 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFakeTracer: Proactively Defending Against Face-swap DeepFakes via Implanting Traces in Training
Jul 27, 2023



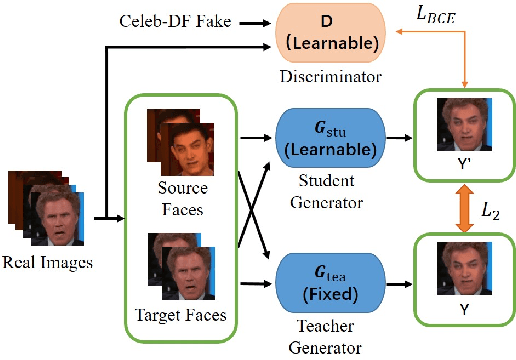
Face-swap DeepFake is an emerging AI-based face forgery technique that can replace the original face in a video with a generated face of the target identity while retaining consistent facial attributes such as expression and orientation. Due to the high privacy of faces, the misuse of this technique can raise severe social concerns, drawing tremendous attention to defend against DeepFakes recently. In this paper, we describe a new proactive defense method called FakeTracer to expose face-swap DeepFakes via implanting traces in training. Compared to general face-synthesis DeepFake, the face-swap DeepFake is more complex as it involves identity change, is subjected to the encoding-decoding process, and is trained unsupervised, increasing the difficulty of implanting traces into the training phase. To effectively defend against face-swap DeepFake, we design two types of traces, sustainable trace (STrace) and erasable trace (ETrace), to be added to training faces. During the training, these manipulated faces affect the learning of the face-swap DeepFake model, enabling it to generate faces that only contain sustainable traces. In light of these two traces, our method can effectively expose DeepFakes by identifying them. Extensive experiments are conducted on the Celeb-DF dataset, compared with recent passive and proactive defense methods, and are studied thoroughly regarding various factors, corroborating the efficacy of our method on defending against face-swap DeepFake.
