 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-Slow Efficient Training for Multimodal Large Language Models via Visual Token Pruning
Feb 03, 2026Multimodal Large Language Models (MLLMs) suffer from severe training inefficiency issue, which is associated with their massive model sizes and visual token numbers. Existing efforts in efficient training focus on reducing model sizes or trainable parameters. Inspired by the success of Visual Token Pruning (VTP) in improving inference efficiency, we are exploring another substantial research direction for efficient training by reducing visual tokens. However, applying VTP at the training stage results in a training-inference mismatch: pruning-trained models perform poorly when inferring on non-pruned full visual token sequences. To close this gap, we propose DualSpeed, a fast-slow framework for efficient training of MLLMs. The fast-mode is the primary mode, which incorporates existing VTP methods as plugins to reduce visual tokens, along with a mode isolator to isolate the model's behaviors. The slow-mode is the auxiliary mode, where the model is trained on full visual sequences to retain training-inference consistency. To boost its training, it further leverages self-distillation to learn from the sufficiently trained fast-mode. Together, DualSpeed can achieve both training efficiency and non-degraded performance. Experiments show DualSpeed accelerates the training of LLaVA-1.5 by 2.1$\times$ and LLaVA-NeXT by 4.0$\times$, retaining over 99% performance. Code: https://github.com/dingkun-zhang/DualSpeed
SwinSRGAN: Swin Transformer-based Generative Adversarial Network for High-Fidelity Speech Super-Resolution
Sep 04, 2025Speech super-resolution (SR) reconstructs high-frequency content from low-resolution speech signals. Existing systems often suffer from representation mismatch in two-stage mel-vocoder pipelines and from over-smoothing of hallucinated high-band content by CNN-only generators. Diffusion and flow models are computationally expensive, and their robustness across domains and sampling rates remains limited. We propose SwinSRGAN, an end-to-end framework operating on Modified Discrete Cosine Transform (MDCT) magnitudes. It is a Swin Transformer-based U-Net that captures long-range spectro-temporal dependencies with a hybrid adversarial scheme combines time-domain MPD/MSD discriminators with a multi-band MDCT discriminator specialized for the high-frequency band. We employs a sparse-aware regularizer on arcsinh-compressed MDCT to better preserve transient components. The system upsamples inputs at various sampling rates to 48 kHz in a single pass and operates in real time. On standard benchmarks, SwinSRGAN reduces objective error and improves ABX preference scores. In zero-shot tests on HiFi-TTS without fine-tuning, it outperforms NVSR and mdctGAN, demonstrating strong generalization across datasets
BeMERC: Behavior-Aware MLLM-based Framework for Multimodal Emotion Recognition in Conversation
Mar 31, 2025Multimodal emotion recognition in conversation (MERC), the task of identifying the emotion label for each utterance in a conversation, is vital for developing empathetic machines. Current MLLM-based MERC studies focus mainly on capturing the speaker's textual or vocal characteristics, but ignore the significance of video-derived behavior information. Different from text and audio inputs, learning videos with rich facial expression, body language and posture, provides emotion trigger signals to the models for more accurate emotion predictions. In this paper, we propose a novel behavior-aware MLLM-based framework (BeMERC) to incorporate speaker's behaviors, including subtle facial micro-expression, body language and posture, into a vanilla MLLM-based MERC model, thereby facilitating the modeling of emotional dynamics during a conversation. Furthermore, BeMERC adopts a two-stage instruction tuning strategy to extend the model to the conversations scenario for end-to-end training of a MERC predictor. Experiments demonstrate that BeMERC achieves superior performance than the state-of-the-art methods on two benchmark datasets, and also provides a detailed discussion on the significance of video-derived behavior information in MERC.
MKDTI: Predicting drug-target interactions via multiple kernel fusion on graph attention network
Jul 14, 2024



Drug-target relationships may now be predicted computationally using bioinformatics data, which is a valuable tool for understanding pharmacological effects, enhancing drug development efficiency, and advancing related research. A number of structure-based, ligand-based and network-based approaches have now emerged. Furthermore, the integration of graph attention networks with intricate drug target studies is an application area of growing interest. In our work, we formulate a model called MKDTI by extracting kernel information from various layer embeddings of a graph attention network. This combination improves the prediction ability with respect to novel drug-target relationships. We first build a drug-target heterogeneous network using heterogeneous data of drugs and targets, and then use a self-enhanced multi-head graph attention network to extract potential features in each layer. Next, we utilize embeddings of each layer to computationally extract kernel matrices and fuse multiple kernel matrices. Finally, we use a Dual Laplacian Regularized Least Squares framework to forecast novel drug-target entity connections. This prediction can be facilitated by integrating the kernel matrix associated with the drug-target. We measured our model's efficacy using AUPR and AUC. Compared to the benchmark algorithms, our model outperforms them in the prediction outcomes. In addition, we conducted an experiment on kernel selection. The results show that the multi-kernel fusion approach combined with the kernel matrix generated by the graph attention network provides complementary insights into the model. The fusion of this information helps to enhance the accuracy of the predictions.
