 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Perception with a Large Tactile-Vision-Language Model for Physical Property Inference
Jun 24, 2025Inferring physical properties can significantly enhance robotic manipulation by enabling robots to handle objects safely and efficiently through adaptive grasping strategies. Previous approaches have typically relied on either tactile or visual data, limiting their ability to fully capture properties. We introduce a novel cross-modal perception framework that integrates visual observations with tactile representations within a multimodal vision-language model. Our physical reasoning framework, which employs a hierarchical feature alignment mechanism and a refined prompting strategy, enables our model to make property-specific predictions that strongly correlate with ground-truth measurements. Evaluated on 35 diverse objects, our approach outperforms existing baselines and demonstrates strong zero-shot generalization. Keywords: tactile perception, visual-tactile fusion, physical property inference, multimodal integration, robot perception
FlowQ: Energy-Guided Flow Policies for Offline Reinforcement Learning
May 20, 2025The use of guidance to steer sampling toward desired outcomes has been widely explored within diffusion models, especially in applications such as image and trajectory generation. However, incorporating guidance during training remains relatively underexplored. In this work, we introduce energy-guided flow matching, a novel approach that enhances the training of flow models and eliminates the need for guidance at inference time. We learn a conditional velocity field corresponding to the flow policy by approximating an energy-guided probability path as a Gaussian path. Learning guided trajectories is appealing for tasks where the target distribution is defined by a combination of data and an energy function, as in reinforcement learning. Diffusion-based policies have recently attracted attention for their expressive power and ability to capture multi-modal action distributions. Typically, these policies are optimized using weighted objectives or by back-propagating gradients through actions sampled by the policy. As an alternative, we propose FlowQ, an offline reinforcement learning algorithm based on energy-guided flow matching. Our method achieves competitive performance while the policy training time is constant in the number of flow sampling steps.
LIMT: Language-Informed Multi-Task Visual World Models
Jul 18, 2024



Most recent successes in robot reinforcement learning involve learning a specialized single-task agent. However, robots capable of performing multiple tasks can be much more valuable in real-world applications. Multi-task reinforcement learning can be very challenging due to the increased sample complexity and the potentially conflicting task objectives. Previous work on this topic is dominated by model-free approaches. The latter can be very sample inefficient even when learning specialized single-task agents. In this work, we focus on model-based multi-task reinforcement learning. We propose a method for learning multi-task visual world models, leveraging pre-trained language models to extract semantically meaningful task representations. These representations are used by the world model and policy to reason about task similarity in dynamics and behavior. Our results highlight the benefits of using language-driven task representations for world models and a clear advantage of model-based multi-task learning over the more common model-free paradigm.
A dataset of primary nasopharyngeal carcinoma MRI with multi-modalities segmentation
Apr 04, 2024Multi-modality magnetic resonance imaging data with various sequences facilitate the early diagnosis, tumor segmentation, and disease staging in the management of nasopharyngeal carcinoma (NPC). The lack of publicly available, comprehensive datasets limits advancements in diagnosis, treatment planning, and the development of machine learning algorithms for NPC. Addressing this critical need, we introduce the first comprehensive NPC MRI dataset, encompassing MR axial imaging of 277 primary NPC patients. This dataset includes T1-weighted, T2-weighted, and contrast-enhanced T1-weighted sequences, totaling 831 scans. In addition to the corresponding clinical data, manually annotated and labeled segmentations by experienced radiologists offer high-quality data resources from untreated primary NPC.
Guided Decoding for Robot Motion Generation and Adaption
Mar 22, 2024



We address motion generation for high-DoF robot arms in complex settings with obstacles, via points, etc. A significant advancement in this domain is achieved by integrating Learning from Demonstration (LfD) into the motion generation process. This integration facilitates rapid adaptation to new tasks and optimizes the utilization of accumulated expertise by allowing robots to learn and generalize from demonstrated trajectories. We train a transformer architecture on a large dataset of simulated trajectories. This architecture, based on a conditional variational autoencoder transformer, learns essential motion generation skills and adapts these to meet auxiliary tasks and constraints. Our auto-regressive approach enables real-time integration of feedback from the physical system, enhancing the adaptability and efficiency of motion generation. We show that our model can generate motion from initial and target points, but also that it can adapt trajectories in navigating complex tasks, including obstacle avoidance, via points, and meeting velocity and acceleration constraints, across platforms.
