 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeA: Semantic Adversarial Augmentation for Last Layer Features from Unsupervised Representation Learning
Aug 23, 2024Deep features extracted from certain layers of a pre-trained deep model show superior performance over the conventional hand-crafted features. Compared with fine-tuning or linear probing that can explore diverse augmentations, \eg, random crop/flipping, in the original input space, the appropriate augmentations for learning with fixed deep features are more challenging and have been less investigated, which degenerates the performance. To unleash the potential of fixed deep features, we propose a novel semantic adversarial augmentation (SeA) in the feature space for optimization. Concretely, the adversarial direction implied by the gradient will be projected to a subspace spanned by other examples to preserve the semantic information. Then, deep features will be perturbed with the semantic direction, and augmented features will be applied to learn the classifier. Experiments are conducted on $11$ benchmark downstream classification tasks with $4$ popular pre-trained models. Our method is $2\%$ better than the deep features without SeA on average. Moreover, compared to the expensive fine-tuning that is expected to give good performance, SeA shows a comparable performance on $6$ out of $11$ tasks, demonstrating the effectiveness of our proposal in addition to its efficiency. Code is available at \url{https://github.com/idstcv/SeA}.
Intra-Modal Proxy Learning for Zero-Shot Visual Categorization with CLIP
Oct 30, 2023



Vision-language pre-training methods, e.g., CLIP, demonstrate an impressive zero-shot performance on visual categorizations with the class proxy from the text embedding of the class name. However, the modality gap between the text and vision space can result in a sub-optimal performance. We theoretically show that the gap cannot be reduced sufficiently by minimizing the contrastive loss in CLIP and the optimal proxy for vision tasks may reside only in the vision space. Therefore, given unlabeled target vision data, we propose to learn the vision proxy directly with the help from the text proxy for zero-shot transfer. Moreover, according to our theoretical analysis, strategies are developed to further refine the pseudo label obtained by the text proxy to facilitate the intra-modal proxy learning (InMaP) for vision. Experiments on extensive downstream tasks confirm the effectiveness and efficiency of our proposal. Concretely, InMaP can obtain the vision proxy within one minute on a single GPU while improving the zero-shot accuracy from $77.02\%$ to $80.21\%$ on ImageNet with ViT-L/14@336 pre-trained by CLIP. Code is available at \url{https://github.com/idstcv/InMaP}.
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Apr 27, 2023



Large language models (LLMs) have demonstrated impressive zero-shot abilities on a variety of open-ended tasks, while recent research has also explored the use of LLMs for multi-modal generation. In this study, we introduce mPLUG-Owl, a novel training paradigm that equips LLMs with multi-modal abilities through modularized learning of foundation LLM, a visual knowledge module, and a visual abstractor module. This approach can support multiple modalities and facilitate diverse unimodal and multimodal abilities through modality collaboration. The training paradigm of mPLUG-Owl involves a two-stage method for aligning image and text, which learns visual knowledge with the assistance of LLM while maintaining and even improving the generation abilities of LLM. In the first stage, the visual knowledge module and abstractor module are trained with a frozen LLM module to align the image and text. In the second stage, language-only and multi-modal supervised datasets are used to jointly fine-tune a low-rank adaption (LoRA) module on LLM and the abstractor module by freezing the visual knowledge module. We carefully build a visually-related instruction evaluation set OwlEval. Experimental results show that our model outperforms existing multi-modal models, demonstrating mPLUG-Owl's impressive instruction and visual understanding ability, multi-turn conversation ability, and knowledge reasoning ability. Besides, we observe some unexpected and exciting abilities such as multi-image correlation and scene text understanding, which makes it possible to leverage it for harder real scenarios, such as vision-only document comprehension. Our code, pre-trained model, instruction-tuned models, and evaluation set are available at https://github.com/X-PLUG/mPLUG-Owl. The online demo is available at https://www.modelscope.cn/studios/damo/mPLUG-Owl.
