 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaptainCook4D: A dataset for understanding errors in procedural activities
Dec 22, 2023



Following step-by-step procedures is an essential component of various activities carried out by individuals in their daily lives. These procedures serve as a guiding framework that helps to achieve goals efficiently, whether it is assembling furniture or preparing a recipe. However, the complexity and duration of procedural activities inherently increase the likelihood of making errors. Understanding such procedural activities from a sequence of frames is a challenging task that demands an accurate interpretation of visual information and the ability to reason about the structure of the activity. To this end, we collect a new egocentric 4D dataset, CaptainCook4D, comprising 384 recordings (94.5 hours) of people performing recipes in real kitchen environments. This dataset consists of two distinct types of activity: one in which participants adhere to the provided recipe instructions and another in which they deviate and induce errors. We provide 5.3K step annotations and 10K fine-grained action annotations and benchmark the dataset for the following tasks: supervised error recognition, multistep localization, and procedure learning
Segment Every Out-of-Distribution Object
Nov 27, 2023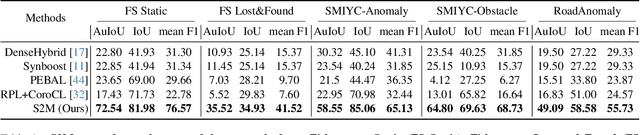

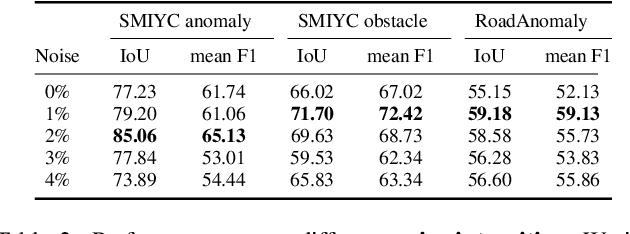
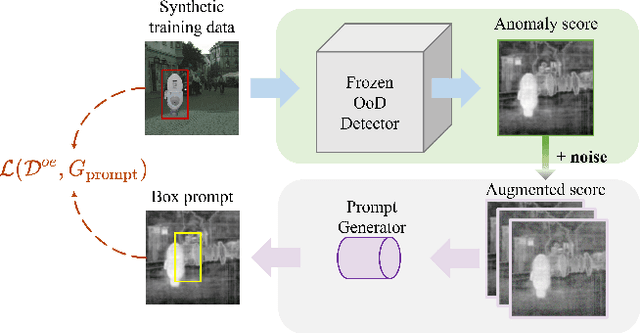
Semantic segmentation models, while effective for in-distribution categories, face challenges in real-world deployment due to encountering out-of-distribution (OoD) objects. Detecting these OoD objects is crucial for safety-critical applications. Existing methods rely on anomaly scores, but choosing a suitable threshold for generating masks presents difficulties and can lead to fragmentation and inaccuracy. This paper introduces a method to convert anomaly Score To segmentation Mask, called S2M, a simple and effective framework for OoD detection in semantic segmentation. Unlike assigning anomaly scores to pixels, S2M directly segments the entire OoD object. By transforming anomaly scores into prompts for a promptable segmentation model, S2M eliminates the need for threshold selection. Extensive experiments demonstrate that S2M outperforms the state-of-the-art by approximately 10\% in IoU and 30\% in mean F1 score, on average, across various benchmarks including Fishyscapes, Segment-Me-If-You-Can, and RoadAnomaly datasets.
AMPLIFY:Attention-based Mixup for Performance Improvement and Label Smoothing in Transformer
Sep 22, 2023



Mixup is an effective data augmentation method that generates new augmented samples by aggregating linear combinations of different original samples. However, if there are noises or aberrant features in the original samples, Mixup may propagate them to the augmented samples, leading to over-sensitivity of the model to these outliers . To solve this problem, this paper proposes a new Mixup method called AMPLIFY. This method uses the Attention mechanism of Transformer itself to reduce the influence of noises and aberrant values in the original samples on the prediction results, without increasing additional trainable parameters, and the computational cost is very low, thereby avoiding the problem of high resource consumption in common Mixup methods such as Sentence Mixup . The experimental results show that, under a smaller computational resource cost, AMPLIFY outperforms other Mixup methods in text classification tasks on 7 benchmark datasets, providing new ideas and new ways to further improve the performance of pre-trained models based on the Attention mechanism, such as BERT, ALBERT, RoBERTa, and GPT. Our code can be obtained at https://github.com/kiwi-lilo/AMPLIFY.
Error Probability Bounds for Invariant Causal Prediction via Multiple Access Channels
Aug 19, 2023

We consider the problem of lower bounding the error probability under the invariant causal prediction (ICP) framework. To this end, we examine and draw connections between ICP and the zero-rate Gaussian multiple access channel by first proposing a variant of the original invariant prediction assumption, and then considering a special case of the Gaussian multiple access channel where a codebook is shared between an unknown number of senders. This connection allows us to develop three types of lower bounds on the error probability, each with different assumptions and constraints, leveraging techniques for multiple access channels. The proposed bounds are evaluated with respect to existing causal discovery methods as well as a proposed heuristic method based on minimum distance decoding.
Proto-CLIP: Vision-Language Prototypical Network for Few-Shot Learning
Jul 08, 2023