DomainLab: A modular Python package for domain generalization in deep learning
Mar 21, 2024
Poor generalization performance caused by distribution shifts in unseen domains often hinders the trustworthy deployment of deep neural networks. Many domain generalization techniques address this problem by adding a domain invariant regularization loss terms during training. However, there is a lack of modular software that allows users to combine the advantages of different methods with minimal effort for reproducibility. DomainLab is a modular Python package for training user specified neural networks with composable regularization loss terms. Its decoupled design allows the separation of neural networks from regularization loss construction. Hierarchical combinations of neural networks, different domain generalization methods, and associated hyperparameters, can all be specified together with other experimental setup in a single configuration file. Hierarchical combinations of neural networks, different domain generalization methods, and associated hyperparameters, can all be specified together with other experimental setup in a single configuration file. In addition, DomainLab offers powerful benchmarking functionality to evaluate the generalization performance of neural networks in out-of-distribution data. The package supports running the specified benchmark on an HPC cluster or on a standalone machine. The package is well tested with over 95 percent coverage and well documented. From the user perspective, it is closed to modification but open to extension. The package is under the MIT license, and its source code, tutorial and documentation can be found at https://github.com/marrlab/DomainLab.
M-HOF-Opt: Multi-Objective Hierarchical Output Feedback Optimization via Multiplier Induced Loss Landscape Scheduling
Mar 20, 2024



When a neural network parameterized loss function consists of many terms, the combinatorial choice of weight multipliers during the optimization process forms a challenging problem. To address this, we proposed a probabilistic graphical model (PGM) for the joint model parameter and multiplier evolution process, with a hypervolume based likelihood that promotes multi-objective descent of each loss term. The corresponding parameter and multiplier estimation as a sequential decision process is then cast into an optimal control problem, where the multi-objective descent goal is dispatched hierarchically into a series of constraint optimization sub-problems. The sub-problem constraint automatically adapts itself according to Pareto dominance and serves as the setpoint for the low level multiplier controller to schedule loss landscapes via output feedback of each loss term. Our method is multiplier-free and operates at the timescale of epochs, thus saves tremendous computational resources compared to full training cycle multiplier tuning. We applied it to domain invariant variational auto-encoding with 6 loss terms on the PACS domain generalization task, and observed robust performance across a range of controller hyperparameters, as well as different multiplier initial conditions, outperforming other multiplier scheduling methods. We offered modular implementation of our method, admitting custom definition of many loss terms for applying our multi-objective hierarchical output feedback training scheme to other deep learning fields.
Sequential Model for Predicting Patient Adherence in Subcutaneous Immunotherapy for Allergic Rhinitis
Jan 23, 2024

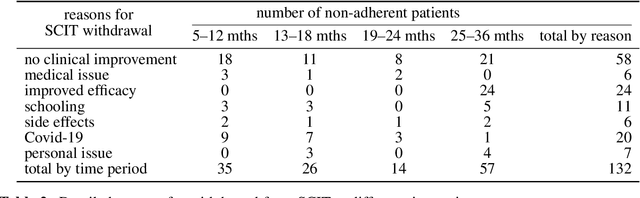

Objective: Subcutaneous Immunotherapy (SCIT) is the long-lasting causal treatment of allergic rhinitis. How to enhance the adherence of patients to maximize the benefit of allergen immunotherapy (AIT) plays a crucial role in the management of AIT. This study aims to leverage novel machine learning models to precisely predict the risk of non-adherence of patients and related systematic symptom scores, to provide a novel approach in the management of long-term AIT. Methods: The research develops and analyzes two models, Sequential Latent Actor-Critic (SLAC) and Long Short-Term Memory (LSTM), evaluating them based on scoring and adherence prediction capabilities. Results: Excluding the biased samples at the first time step, the predictive adherence accuracy of the SLAC models is from $60\,\%$ to $72\%$, and for LSTM models, it is $66\,\%$ to $84\,\%$, varying according to the time steps. The range of Root Mean Square Error (RMSE) for SLAC models is between $0.93$ and $2.22$, while for LSTM models it is between $1.09$ and $1.77$. Notably, these RMSEs are significantly lower than the random prediction error of $4.55$. Conclusion: We creatively apply sequential models in the long-term management of SCIT with promising accuracy in the prediction of SCIT nonadherence in Allergic Rhinitis (AR) patients. While LSTM outperforms SLAC in adherence prediction, SLAC excels in score prediction for patients undergoing SCIT for AR. The state-action-based SLAC adds flexibility, presenting a novel and effective approach for managing long-term AIT.