Improved Visual Fine-tuning with Natural Language Supervision
Apr 04, 2023



Fine-tuning a pre-trained model can leverage the semantic information from large-scale pre-training data and mitigate the over-fitting problem on downstream tasks with limited training examples. While the problem of catastrophic forgetting in backbone has been extensively studied, the potential bias existing in a pre-trained model due to the corresponding pre-training task and data, attracts less attention. In this work, we investigate this problem by demonstrating that the obtained classifier after fine-tuning will be close to that induced by the pre-trained model. To reduce the bias in the classifier effectively, we introduce a reference distribution obtained from a fixed text classifier, which can help regularize the learned vision classifier. The proposed method, Text Supervised fine-tuning (TeS), is evaluated with diverse pre-trained vision models including ResNet and ViT, and text encoders including BERT and CLIP, on 11 downstream tasks. The consistent improvement with a clear margin over distinct scenarios confirms the effectiveness of our proposal.
mPLUG-2: A Modularized Multi-modal Foundation Model Across Text, Image and Video
Feb 01, 2023



Recent years have witnessed a big convergence of language, vision, and multi-modal pretraining. In this work, we present mPLUG-2, a new unified paradigm with modularized design for multi-modal pretraining, which can benefit from modality collaboration while addressing the problem of modality entanglement. In contrast to predominant paradigms of solely relying on sequence-to-sequence generation or encoder-based instance discrimination, mPLUG-2 introduces a multi-module composition network by sharing common universal modules for modality collaboration and disentangling different modality modules to deal with modality entanglement. It is flexible to select different modules for different understanding and generation tasks across all modalities including text, image, and video. Empirical study shows that mPLUG-2 achieves state-of-the-art or competitive results on a broad range of over 30 downstream tasks, spanning multi-modal tasks of image-text and video-text understanding and generation, and uni-modal tasks of text-only, image-only, and video-only understanding. Notably, mPLUG-2 shows new state-of-the-art results of 48.0 top-1 accuracy and 80.3 CIDEr on the challenging MSRVTT video QA and video caption tasks with a far smaller model size and data scale. It also demonstrates strong zero-shot transferability on vision-language and video-language tasks. Code and models will be released in https://github.com/alibaba/AliceMind.
An Empirical Study on Distribution Shift Robustness From the Perspective of Pre-Training and Data Augmentation
May 25, 2022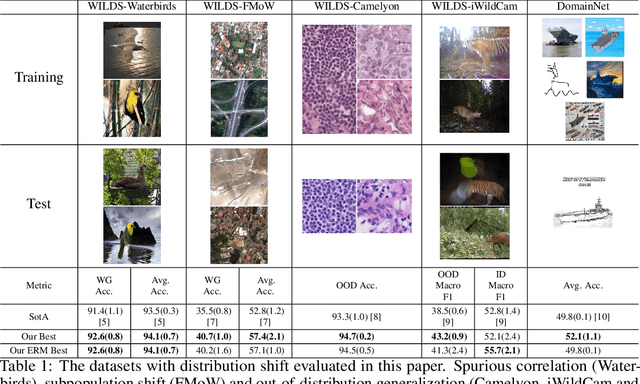
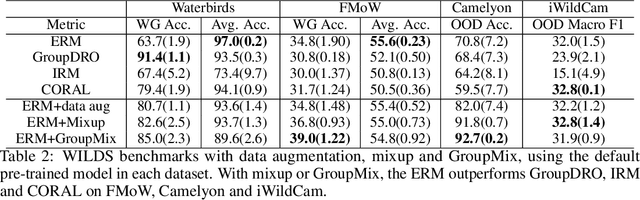
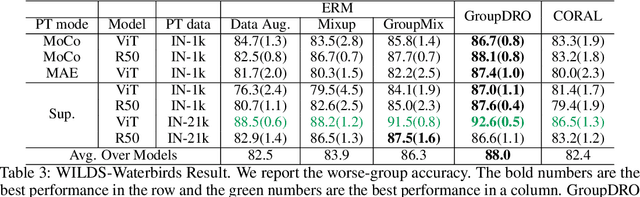
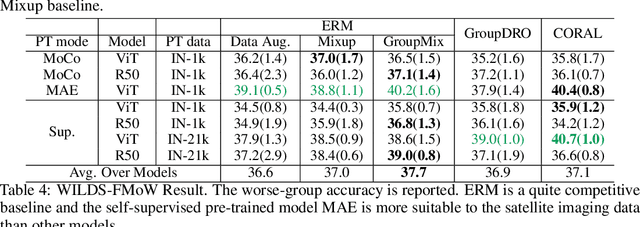
