 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Global Sensing Quality Maximization: A Configuration Optimization Scheme for Camera Networks
Nov 28, 2022The performance of a camera network monitoring a set of targets depends crucially on the configuration of the cameras. In this paper, we investigate the reconfiguration strategy for the parameterized camera network model, with which the sensing qualities of the multiple targets can be optimized globally and simultaneously. We first propose to use the number of pixels occupied by a unit-length object in image as a metric of the sensing quality of the object, which is determined by the parameters of the camera, such as intrinsic, extrinsic, and distortional coefficients. Then, we form a single quantity that measures the sensing quality of the targets by the camera network. This quantity further serves as the objective function of our optimization problem to obtain the optimal camera configuration. We verify the effectiveness of our approach through extensive simulations and experiments, and the results reveal its improved performance on the AprilTag detection tasks. Codes and related utilities for this work are open-sourced and available at https://github.com/sszxc/MultiCam-Simulation.
Safety-Critical Optimal Control for Robotic Manipulators in A Cluttered Environment
Nov 11, 2022



Designing safety-critical control for robotic manipulators is challenging, especially in a cluttered environment. First, the actual trajectory of a manipulator might deviate from the planned one due to the complex collision environments and non-trivial dynamics, leading to collision; Second, the feasible space for the manipulator is hard to obtain since the explicit distance functions between collision meshes are unknown. By analyzing the relationship between the safe set and the controlled invariant set, this paper proposes a data-driven control barrier function (CBF) construction method, which extracts CBF from distance samples. Specifically, the CBF guarantees the controlled invariant property for considering the system dynamics. The data-driven method samples the distance function and determines the safe set. Then, the CBF is synthesized based on the safe set by a scenario-based sum of square (SOS) program. Unlike most existing linearization based approaches, our method reserves the volume of the feasible space for planning without approximation, which helps find a solution in a cluttered environment. The control law is obtained by solving a CBF-based quadratic program in real time, which works as a safe filter for the desired planning-based controller. Moreover, our method guarantees safety with the proven probabilistic result. Our method is validated on a 7-DOF manipulator in both real and virtual cluttered environments. The experiments show that the manipulator is able to execute tasks where the clearance between obstacles is in millimeters.
Multi-view Multi-label Anomaly Network Traffic Classification based on MLP-Mixer Neural Network
Nov 08, 2022Network traffic classification is the basis of many network security applications and has attracted enough attention in the field of cyberspace security. Existing network traffic classification based on convolutional neural networks (CNNs) often emphasizes local patterns of traffic data while ignoring global information associations. In this paper, we propose a MLP-Mixer based multi-view multi-label neural network for network traffic classification. Compared with the existing CNN-based methods, our method adopts the MLP-Mixer structure, which is more in line with the structure of the packet than the conventional convolution operation. In our method, the packet is divided into the packet header and the packet body, together with the flow features of the packet as input from different views. We utilize a multi-label setting to learn different scenarios simultaneously to improve the classification performance by exploiting the correlations between different scenarios. Taking advantage of the above characteristics, we propose an end-to-end network traffic classification method. We conduct experiments on three public datasets, and the experimental results show that our method can achieve superior performance.
Deep Data Augmentation for Weed Recognition Enhancement: A Diffusion Probabilistic Model and Transfer Learning Based Approach
Oct 18, 2022
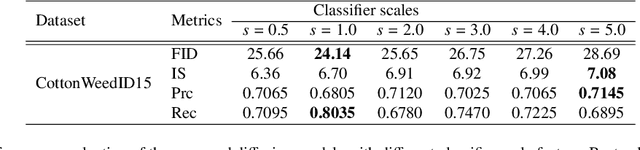
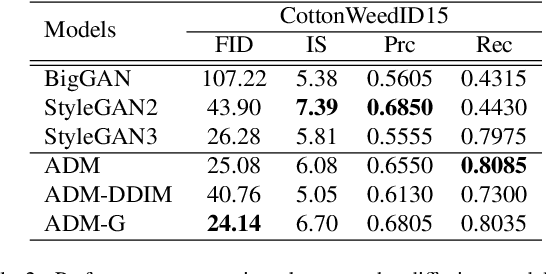

Weed management plays an important role in many modern agricultural applications. Conventional weed control methods mainly rely on chemical herbicides or hand weeding, which are often cost-ineffective, environmentally unfriendly, or even posing a threat to food safety and human health. Recently, automated/robotic weeding using machine vision systems has seen increased research attention with its potential for precise and individualized weed treatment. However, dedicated, large-scale, and labeled weed image datasets are required to develop robust and effective weed identification systems but they are often difficult and expensive to obtain. To address this issue, data augmentation approaches, such as generative adversarial networks (GANs), have been explored to generate highly realistic images for agricultural applications. Yet, despite some progress, those approaches are often complicated to train or have difficulties preserving fine details in images. In this paper, we present the first work of applying diffusion probabilistic models (also known as diffusion models) to generate high-quality synthetic weed images based on transfer learning. Comprehensive experimental results show that the developed approach consistently outperforms several state-of-the-art GAN models, representing the best trade-off between sample fidelity and diversity and highest FID score on a common weed dataset, CottonWeedID15. In addition, the expanding dataset with synthetic weed images can apparently boost model performance on four deep learning (DL) models for the weed classification tasks. Furthermore, the DL models trained on CottonWeedID15 dataset with only 10% of real images and 90% of synthetic weed images achieve a testing accuracy of over 94%, showing high-quality of the generated weed samples. The codes of this study are made publicly available at https://github.com/DongChen06/DMWeeds.