Enhancing the Transferability via Feature-Momentum Adversarial Attack
Apr 22, 2022
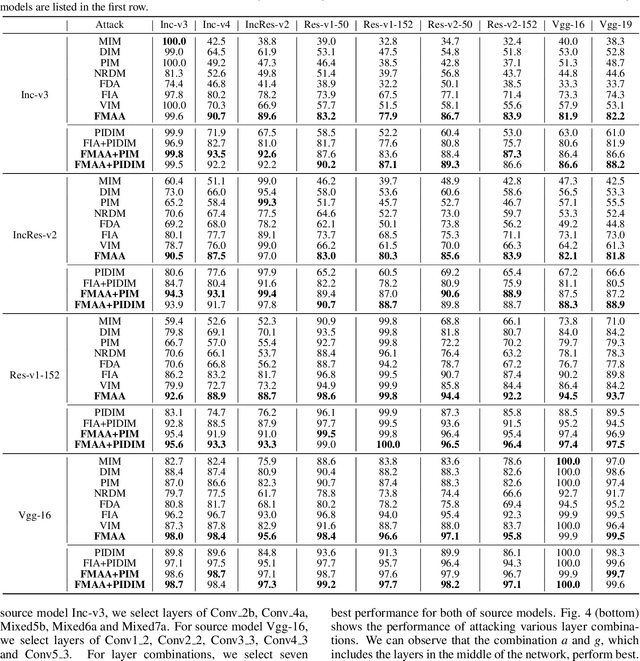
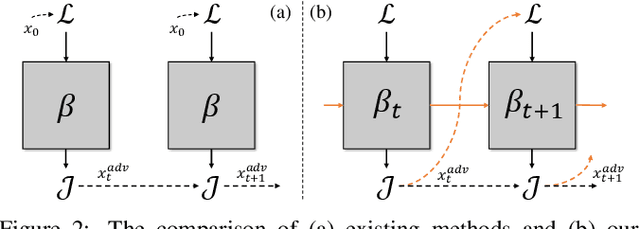
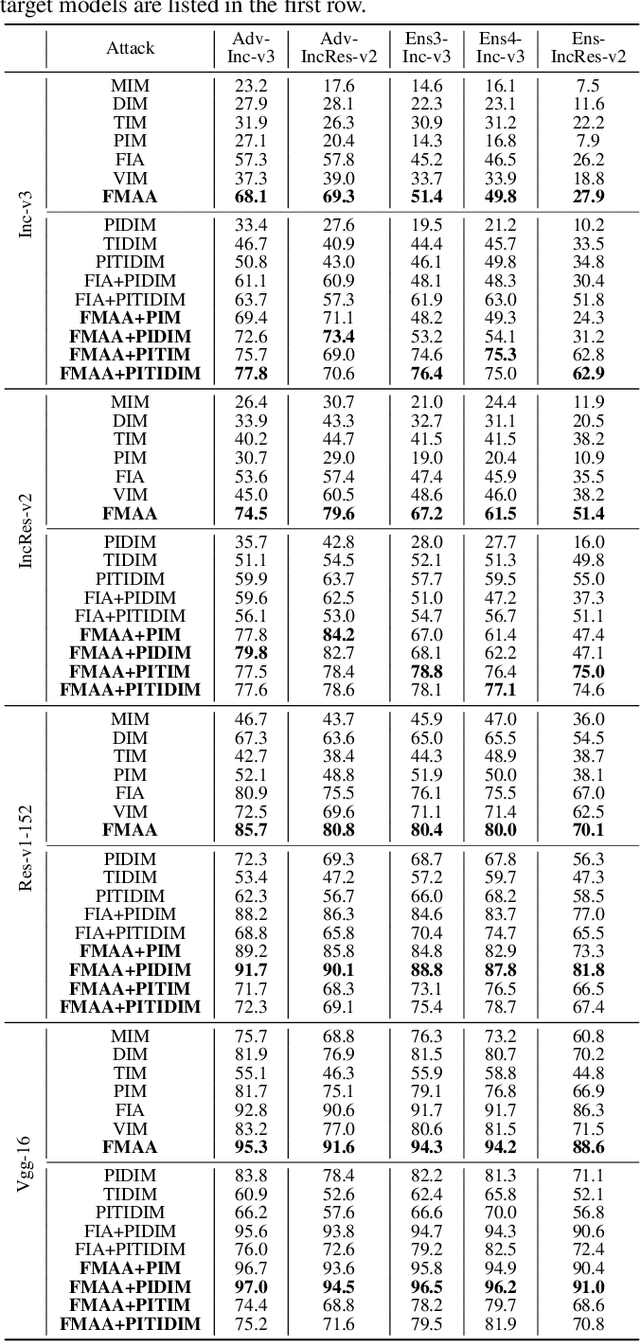
Transferable adversarial attack has drawn increasing attention due to their practical threaten to real-world applications. In particular, the feature-level adversarial attack is one recent branch that can enhance the transferability via disturbing the intermediate features. The existing methods usually create a guidance map for features, where the value indicates the importance of the corresponding feature element and then employs an iterative algorithm to disrupt the features accordingly. However, the guidance map is fixed in existing methods, which can not consistently reflect the behavior of networks as the image is changed during iteration. In this paper, we describe a new method called Feature-Momentum Adversarial Attack (FMAA) to further improve transferability. The key idea of our method is that we estimate a guidance map dynamically at each iteration using momentum to effectively disturb the category-relevant features. Extensive experiments demonstrate that our method significantly outperforms other state-of-the-art methods by a large margin on different target models.
