 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoCodeBench: Large Language Models are Automatic Code Benchmark Generators
Aug 12, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains, with code generation emerging as a key area of focus. While numerous benchmarks have been proposed to evaluate their code generation abilities, these benchmarks face several critical limitations. First, they often rely on manual annotations, which are time-consuming and difficult to scale across different programming languages and problem complexities. Second, most existing benchmarks focus primarily on Python, while the few multilingual benchmarks suffer from limited difficulty and uneven language distribution. To address these challenges, we propose AutoCodeGen, an automated method for generating high-difficulty multilingual code generation datasets without manual annotations. AutoCodeGen ensures the correctness and completeness of test cases by generating test inputs with LLMs and obtaining test outputs through a multilingual sandbox, while achieving high data quality through reverse-order problem generation and multiple filtering steps. Using this novel method, we introduce AutoCodeBench, a large-scale code generation benchmark comprising 3,920 problems evenly distributed across 20 programming languages. It is specifically designed to evaluate LLMs on challenging, diverse, and practical multilingual tasks. We evaluate over 30 leading open-source and proprietary LLMs on AutoCodeBench and its simplified version AutoCodeBench-Lite. The results show that even the most advanced LLMs struggle with the complexity, diversity, and multilingual nature of these tasks. Besides, we introduce AutoCodeBench-Complete, specifically designed for base models to assess their few-shot code generation capabilities. We hope the AutoCodeBench series will serve as a valuable resource and inspire the community to focus on more challenging and practical multilingual code generation scenarios.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Catching Spinning Table Tennis Balls in Simulation with End-to-End Curriculum Reinforcement Learning
Mar 03, 2025



The game of table tennis is renowned for its extremely high spin rate, but most table tennis robots today struggle to handle balls with such rapid spin. To address this issue, we have contributed a series of methods, including: 1. Curriculum Reinforcement Learning (RL): This method helps the table tennis robot learn to play table tennis progressively from easy to difficult tasks. 2. Analysis of Spinning Table Tennis Ball Collisions: We have conducted a physics-based analysis to generate more realistic trajectories of spinning table tennis balls after collision. 3. Definition of Trajectory States: The definition of trajectory states aids in setting up the reward function. 4. Selection of Valid Rally Trajectories: We have introduced a valid rally trajectory selection scheme to ensure that the robot's training is not influenced by abnormal trajectories. 5. Reality-to-Simulation (Real2Sim) Transfer: This scheme is employed to validate the trained robot's ability to handle spinning balls in real-world scenarios. With Real2Sim, the deployment costs for robotic reinforcement learning can be further reduced. Moreover, the trajectory-state-based reward function is not limited to table tennis robots; it can be generalized to a wide range of cyclical tasks. To validate our robot's ability to handle spinning balls, the Real2Sim experiments were conducted. For the specific video link of the experiment, please refer to the supplementary materials.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
BLADE: Benchmarking Language Model Agents for Data-Driven Science
Aug 20, 2024



Data-driven scientific discovery requires the iterative integration of scientific domain knowledge, statistical expertise, and an understanding of data semantics to make nuanced analytical decisions, e.g., about which variables, transformations, and statistical models to consider. LM-based agents equipped with planning, memory, and code execution capabilities have the potential to support data-driven science. However, evaluating agents on such open-ended tasks is challenging due to multiple valid approaches, partially correct steps, and different ways to express the same decisions. To address these challenges, we present BLADE, a benchmark to automatically evaluate agents' multifaceted approaches to open-ended research questions. BLADE consists of 12 datasets and research questions drawn from existing scientific literature, with ground truth collected from independent analyses by expert data scientists and researchers. To automatically evaluate agent responses, we developed corresponding computational methods to match different representations of analyses to this ground truth. Though language models possess considerable world knowledge, our evaluation shows that they are often limited to basic analyses. However, agents capable of interacting with the underlying data demonstrate improved, but still non-optimal, diversity in their analytical decision making. Our work enables the evaluation of agents for data-driven science and provides researchers deeper insights into agents' analysis approaches.