FedForgery: Generalized Face Forgery Detection with Residual Federated Learning
Oct 18, 2022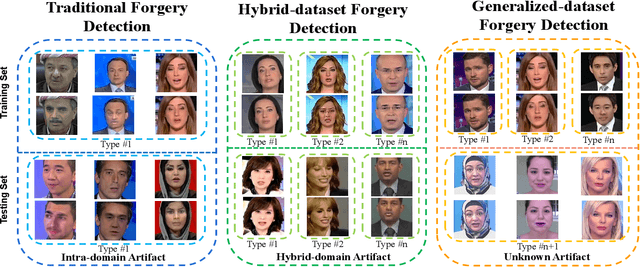
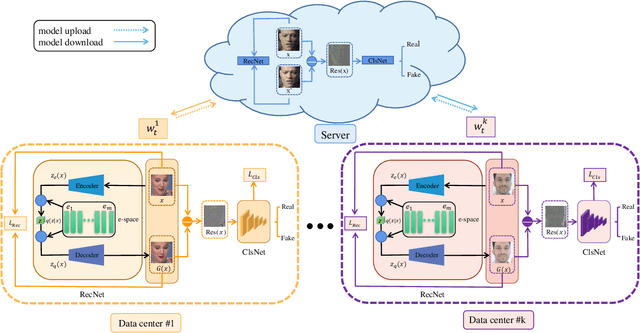

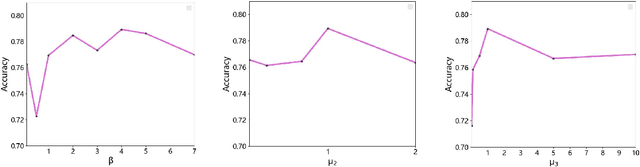
With the continuous development of deep learning in the field of image generation models, a large number of vivid forged faces have been generated and spread on the Internet. These high-authenticity artifacts could grow into a threat to society security. Existing face forgery detection methods directly utilize the obtained public shared or centralized data for training but ignore the personal privacy and security issues when personal data couldn't be centralizedly shared in real-world scenarios. Additionally, different distributions caused by diverse artifact types would further bring adverse influences on the forgery detection task. To solve the mentioned problems, the paper proposes a novel generalized residual Federated learning for face Forgery detection (FedForgery). The designed variational autoencoder aims to learn robust discriminative residual feature maps to detect forgery faces (with diverse or even unknown artifact types). Furthermore, the general federated learning strategy is introduced to construct distributed detection model trained collaboratively with multiple local decentralized devices, which could further boost the representation generalization. Experiments conducted on publicly available face forgery detection datasets prove the superior performance of the proposed FedForgery. The designed novel generalized face forgery detection protocols and source code would be publicly available.