Imperceptible Adversarial Examples for Fake Image Detection
Jun 03, 2021
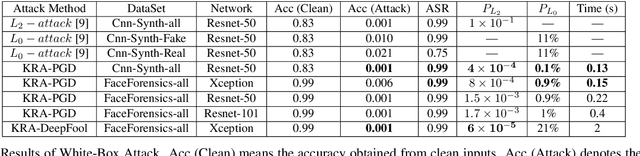

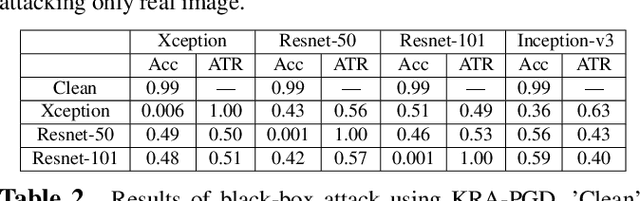
Fooling people with highly realistic fake images generated with Deepfake or GANs brings a great social disturbance to our society. Many methods have been proposed to detect fake images, but they are vulnerable to adversarial perturbations -- intentionally designed noises that can lead to the wrong prediction. Existing methods of attacking fake image detectors usually generate adversarial perturbations to perturb almost the entire image. This is redundant and increases the perceptibility of perturbations. In this paper, we propose a novel method to disrupt the fake image detection by determining key pixels to a fake image detector and attacking only the key pixels, which results in the $L_0$ and the $L_2$ norms of adversarial perturbations much less than those of existing works. Experiments on two public datasets with three fake image detectors indicate that our proposed method achieves state-of-the-art performance in both white-box and black-box attacks.
DFGC 2021: A DeepFake Game Competition
Jun 02, 2021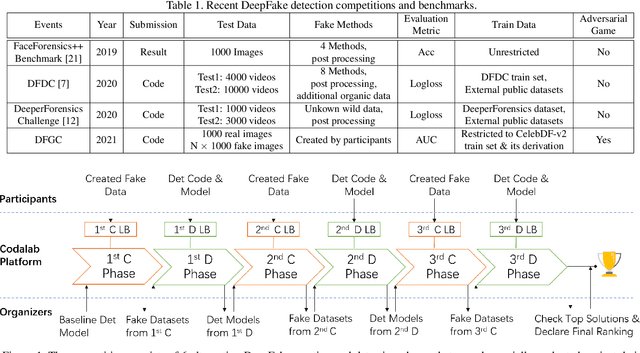
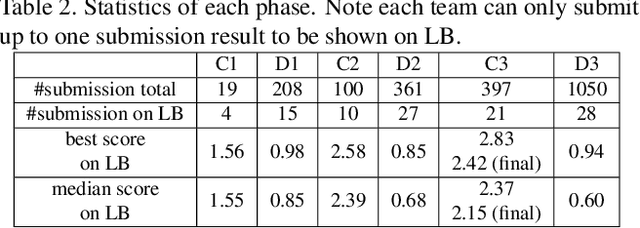
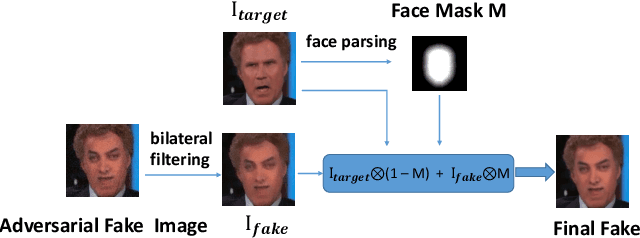
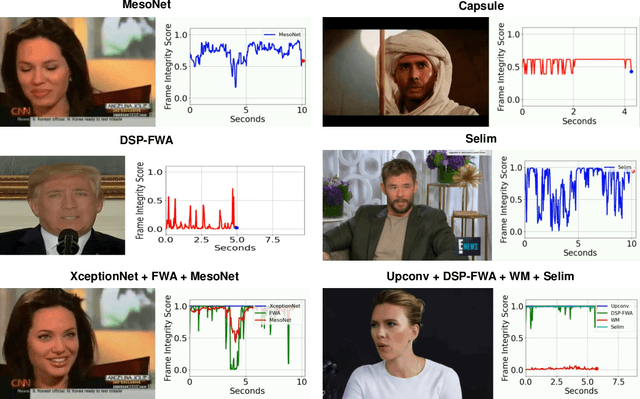
This paper presents a summary of the DFGC 2021 competition. DeepFake technology is developing fast, and realistic face-swaps are increasingly deceiving and hard to detect. At the same time, DeepFake detection methods are also improving. There is a two-party game between DeepFake creators and detectors. This competition provides a common platform for benchmarking the adversarial game between current state-of-the-art DeepFake creation and detection methods. In this paper, we present the organization, results and top solutions of this competition and also share our insights obtained during this event. We also release the DFGC-21 testing dataset collected from our participants to further benefit the research community.