KnobTree: Intelligent Database Parameter Configuration via Explainable Reinforcement Learning
Jun 21, 2024Databases are fundamental to contemporary information systems, yet traditional rule-based configuration methods struggle to manage the complexity of real-world applications with hundreds of tunable parameters. Deep reinforcement learning (DRL), which combines perception and decision-making, presents a potential solution for intelligent database configuration tuning. However, due to black-box property of RL-based method, the generated database tuning strategies still face the urgent problem of lack explainability. Besides, the redundant parameters in large scale database always make the strategy learning become unstable. This paper proposes KnobTree, an interpertable framework designed for the optimization of database parameter configuration. In this framework, an interpertable database tuning algorithm based on RL-based differentatial tree is proposed, which building a transparent tree-based model to generate explainable database tuning strategies. To address the problem of large-scale parameters, We also introduce a explainable method for parameter importance assessment, by utilizing Shapley Values to identify parameters that have significant impacts on database performance. Experiments conducted on MySQL and Gbase8s databases have verified exceptional transparency and interpretability of the KnobTree model. The good property makes generated strategies can offer practical guidance to algorithm designers and database administrators. Moreover, our approach also slightly outperforms the existing RL-based tuning algorithms in aspects such as throughput, latency, and processing time.
GridPE: Unifying Positional Encoding in Transformers with a Grid Cell-Inspired Framework
Jun 11, 2024



Understanding spatial location and relationships is a fundamental capability for modern artificial intelligence systems. Insights from human spatial cognition provide valuable guidance in this domain. Recent neuroscientific discoveries have highlighted the role of grid cells as a fundamental neural component for spatial representation, including distance computation, path integration, and scale discernment. In this paper, we introduce a novel positional encoding scheme inspired by Fourier analysis and the latest findings in computational neuroscience regarding grid cells. Assuming that grid cells encode spatial position through a summation of Fourier basis functions, we demonstrate the translational invariance of the grid representation during inner product calculations. Additionally, we derive an optimal grid scale ratio for multi-dimensional Euclidean spaces based on principles of biological efficiency. Utilizing these computational principles, we have developed a **Grid**-cell inspired **Positional Encoding** technique, termed **GridPE**, for encoding locations within high-dimensional spaces. We integrated GridPE into the Pyramid Vision Transformer architecture. Our theoretical analysis shows that GridPE provides a unifying framework for positional encoding in arbitrary high-dimensional spaces. Experimental results demonstrate that GridPE significantly enhances the performance of transformers, underscoring the importance of incorporating neuroscientific insights into the design of artificial intelligence systems.
Cache-Aware Reinforcement Learning in Large-Scale Recommender Systems
Apr 23, 2024Modern large-scale recommender systems are built upon computation-intensive infrastructure and usually suffer from a huge difference in traffic between peak and off-peak periods. In peak periods, it is challenging to perform real-time computation for each request due to the limited budget of computational resources. The recommendation with a cache is a solution to this problem, where a user-wise result cache is used to provide recommendations when the recommender system cannot afford a real-time computation. However, the cached recommendations are usually suboptimal compared to real-time computation, and it is challenging to determine the items in the cache for each user. In this paper, we provide a cache-aware reinforcement learning (CARL) method to jointly optimize the recommendation by real-time computation and by the cache. We formulate the problem as a Markov decision process with user states and a cache state, where the cache state represents whether the recommender system performs recommendations by real-time computation or by the cache. The computational load of the recommender system determines the cache state. We perform reinforcement learning based on such a model to improve user engagement over multiple requests. Moreover, we show that the cache will introduce a challenge called critic dependency, which deteriorates the performance of reinforcement learning. To tackle this challenge, we propose an eigenfunction learning (EL) method to learn independent critics for CARL. Experiments show that CARL can significantly improve the users' engagement when considering the result cache. CARL has been fully launched in Kwai app, serving over 100 million users.
