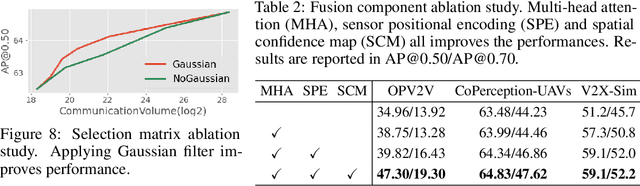
Multi-agent collaborative perception could significantly upgrade the perception performance by enabling agents to share complementary information with each other through communication. It inevitably results in a fundamental trade-off between perception performance and communication bandwidth. To tackle this bottleneck issue, we propose a spatial confidence map, which reflects the spatial heterogeneity of perceptual information. It empowers agents to only share spatially sparse, yet perceptually critical information, contributing to where to communicate. Based on this novel spatial confidence map, we propose Where2comm, a communication-efficient collaborative perception framework. Where2comm has two distinct advantages: i) it considers pragmatic compression and uses less communication to achieve higher perception performance by focusing on perceptually critical areas; and ii) it can handle varying communication bandwidth by dynamically adjusting spatial areas involved in communication. To evaluate Where2comm, we consider 3D object detection in both real-world and simulation scenarios with two modalities (camera/LiDAR) and two agent types (cars/drones) on four datasets: OPV2V, V2X-Sim, DAIR-V2X, and our original CoPerception-UAVs. Where2comm consistently outperforms previous methods; for example, it achieves more than $100,000 \times$ lower communication volume and still outperforms DiscoNet and V2X-ViT on OPV2V. Our code is available at https://github.com/MediaBrain-SJTU/where2comm.
Aerial Monocular 3D Object Detection
Aug 08, 2022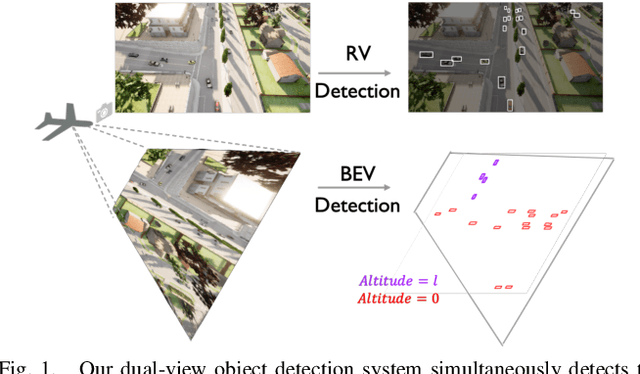

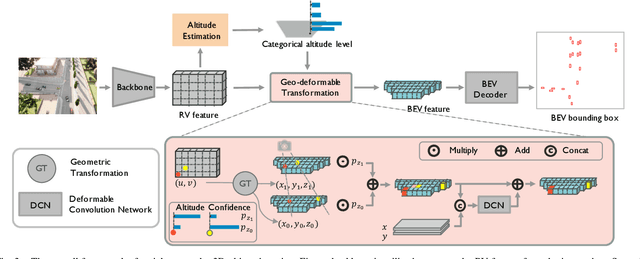
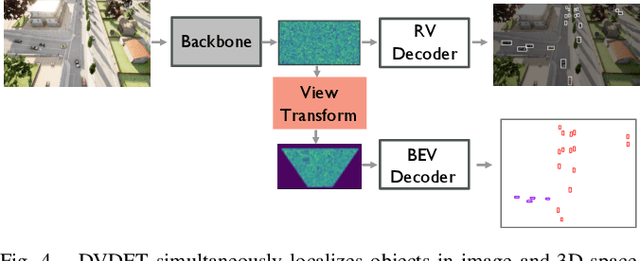
Drones equipped with cameras can significantly enhance human ability to perceive the world because of their remarkable maneuverability in 3D space. Ironically, object detection for drones has always been conducted in the 2D image space, which fundamentally limits their ability to understand 3D scenes. Furthermore, existing 3D object detection methods developed for autonomous driving cannot be directly applied to drones due to the lack of deformation modeling, which is essential for the distant aerial perspective with sensitive distortion and small objects. To fill the gap, this work proposes a dual-view detection system named DVDET to achieve aerial monocular object detection in both the 2D image space and the 3D physical space. To address the severe view deformation issue, we propose a novel trainable geo-deformable transformation module that can properly warp information from the drone's perspective to the BEV. Compared to the monocular methods for cars, our transformation includes a learnable deformable network for explicitly revising the severe deviation. To address the dataset challenge, we propose a new large-scale simulation dataset named AM3D-Sim, generated by the co-simulation of AirSIM and CARLA, and a new real-world aerial dataset named AM3D-Real, collected by DJI Matrice 300 RTK, in both datasets, high-quality annotations for 3D object detection are provided. Extensive experiments show that i) aerial monocular 3D object detection is feasible; ii) the model pre-trained on the simulation dataset benefits real-world performance, and iii) DVDET also benefits monocular 3D object detection for cars. To encourage more researchers to investigate this area, we will release the dataset and related code in https://sjtu-magic.github.io/dataset/AM3D/.