DeepFake-o-meter: An Open Platform for DeepFake Detection
Mar 02, 2021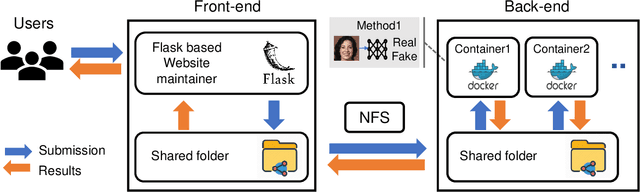

In recent years, the advent of deep learning-based techniques and the significant reduction in the cost of computation resulted in the feasibility of creating realistic videos of human faces, commonly known as DeepFakes. The availability of open-source tools to create DeepFakes poses as a threat to the trustworthiness of the online media. In this work, we develop an open-source online platform, known as DeepFake-o-meter, that integrates state-of-the-art DeepFake detection methods and provide a convenient interface for the users. We describe the design and function of DeepFake-o-meter in this work.
Landmark Breaker: Obstructing DeepFake By Disturbing Landmark Extraction
Feb 01, 2021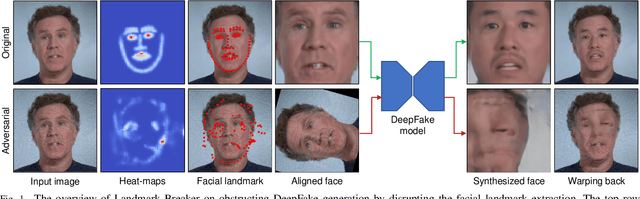

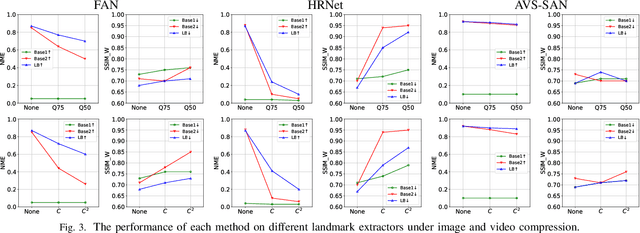
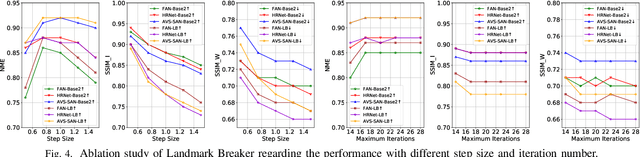
The recent development of Deep Neural Networks (DNN) has significantly increased the realism of AI-synthesized faces, with the most notable examples being the DeepFakes. The DeepFake technology can synthesize a face of target subject from a face of another subject, while retains the same face attributes. With the rapidly increased social media portals (Facebook, Instagram, etc), these realistic fake faces rapidly spread though the Internet, causing a broad negative impact to the society. In this paper, we describe Landmark Breaker, the first dedicated method to disrupt facial landmark extraction, and apply it to the obstruction of the generation of DeepFake videos.Our motivation is that disrupting the facial landmark extraction can affect the alignment of input face so as to degrade the DeepFake quality. Our method is achieved using adversarial perturbations. Compared to the detection methods that only work after DeepFake generation, Landmark Breaker goes one step ahead to prevent DeepFake generation. The experiments are conducted on three state-of-the-art facial landmark extractors using the recent Celeb-DF dataset.