The performance of machine learning models under distribution shift has been the focus of the community in recent years. Most of current methods have been proposed to improve the robustness to distribution shift from the algorithmic perspective, i.e., designing better training algorithms to help the generalization in shifted test distributions. This paper studies the distribution shift problem from the perspective of pre-training and data augmentation, two important factors in the practice of deep learning that have not been systematically investigated by existing work. By evaluating seven pre-trained models, including ResNets and ViT's with self-supervision and supervision mode, on five important distribution-shift datasets, from WILDS and DomainBed benchmarks, with five different learning algorithms, we provide the first comprehensive empirical study focusing on pre-training and data augmentation. With our empirical result obtained from 1,330 models, we provide the following main observations: 1) ERM combined with data augmentation can achieve state-of-the-art performance if we choose a proper pre-trained model respecting the data property; 2) specialized algorithms further improve the robustness on top of ERM when handling a specific type of distribution shift, e.g., GroupDRO for spurious correlation and CORAL for large-scale out-of-distribution data; 3) Comparing different pre-training modes, architectures and data sizes, we provide novel observations about pre-training on distribution shift, which sheds light on designing or selecting pre-training strategy for different kinds of distribution shifts. In summary, our empirical study provides a comprehensive baseline for a wide range of pre-training models fine-tuned with data augmentation, which potentially inspires research exploiting the power of pre-training and data augmentation in the future of distribution shift study.
Improved Fine-tuning by Leveraging Pre-training Data: Theory and Practice
Nov 24, 2021
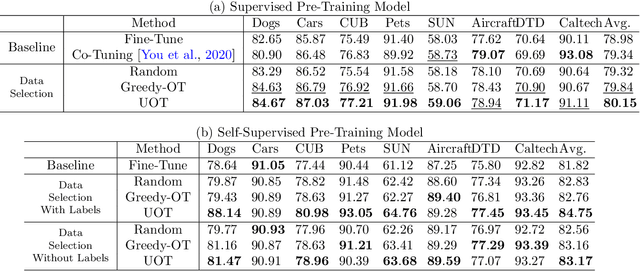
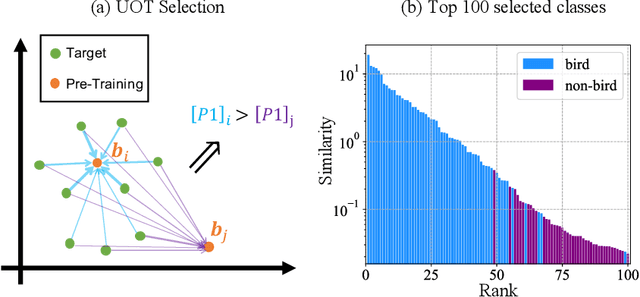

As a dominant paradigm, fine-tuning a pre-trained model on the target data is widely used in many deep learning applications, especially for small data sets. However, recent studies have empirically shown that training from scratch has the final performance that is no worse than this pre-training strategy once the number of training iterations is increased in some vision tasks. In this work, we revisit this phenomenon from the perspective of generalization analysis which is popular in learning theory. Our result reveals that the final prediction precision may have a weak dependency on the pre-trained model especially in the case of large training iterations. The observation inspires us to leverage pre-training data for fine-tuning, since this data is also available for fine-tuning. The generalization result of using pre-training data shows that the final performance on a target task can be improved when the appropriate pre-training data is included in fine-tuning. With the insight of the theoretical finding, we propose a novel selection strategy to select a subset from pre-training data to help improve the generalization on the target task. Extensive experimental results for image classification tasks on 8 benchmark data sets verify the effectiveness of the proposed data selection based fine-tuning pipeline.