Multi-Level Feature Aggregation and Recursive Alignment Network for Real-Time Semantic Segmentation
Feb 03, 2024Real-time semantic segmentation is a crucial research for real-world applications. However, many methods lay particular emphasis on reducing the computational complexity and model size, while largely sacrificing the accuracy. In some scenarios, such as autonomous navigation and driver assistance system, accuracy and speed are equally important. To tackle this problem, we propose a novel Multi-level Feature Aggregation and Recursive Alignment Network (MFARANet), aiming to achieve high segmentation accuracy at real-time inference speed. We employ ResNet-18 as the backbone to ensure efficiency, and propose three core components to compensate for the reduced model capacity due to the shallow backbone. Specifically, we first design Multi-level Feature Aggregation Module (MFAM) to aggregate the hierarchical features in the encoder to each scale to benefit subsequent spatial alignment and multi-scale inference. Then, we build Recursive Alignment Module (RAM) by combining the flow-based alignment module with recursive upsampling architecture for accurate and efficient spatial alignment between multi-scale score maps. Finally, the Adaptive Scores Fusion Module (ASFM) is proposed to adaptively fuse multi-scale scores so that the final prediction can favor objects of multiple scales. Comprehensive experiments on three benchmark datasets including Cityscapes, CamVid and PASCAL-Context show the effectiveness and efficiency of our method. In particular, we achieve a better balance between speed and accuracy than state-of-the-art real-time methods on Cityscapes and CamVid datasets. Code is available at: https://github.com/Yanhua-Zhang/MFARANet.
Privacy-Preserving Distributed Machine Learning Made Faster
May 12, 2022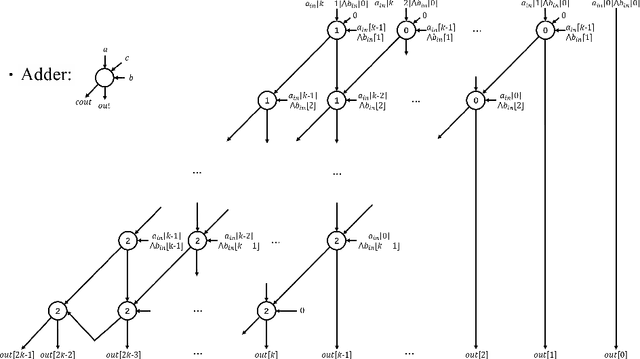
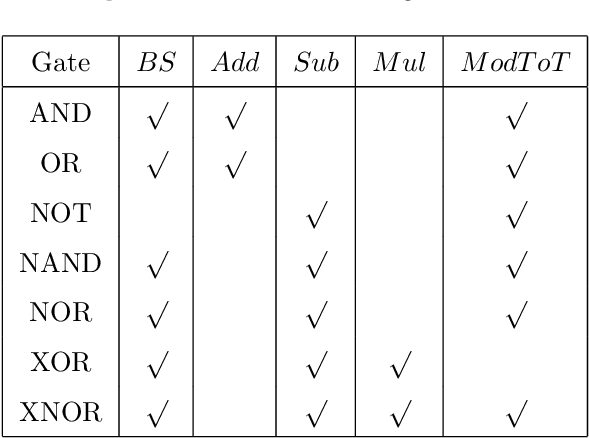
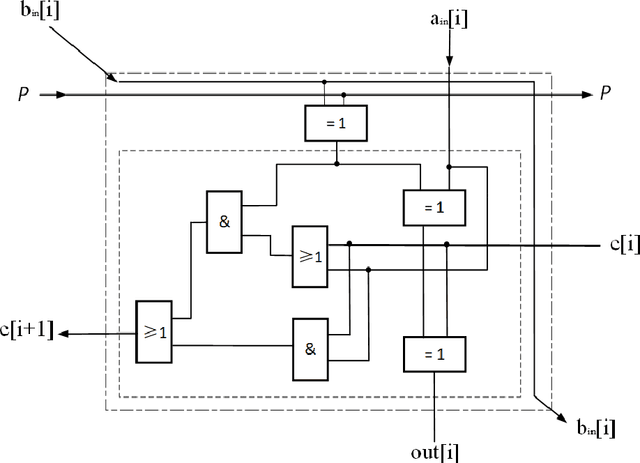
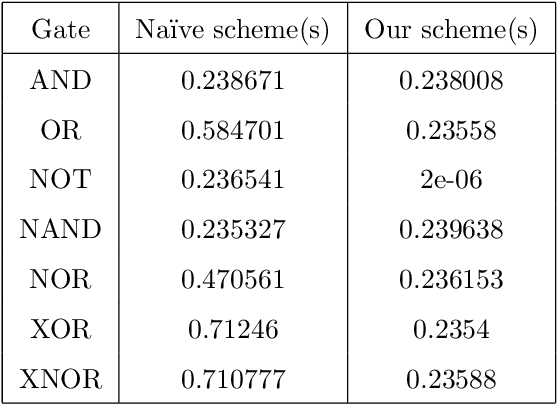
With the development of machine learning, it is difficult for a single server to process all the data. So machine learning tasks need to be spread across multiple servers, turning the centralized machine learning into a distributed one. However, privacy remains an unsolved problem in distributed machine learning. Multi-key homomorphic encryption is one of the suitable candidates to solve the problem. However, the most recent result of the Multi-key homomorphic encryption scheme (MKTFHE) only supports the NAND gate. Although it is Turing complete, it requires efficient encapsulation of the NAND gate to further support mathematical calculation. This paper designs and implements a series of operations on positive and negative integers accurately. First, we design basic bootstrapped gates with the same efficiency as that of the NAND gate. Second, we construct practical $k$-bit complement mathematical operators based on our basic binary bootstrapped gates. The constructed created can perform addition, subtraction, multiplication, and division on both positive and negative integers. Finally, we demonstrated the generality of the designed operators by achieving a distributed privacy-preserving machine learning algorithm, i.e. linear regression with two different solutions. Experiments show that the operators we designed are practical and efficient.