Unifying Graph Contrastive Learning with Flexible Contextual Scopes
Oct 17, 2022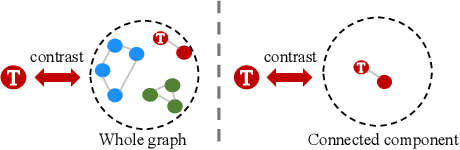
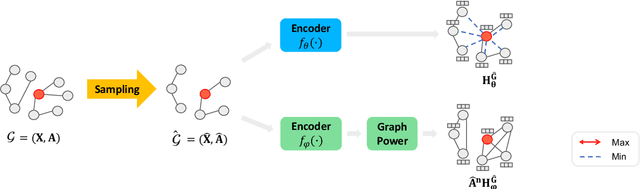
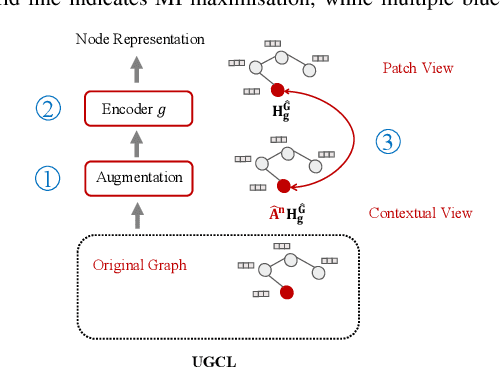
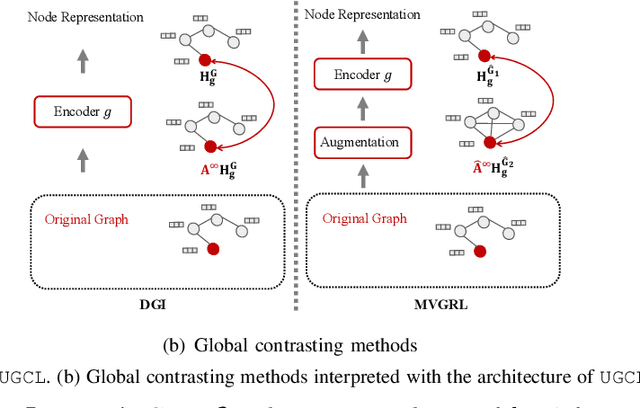
Graph contrastive learning (GCL) has recently emerged as an effective learning paradigm to alleviate the reliance on labelling information for graph representation learning. The core of GCL is to maximise the mutual information between the representation of a node and its contextual representation (i.e., the corresponding instance with similar semantic information) summarised from the contextual scope (e.g., the whole graph or 1-hop neighbourhood). This scheme distils valuable self-supervision signals for GCL training. However, existing GCL methods still suffer from limitations, such as the incapacity or inconvenience in choosing a suitable contextual scope for different datasets and building biased contrastiveness. To address aforementioned problems, we present a simple self-supervised learning method termed Unifying Graph Contrastive Learning with Flexible Contextual Scopes (UGCL for short). Our algorithm builds flexible contextual representations with tunable contextual scopes by controlling the power of an adjacency matrix. Additionally, our method ensures contrastiveness is built within connected components to reduce the bias of contextual representations. Based on representations from both local and contextual scopes, UGCL optimises a very simple contrastive loss function for graph representation learning. Essentially, the architecture of UGCL can be considered as a general framework to unify existing GCL methods. We have conducted intensive experiments and achieved new state-of-the-art performance in six out of eight benchmark datasets compared with self-supervised graph representation learning baselines. Our code has been open-sourced.
THUEE system description for NIST 2020 SRE CTS challenge
Oct 12, 2022
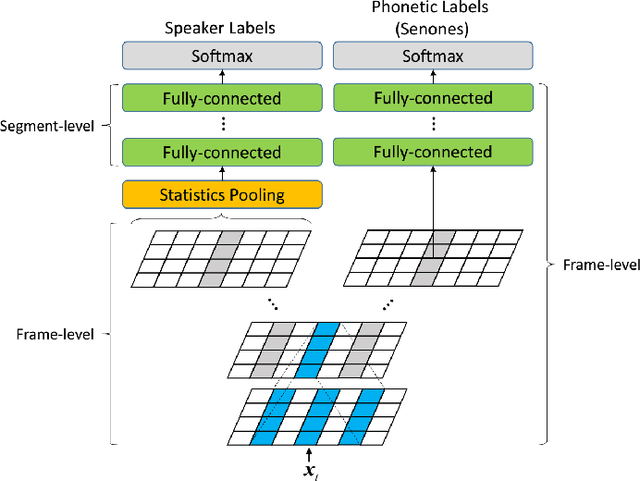
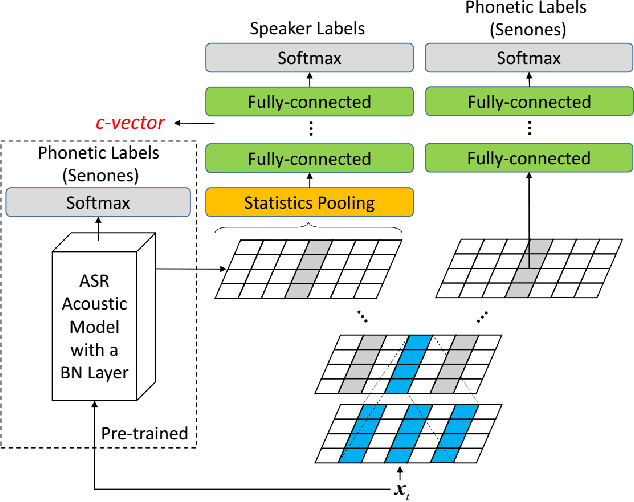

This paper presents the system description of the THUEE team for the NIST 2020 Speaker Recognition Evaluation (SRE) conversational telephone speech (CTS) challenge. The subsystems including ResNet74, ResNet152, and RepVGG-B2 are developed as speaker embedding extractors in this evaluation. We used combined AM-Softmax and AAM-Softmax based loss functions, namely CM-Softmax. We adopted a two-staged training strategy to further improve system performance. We fused all individual systems as our final submission. Our approach leads to excellent performance and ranks 1st in the challenge.