LandmarkGAN: Synthesizing Faces from Landmarks
Oct 31, 2020
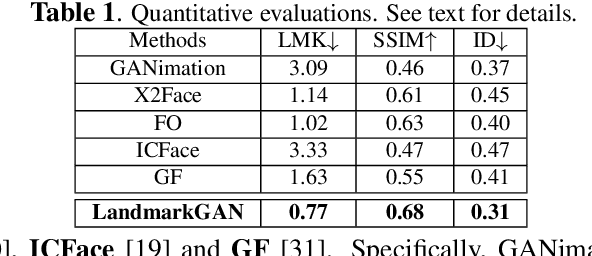
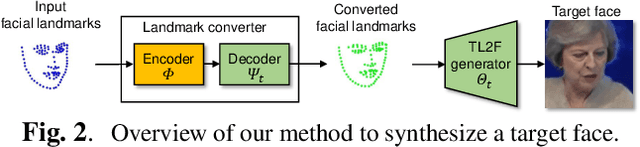
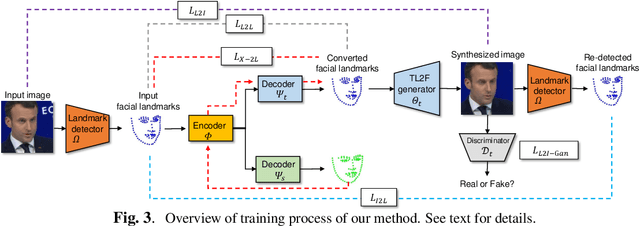
Face synthesis is an important problem in computer vision with many applications. In this work, we describe a new method, namely LandmarkGAN, to synthesize faces based on facial landmarks as input. Facial landmarks are a natural, intuitive, and effective representation for facial expressions and orientations, which are independent from the target's texture or color and background scene. Our method is able to transform a set of facial landmarks into new faces of different subjects, while retains the same facial expression and orientation. Experimental results on face synthesis and reenactments demonstrate the effectiveness of our method.
Exposing GAN-generated Faces Using Inconsistent Corneal Specular Highlights
Oct 12, 2020

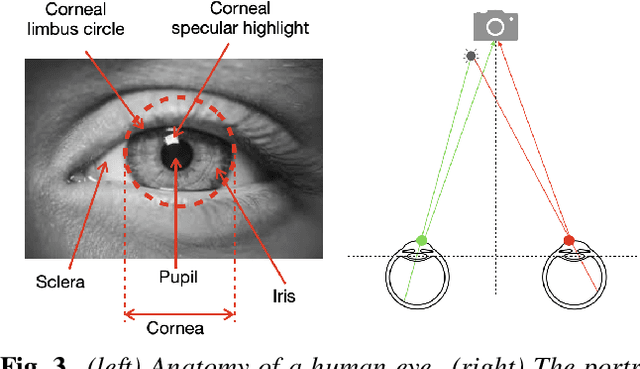
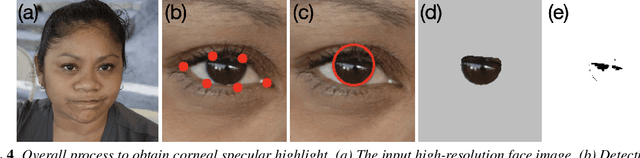
Sophisticated generative adversary network (GAN) models are now able to synthesize highly realistic human faces that are difficult to discern from real ones visually. In this work, we show that GAN synthesized faces can be exposed with the inconsistent corneal specular highlights between two eyes. The inconsistency is caused by the lack of physical/physiological constraints in the GAN models. We show that such artifacts exist widely in high-quality GAN synthesized faces and further describe an automatic method to extract and compare corneal specular highlights from two eyes. Qualitative and quantitative evaluations of our method suggest its simplicity and effectiveness in distinguishing GAN synthesized faces.