We propose a novel framework for few-shot learning by leveraging large-scale vision-language models such as CLIP. Motivated by the unimodal prototypical networks for few-shot learning, we introduce PROTO-CLIP that utilizes image prototypes and text prototypes for few-shot learning. Specifically, PROTO-CLIP adapts the image encoder and text encoder in CLIP in a joint fashion using few-shot examples. The two encoders are used to compute prototypes of image classes for classification. During adaptation, we propose aligning the image and text prototypes of corresponding classes. Such a proposed alignment is beneficial for few-shot classification due to the contributions from both types of prototypes. We demonstrate the effectiveness of our method by conducting experiments on benchmark datasets for few-shot learning as well as in the real world for robot perception.
SCENEREPLICA: Benchmarking Real-World Robot Manipulation by Creating Reproducible Scenes
Jun 27, 2023



We present a new reproducible benchmark for evaluating robot manipulation in the real world, specifically focusing on pick-and-place. Our benchmark uses the YCB objects, a commonly used dataset in the robotics community, to ensure that our results are comparable to other studies. Additionally, the benchmark is designed to be easily reproducible in the real world, making it accessible to researchers and practitioners. We also provide our experimental results and analyzes for model-based and model-free 6D robotic grasping on the benchmark, where representative algorithms are evaluated for object perception, grasping planning, and motion planning. We believe that our benchmark will be a valuable tool for advancing the field of robot manipulation. By providing a standardized evaluation framework, researchers can more easily compare different techniques and algorithms, leading to faster progress in developing robot manipulation methods.
Pedestrian Recognition with Radar Data-Enhanced Deep Learning Approach Based on Micro-Doppler Signatures
Jun 14, 2023As a hot topic in recent years, the ability of pedestrians identification based on radar micro-Doppler signatures is limited by the lack of adequate training data. In this paper, we propose a data-enhanced multi-characteristic learning (DEMCL) model with data enhancement (DE) module and multi-characteristic learning (MCL) module to learn more complementary pedestrian micro-Doppler (m-D) signatures. In DE module, a range-Doppler generative adversarial network (RDGAN) is proposed to enhance free walking datasets, and MCL module with multi-scale convolution neural network (MCNN) and radial basis function neural network (RBFNN) is trained to learn m-D signatures extracted from enhanced datasets. Experimental results show that our model is 3.33% to 10.24% more accurate than other studies and has a short run time of 0.9324 seconds on a 25-minute walking dataset.
Structural Hawkes Processes for Learning Causal Structure from Discrete-Time Event Sequences
May 10, 2023



Learning causal structure among event types from discrete-time event sequences is a particularly important but challenging task. Existing methods, such as the multivariate Hawkes processes based methods, mostly boil down to learning the so-called Granger causality which assumes that the cause event happens strictly prior to its effect event. Such an assumption is often untenable beyond applications, especially when dealing with discrete-time event sequences in low-resolution; and typical discrete Hawkes processes mainly suffer from identifiability issues raised by the instantaneous effect, i.e., the causal relationship that occurred simultaneously due to the low-resolution data will not be captured by Granger causality. In this work, we propose Structure Hawkes Processes (SHPs) that leverage the instantaneous effect for learning the causal structure among events type in discrete-time event sequence. The proposed method is featured with the minorization-maximization of the likelihood function and a sparse optimization scheme. Theoretical results show that the instantaneous effect is a blessing rather than a curse, and the causal structure is identifiable under the existence of the instantaneous effect. Experiments on synthetic and real-world data verify the effectiveness of the proposed method.
Novel deep learning methods for 3D flow field segmentation and classification
May 10, 2023Flow field segmentation and classification help researchers to understand vortex structure and thus turbulent flow. Existing deep learning methods mainly based on global information and focused on 2D circumstance. Based on flow field theory, we propose novel flow field segmentation and classification deep learning methods in three-dimensional space. We construct segmentation criterion based on local velocity information and classification criterion based on the relationship between local vorticity and vortex wake, to identify vortex structure in 3D flow field, and further classify the type of vortex wakes accurately and rapidly. Simulation experiment results showed that, compared with existing methods, our segmentation method can identify the vortex area more accurately, while the time consumption is reduced more than 50\%; our classification method can reduce the time consumption by more than 90\% while maintaining the same classification accuracy level.
Dual Residual Attention Network for Image Denoising
May 07, 2023



In image denoising, deep convolutional neural networks (CNNs) can obtain favorable performance on removing spatially invariant noise. However, many of these networks cannot perform well on removing the real noise (i.e. spatially variant noise) generated during image acquisition or transmission, which severely sets back their application in practical image denoising tasks. Instead of continuously increasing the network depth, many researchers have revealed that expanding the width of networks can also be a useful way to improve model performance. It also has been verified that feature filtering can promote the learning ability of the models. Therefore, in this paper, we propose a novel Dual-branch Residual Attention Network (DRANet) for image denoising, which has both the merits of a wide model architecture and attention-guided feature learning. The proposed DRANet includes two different parallel branches, which can capture complementary features to enhance the learning ability of the model. We designed a new residual attention block (RAB) and a novel hybrid dilated residual attention block (HDRAB) for the upper and the lower branches, respectively. The RAB and HDRAB can capture rich local features through multiple skip connections between different convolutional layers, and the unimportant features are dropped by the residual attention modules. Meanwhile, the long skip connections in each branch, and the global feature fusion between the two parallel branches can capture the global features as well. Moreover, the proposed DRANet uses downsampling operations and dilated convolutions to increase the size of the receptive field, which can enable DRANet to capture more image context information. Extensive experiments demonstrate that compared with other state-of-the-art denoising methods, our DRANet can produce competitive denoising performance both on synthetic and real-world noise removal.