Probabilistic Dalek -- Emulator framework with probabilistic prediction for supernova tomography
Sep 20, 2022
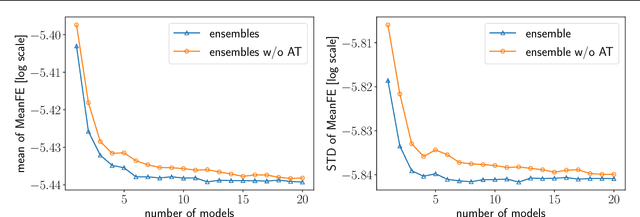
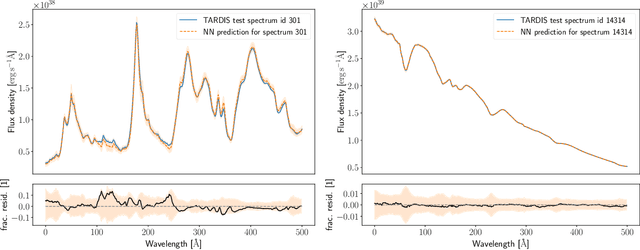
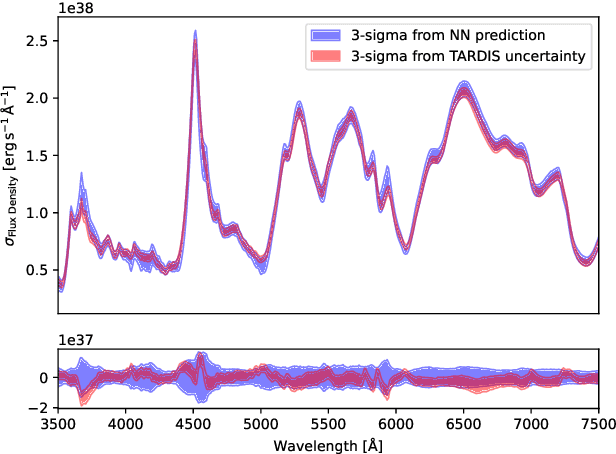
Supernova spectral time series can be used to reconstruct a spatially resolved explosion model known as supernova tomography. In addition to an observed spectral time series, a supernova tomography requires a radiative transfer model to perform the inverse problem with uncertainty quantification for a reconstruction. The smallest parametrizations of supernova tomography models are roughly a dozen parameters with a realistic one requiring more than 100. Realistic radiative transfer models require tens of CPU minutes for a single evaluation making the problem computationally intractable with traditional means requiring millions of MCMC samples for such a problem. A new method for accelerating simulations known as surrogate models or emulators using machine learning techniques offers a solution for such problems and a way to understand progenitors/explosions from spectral time series. There exist emulators for the TARDIS supernova radiative transfer code but they only perform well on simplistic low-dimensional models (roughly a dozen parameters) with a small number of applications for knowledge gain in the supernova field. In this work, we present a new emulator for the radiative transfer code TARDIS that not only outperforms existing emulators but also provides uncertainties in its prediction. It offers the foundation for a future active-learning-based machinery that will be able to emulate very high dimensional spaces of hundreds of parameters crucial for unraveling urgent questions in supernovae and related fields.