Multi-Graph based Multi-Scenario Recommendation in Large-scale Online Video Services
May 05, 2022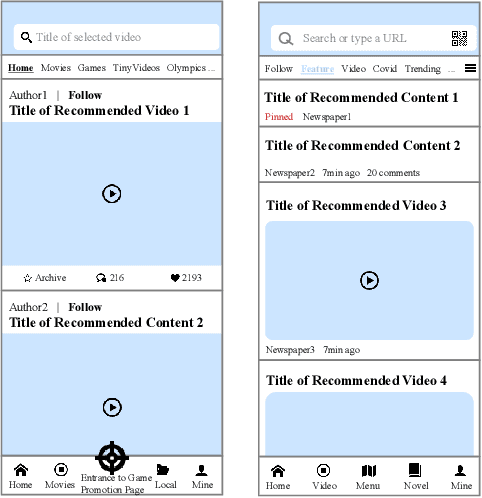

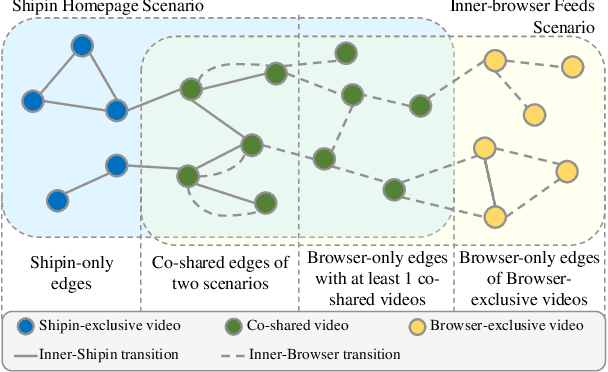
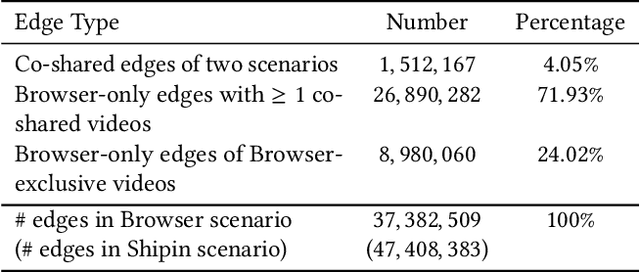
Recently, industrial recommendation services have been boosted by the continual upgrade of deep learning methods. However, they still face de-biasing challenges such as exposure bias and cold-start problem, where circulations of machine learning training on human interaction history leads algorithms to repeatedly suggest exposed items while ignoring less-active ones. Additional problems exist in multi-scenario platforms, e.g. appropriate data fusion from subsidiary scenarios, which we observe could be alleviated through graph structured data integration via message passing. In this paper, we present a multi-graph structured multi-scenario recommendation solution, which encapsulates interaction data across scenarios with multi-graph and obtains representation via graph learning. Extensive offline and online experiments on real-world datasets are conducted where the proposed method demonstrates an increase of 0.63% and 0.71% in CTR and Video Views per capita on new users over deployed set of baselines and outperforms regular method in increasing the number of outer-scenario videos by 25% and video watches by 116%, validating its superiority in activating cold videos and enriching target recommendation.