Reflecting the Male Gaze: Quantifying Female Objectification in 19th and 20th Century Novels
Mar 25, 2024Inspired by the concept of the male gaze (Mulvey, 1975) in literature and media studies, this paper proposes a framework for analyzing gender bias in terms of female objectification: the extent to which a text portrays female individuals as objects of visual pleasure. Our framework measures female objectification along two axes. First, we compute an agency bias score that indicates whether male entities are more likely to appear in the text as grammatical agents than female entities. Next, by analyzing the word embedding space induced by a text (Caliskan et al., 2017), we compute an appearance bias score that indicates whether female entities are more closely associated with appearance-related words than male entities. Applying our framework to 19th and 20th century novels reveals evidence of female objectification in literature: we find that novels written from a male perspective systematically objectify female characters, while novels written from a female perspective do not exhibit statistically significant objectification of any gender.
Towards Understanding Underwater Weather Events in Rivers Using Autonomous Surface Vehicles
Dec 21, 2023



Climate change has increased the frequency and severity of extreme weather events such as hurricanes and winter storms. The complex interplay of floods with tides, runoff, and sediment creates additional hazards -- including erosion and the undermining of urban infrastructure -- consequently impacting the health of our rivers and ecosystems. Observations of these underwater phenomena are rare, because satellites and sensors mounted on aerial vehicles cannot penetrate the murky waters. Autonomous Surface Vehicles (ASVs) provides a means to track and map these complex and dynamic underwater phenomena. This work highlights preliminary results of high-resolution data gathering with ASVs, equipped with a suite of sensors capable of measuring physical and chemical parameters of the river. Measurements were acquired along the lower Schuylkill River in the Philadelphia area at high-tide and low-tide conditions. The data will be leveraged to improve our understanding of changes in bathymetry due to floods; the dynamics of mixing and stagnation zones and their impact on water quality; and the dynamics of suspension and resuspension of fine sediment. The data will also provide insight into the development of adaptive sampling strategies for ASVs that can maximize the information gain for future field experiments.
Constrained Sequence-to-Tree Generation for Hierarchical Text Classification
Apr 02, 2022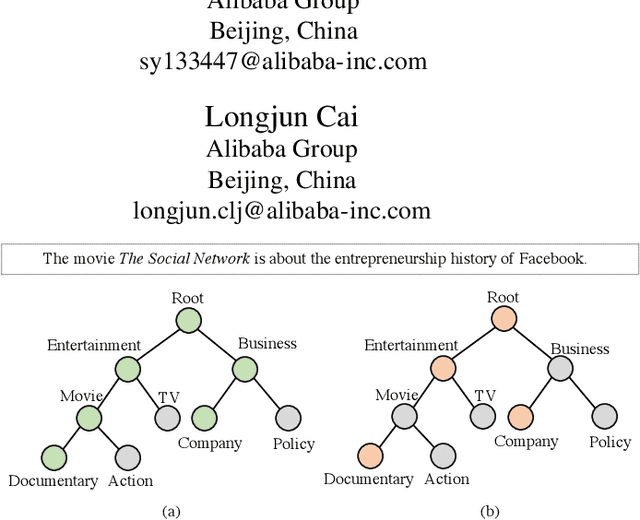
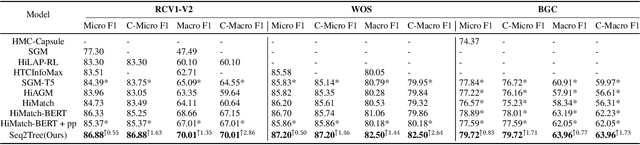
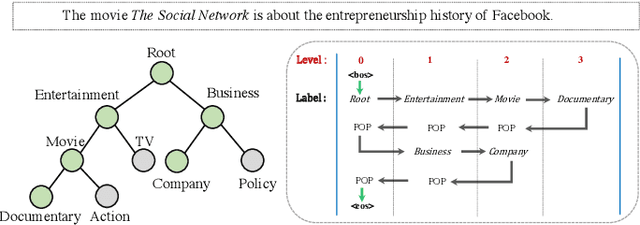
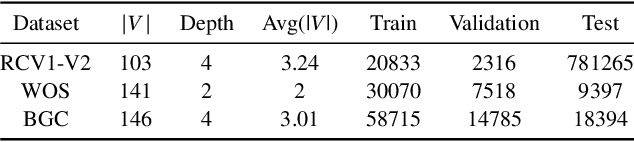
Hierarchical Text Classification (HTC) is a challenging task where a document can be assigned to multiple hierarchically structured categories within a taxonomy. The majority of prior studies consider HTC as a flat multi-label classification problem, which inevitably leads to "label inconsistency" problem. In this paper, we formulate HTC as a sequence generation task and introduce a sequence-to-tree framework (Seq2Tree) for modeling the hierarchical label structure. Moreover, we design a constrained decoding strategy with dynamic vocabulary to secure the label consistency of the results. Compared with previous works, the proposed approach achieves significant and consistent improvements on three benchmark datasets.