The SpeakIn Speaker Verification System for Far-Field Speaker Verification Challenge 2022
Sep 23, 2022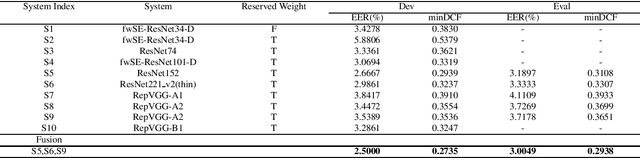
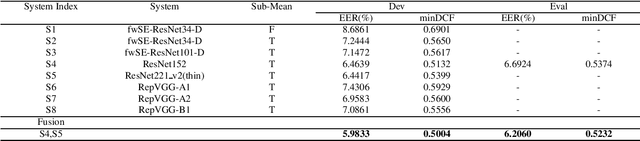
This paper describes speaker verification (SV) systems submitted by the SpeakIn team to the Task 1 and Task 2 of the Far-Field Speaker Verification Challenge 2022 (FFSVC2022). SV tasks of the challenge focus on the problem of fully supervised far-field speaker verification (Task 1) and semi-supervised far-field speaker verification (Task 2). In Task 1, we used the VoxCeleb and FFSVC2020 datasets as train datasets. And for Task 2, we only used the VoxCeleb dataset as train set. The ResNet-based and RepVGG-based architectures were developed for this challenge. Global statistic pooling structure and MQMHA pooling structure were used to aggregate the frame-level features across time to obtain utterance-level representation. We adopted AM-Softmax and AAM-Softmax to classify the resulting embeddings. We innovatively propose a staged transfer learning method. In the pre-training stage we reserve the speaker weights, and there are no positive samples to train them in this stage. Then we fine-tune these weights with both positive and negative samples in the second stage. Compared with the traditional transfer learning strategy, this strategy can better improve the model performance. The Sub-Mean and AS-Norm backend methods were used to solve the problem of domain mismatch. In the fusion stage, three models were fused in Task1 and two models were fused in Task2. On the FFSVC2022 leaderboard, the EER of our submission is 3.0049% and the corresponding minDCF is 0.2938 in Task1. In Task2, EER and minDCF are 6.2060% and 0.5232 respectively. Our approach leads to excellent performance and ranks 1st in both challenge tasks.
The SpeakIn System Description for CNSRC2022
Sep 22, 2022


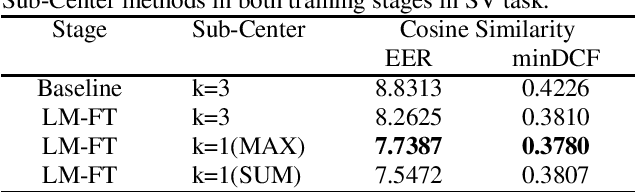
This report describes our speaker verification systems for the tasks of the CN-Celeb Speaker Recognition Challenge 2022 (CNSRC 2022). This challenge includes two tasks, namely speaker verification(SV) and speaker retrieval(SR). The SV task involves two tracks: fixed track and open track. In the fixed track, we only used CN-Celeb.T as the training set. For the open track of the SV task and SR task, we added our open-source audio data. The ResNet-based, RepVGG-based, and TDNN-based architectures were developed for this challenge. Global statistic pooling structure and MQMHA pooling structure were used to aggregate the frame-level features across time to obtain utterance-level representation. We adopted AM-Softmax and AAM-Softmax combined with the Sub-Center method to classify the resulting embeddings. We also used the Large-Margin Fine-Tuning strategy to further improve the model performance. In the backend, Sub-Mean and AS-Norm were used. In the SV task fixed track, our system was a fusion of five models, and two models were fused in the SV task open track. And we used a single system in the SR task. Our approach leads to superior performance and comes the 1st place in the open track of the SV task, the 2nd place in the fixed track of the SV task, and the 3rd place in the SR task.