Unsupervised Visual Representation Learning by Online Constrained K-Means
May 24, 2021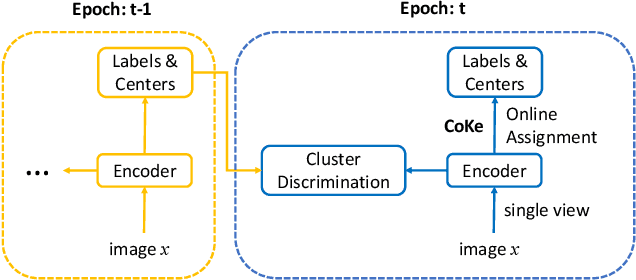
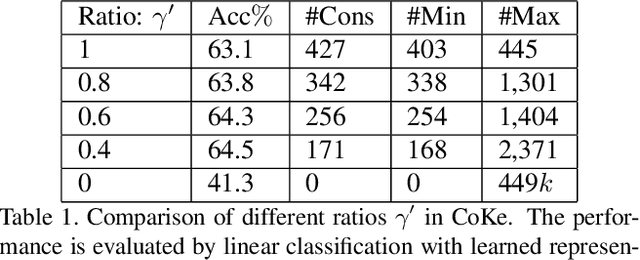
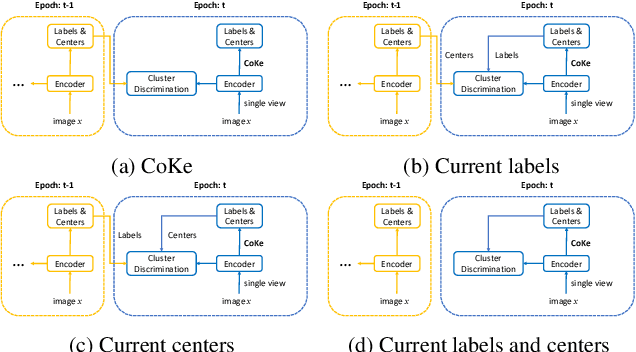
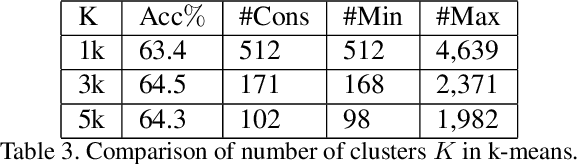
Cluster discrimination is an effective pretext task for unsupervised representation learning, which often consists of two phases: clustering and discrimination. Clustering is to assign each instance a pseudo label that will be used to learn representations in discrimination. The main challenge resides in clustering since many prevalent clustering methods (e.g., k-means) have to run in a batch mode that goes multiple iterations over the whole data. Recently, a balanced online clustering method, i.e., SwAV, is proposed for representation learning. However, the assignment is optimized within only a small subset of data, which can be suboptimal. To address these challenges, we first investigate the objective of clustering-based representation learning from the perspective of distance metric learning. Based on this, we propose a novel clustering-based pretext task with online \textbf{Co}nstrained \textbf{K}-m\textbf{e}ans (\textbf{CoKe}) to learn representations and relations between instances simultaneously. Compared with the balanced clustering that each cluster has exactly the same size, we only constrain the minimum size of clusters to flexibly capture the inherent data structure. More importantly, our online assignment method has a theoretical guarantee to approach the global optimum. Finally, two variance reduction strategies are proposed to make the clustering robust for different augmentations. Without keeping representations of instances, the data is accessed in an online mode in CoKe while a single view of instances at each iteration is sufficient to demonstrate a better performance than contrastive learning methods relying on two views. Extensive experiments on ImageNet verify the efficacy of our proposal. Code will be released.