Hybrid Curriculum Learning for Emotion Recognition in Conversation
Dec 22, 2021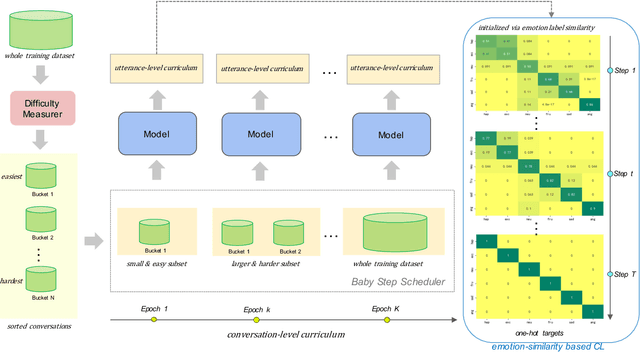
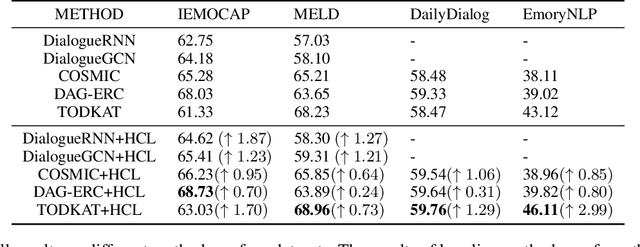
Emotion recognition in conversation (ERC) aims to detect the emotion label for each utterance. Motivated by recent studies which have proven that feeding training examples in a meaningful order rather than considering them randomly can boost the performance of models, we propose an ERC-oriented hybrid curriculum learning framework. Our framework consists of two curricula: (1) conversation-level curriculum (CC); and (2) utterance-level curriculum (UC). In CC, we construct a difficulty measurer based on "emotion shift" frequency within a conversation, then the conversations are scheduled in an "easy to hard" schema according to the difficulty score returned by the difficulty measurer. For UC, it is implemented from an emotion-similarity perspective, which progressively strengthens the model's ability in identifying the confusing emotions. With the proposed model-agnostic hybrid curriculum learning strategy, we observe significant performance boosts over a wide range of existing ERC models and we are able to achieve new state-of-the-art results on four public ERC datasets.
A Joint Training Dual-MRC Framework for Aspect Based Sentiment Analysis
Jan 04, 2021
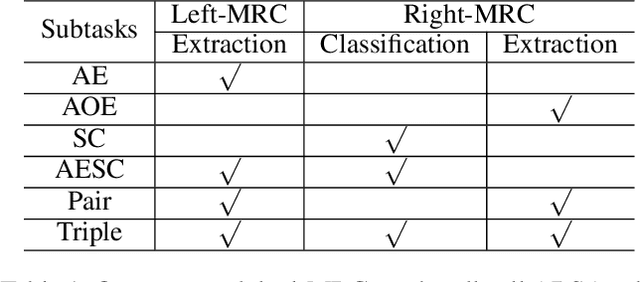
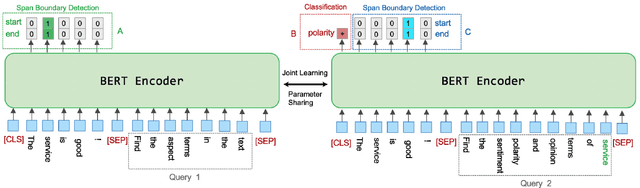

Aspect based sentiment analysis (ABSA) involves three fundamental subtasks: aspect term extraction, opinion term extraction, and aspect-level sentiment classification. Early works only focused on solving one of these subtasks individually. Some recent work focused on solving a combination of two subtasks, e.g., extracting aspect terms along with sentiment polarities or extracting the aspect and opinion terms pair-wisely. More recently, the triple extraction task has been proposed, i.e., extracting the (aspect term, opinion term, sentiment polarity) triples from a sentence. However, previous approaches fail to solve all subtasks in a unified end-to-end framework. In this paper, we propose a complete solution for ABSA. We construct two machine reading comprehension (MRC) problems, and solve all subtasks by joint training two BERT-MRC models with parameters sharing. We conduct experiments on these subtasks and results on several benchmark datasets demonstrate the effectiveness of our proposed framework, which significantly outperforms existing state-of-the-art methods.