Dual Contrastive Network for Sequential Recommendation with User and Item-Centric Perspectives
Sep 18, 2022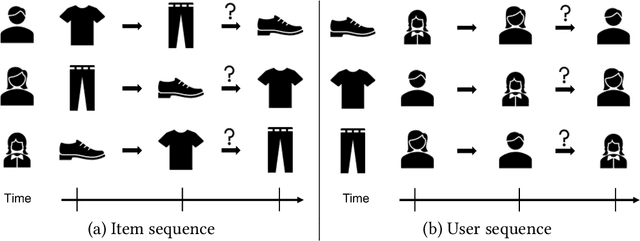
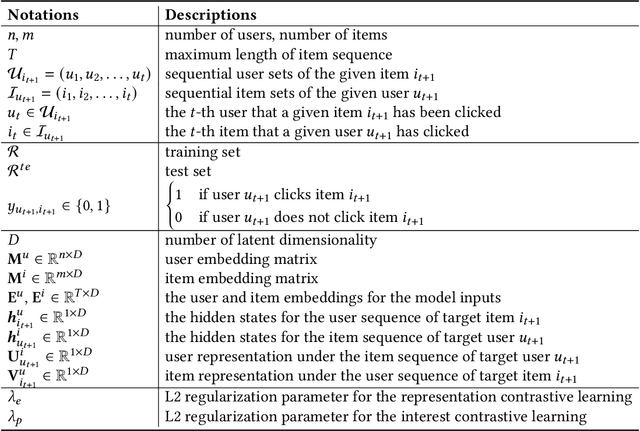
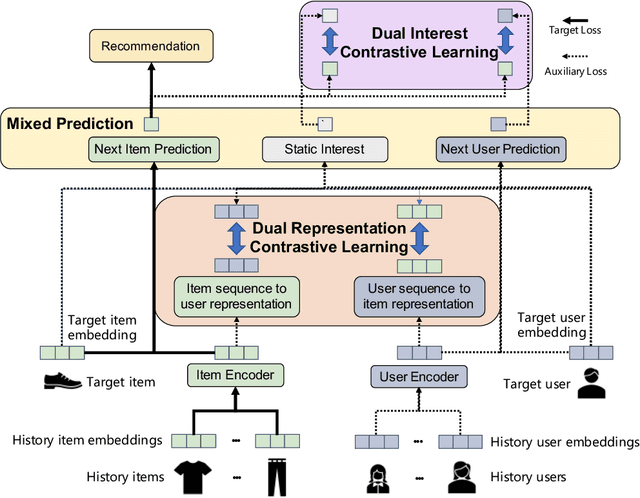

With the outbreak of today's streaming data, sequential recommendation is a promising solution to achieve time-aware personalized modeling. It aims to infer the next interacted item of given user based on history item sequence. Some recent works tend to improve the sequential recommendation via randomly masking on the history item so as to generate self-supervised signals. But such approach will indeed result in sparser item sequence and unreliable signals. Besides, the existing sequential recommendation is only user-centric, i.e., based on the historical items by chronological order to predict the probability of candidate items, which ignores whether the items from a provider can be successfully recommended. The such user-centric recommendation will make it impossible for the provider to expose their new items and result in popular bias. In this paper, we propose a novel Dual Contrastive Network (DCN) to generate ground-truth self-supervised signals for sequential recommendation by auxiliary user-sequence from item-centric perspective. Specifically, we propose dual representation contrastive learning to refine the representation learning by minimizing the euclidean distance between the representations of given user/item and history items/users of them. Before the second contrastive learning module, we perform next user prediction to to capture the trends of items preferred by certain types of users and provide personalized exploration opportunities for item providers. Finally, we further propose dual interest contrastive learning to self-supervise the dynamic interest from next item/user prediction and static interest of matching probability. Experiments on four benchmark datasets verify the effectiveness of our proposed method. Further ablation study also illustrates the boosting effect of the proposed components upon different sequential models.