Local distance preserving auto-encoders using Continuous k-Nearest Neighbours graphs
Jun 13, 2022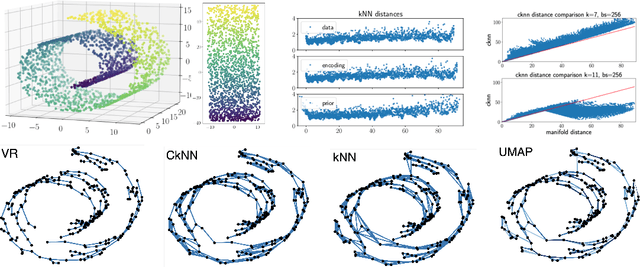
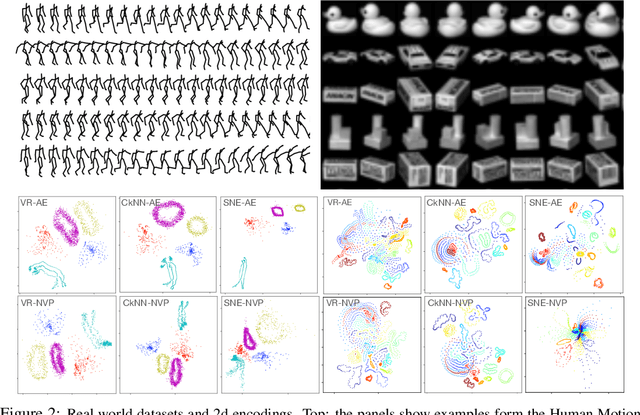
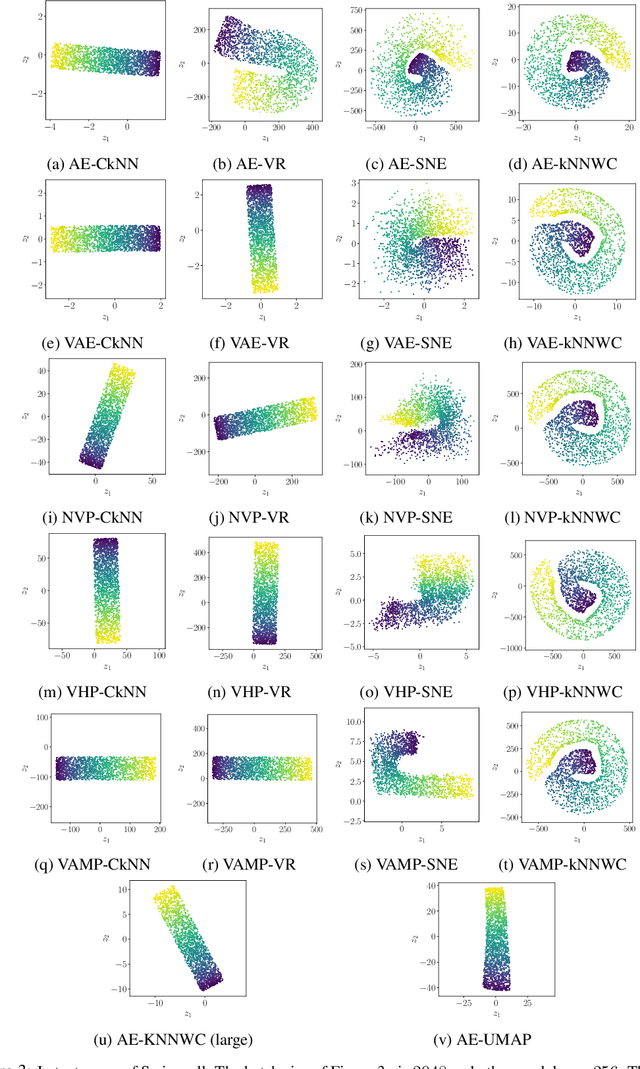
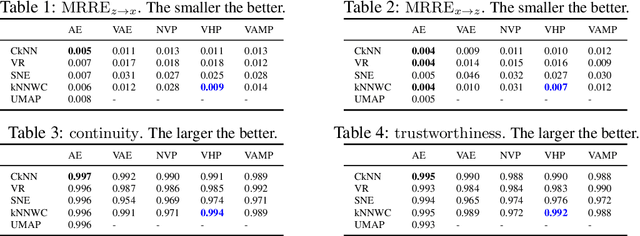
Auto-encoder models that preserve similarities in the data are a popular tool in representation learning. In this paper we introduce several auto-encoder models that preserve local distances when mapping from the data space to the latent space. We use a local distance preserving loss that is based on the continuous k-nearest neighbours graph which is known to capture topological features at all scales simultaneously. To improve training performance, we formulate learning as a constraint optimisation problem with local distance preservation as the main objective and reconstruction accuracy as a constraint. We generalise this approach to hierarchical variational auto-encoders thus learning generative models with geometrically consistent latent and data spaces. Our method provides state-of-the-art performance across several standard datasets and evaluation metrics.