Towards Understanding Label Smoothing
Jun 20, 2020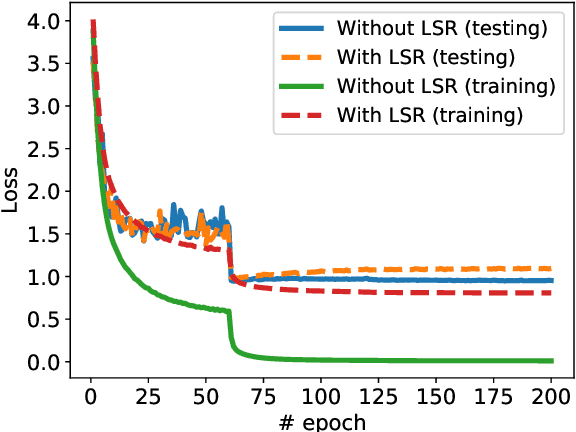

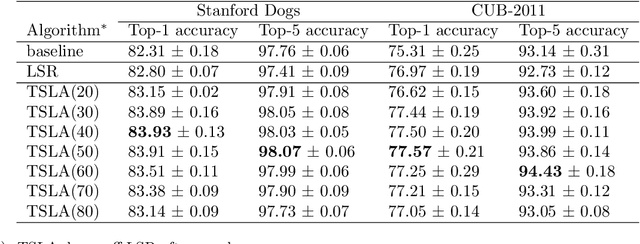
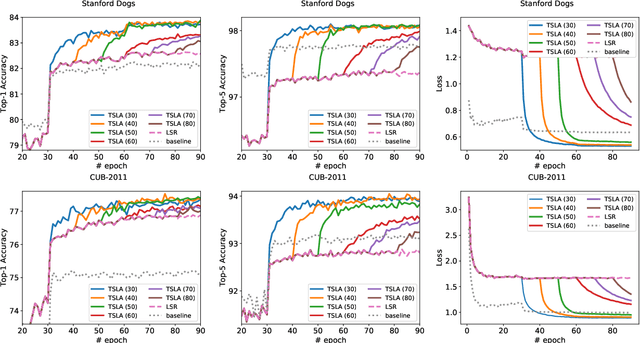
Label smoothing regularization (LSR) has a great success in training deep neural networks by stochastic algorithms such as stochastic gradient descent and its variants. However, the theoretical understanding of its power from the view of optimization is still rare. This study opens the door to a deep understanding of LSR by initiating the analysis. In this paper, we analyze the convergence behaviors of stochastic gradient descent with LSR for solving non-convex problems and show that an appropriate LSR can help to speed up the convergence by reducing the variance of labels. More interestingly, we proposed a simple and efficient strategy, namely Two-Stage LAbel smoothing algorithm (TSLA), that uses LSR in the early training epochs and drops it off in the later training epochs. We observe from the improved convergence result of TSLA that it benefits from LSR in the first stage and essentially converges faster in the second stage. To the best of our knowledge, this is the first work for understanding the power of LSR via establishing convergence complexity of stochastic methods with LSR in non-convex optimization. We empirically demonstrate the effectiveness of the proposed method in comparison with baselines on training ResNet models over public data sets.
Representation Learning with Fine-grained Patterns
May 19, 2020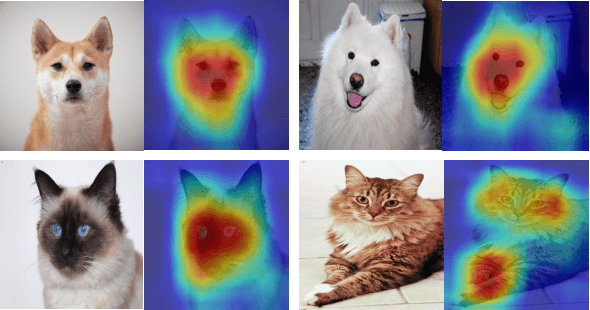
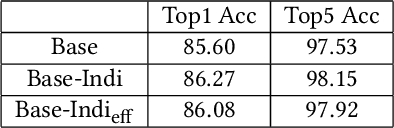
With the development of computational power and techniques for data collection, deep learning demonstrates a superior performance over many existing algorithms on benchmark data sets. Many efforts have been devoted to studying the mechanism of deep learning. One of important observations is that deep learning can learn the discriminative patterns from raw materials directly in a task-dependent manner. It makes the patterns obtained by deep learning outperform hand-crafted features significantly. However, those patterns can be misled by the training task when the target task is different. In this work, we investigate a prevalent problem in real-world applications, where the training set only accesses to the supervised information from superclasses but the target task is defined on fine-grained classes. Each superclass can contain multiple fine-grained classes. In this scenario, fine-grained patterns are essential to classify examples from fine-grained classes while they can be neglected when training only with labels from superclasses. To mitigate the challenge, we propose the algorithm to explore the fine-grained patterns sufficiently without additional supervised information. Besides, our analysis indicates that the performance of learned patterns on the fine-grained classes can be theoretically guaranteed. Finally, an efficient algorithm is developed to reduce the cost of optimization. The experiments on real-world data sets verify that the propose algorithm can significantly improve the performance on the fine-grained classes with information from superclasses only.