Fast Portrait Segmentation with extremely light-weight network
Nov 03, 2019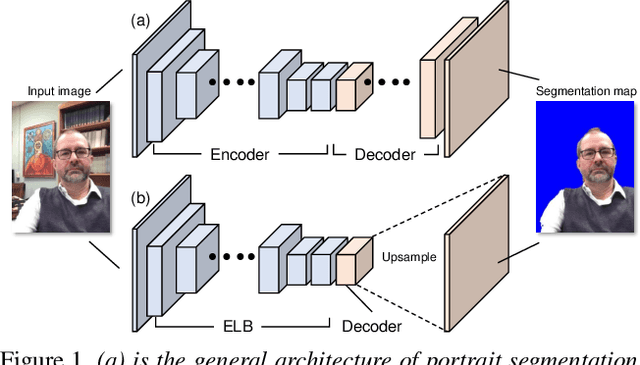
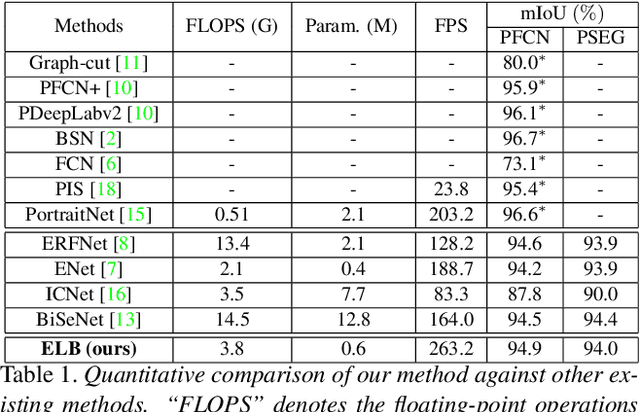
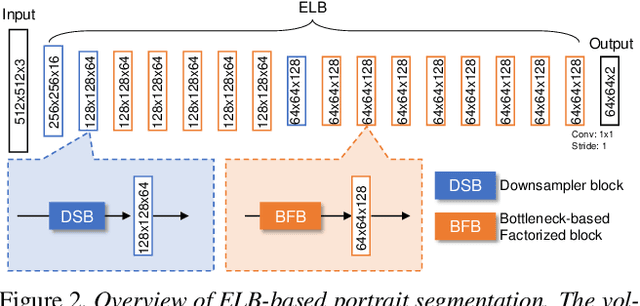
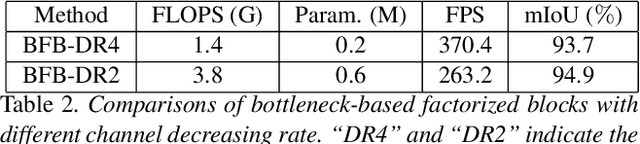
In this paper, we describe a fast and light-weight portrait segmentation method based on a new {\em extremely light-weight backbone} (ELB) architecture. The core element of ELB is a {\em bottleneck-based factorized block} (BFB) that has much fewer parameters than existing alternatives while keeping good learning capacity. Consequently, the ELB-based portrait segmentation method can run faster (263.2FPS) than the existing methods yet retaining the competitive accuracy performance with state-of-the-arts. Experiments conducted on two benchmark datasets demonstrate the effectiveness and efficiency of our method.
Celeb-DF: A New Dataset for DeepFake Forensics
Oct 02, 2019
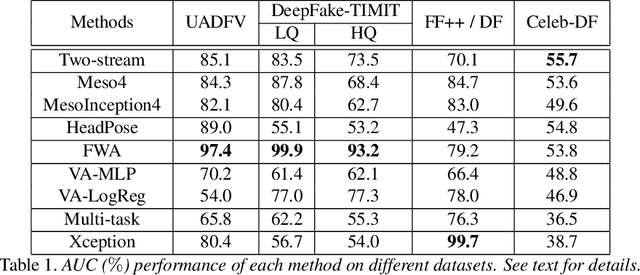


AI-synthesized face swapping videos, commonly known as the DeepFakes, have become an emerging problem recently. Correspondingly, there is an increasing interest in developing algorithms that can detect them. However, existing dataset of DeepFake videos suffer from low visual quality and abundant artifacts that do not reflect the reality of DeepFake videos circulated on the Internet. In this work, we present a new DeepFake dataset, Celeb-DF, for the development and evaluation of DeepFake detection algorithms. The Celeb-DF dataset is generated using a refined synthesis algorithm that reduces the visual artifacts observed in existing datasets. Based on the Celeb-DF dataset, we also benchmark existing DeepFake detection algorithms.