 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Reliability of Multi-agent System: A Perspective from Byzantine Fault Tolerance
Nov 13, 2025Ensuring the reliability of agent architectures and effectively identifying problematic agents when failures occur are crucial challenges in multi-agent systems (MAS). Advances in large language models (LLMs) have established LLM-based agents as a major branch of MAS, enabling major breakthroughs in complex problem solving and world modeling. However, the reliability implications of this shift remain largely unexplored. i.e., whether substituting traditional agents with LLM-based agents can effectively enhance the reliability of MAS. In this work, we investigate and quantify the reliability of LLM-based agents from the perspective of Byzantine fault tolerance. We observe that LLM-based agents demonstrate stronger skepticism when processing erroneous message flows, a characteristic that enables them to outperform traditional agents across different topological structures. Motivated by the results of the pilot experiment, we design CP-WBFT, a confidence probe-based weighted Byzantine Fault Tolerant consensus mechanism to enhance the stability of MAS with different topologies. It capitalizes on the intrinsic reflective and discriminative capabilities of LLMs by employing a probe-based, weighted information flow transmission method to improve the reliability of LLM-based agents. Extensive experiments demonstrate that CP-WBFT achieves superior performance across diverse network topologies under extreme Byzantine conditions (85.7\% fault rate). Notably, our approach surpasses traditional methods by attaining remarkable accuracy on various topologies and maintaining strong reliability in both mathematical reasoning and safety assessment tasks.
Rethinking Robust Adversarial Concept Erasure in Diffusion Models
Oct 31, 2025Concept erasure aims to selectively unlearning undesirable content in diffusion models (DMs) to reduce the risk of sensitive content generation. As a novel paradigm in concept erasure, most existing methods employ adversarial training to identify and suppress target concepts, thus reducing the likelihood of sensitive outputs. However, these methods often neglect the specificity of adversarial training in DMs, resulting in only partial mitigation. In this work, we investigate and quantify this specificity from the perspective of concept space, i.e., can adversarial samples truly fit the target concept space? We observe that existing methods neglect the role of conceptual semantics when generating adversarial samples, resulting in ineffective fitting of concept spaces. This oversight leads to the following issues: 1) when there are few adversarial samples, they fail to comprehensively cover the object concept; 2) conversely, they will disrupt other target concept spaces. Motivated by the analysis of these findings, we introduce S-GRACE (Semantics-Guided Robust Adversarial Concept Erasure), which grace leveraging semantic guidance within the concept space to generate adversarial samples and perform erasure training. Experiments conducted with seven state-of-the-art methods and three adversarial prompt generation strategies across various DM unlearning scenarios demonstrate that S-GRACE significantly improves erasure performance 26%, better preserves non-target concepts, and reduces training time by 90%. Our code is available at https://github.com/Qhong-522/S-GRACE.
Accelerating Diffusion LLM Inference via Local Determinism Propagation
Oct 08, 2025Diffusion large language models (dLLMs) represent a significant advancement in text generation, offering parallel token decoding capabilities. However, existing open-source implementations suffer from quality-speed trade-offs that impede their practical deployment. Conservative sampling strategies typically decode only the most confident token per step to ensure quality (i.e., greedy decoding), at the cost of inference efficiency due to repeated redundant refinement iterations--a phenomenon we term delayed decoding. Through systematic analysis of dLLM decoding dynamics, we characterize this delayed decoding behavior and propose a training-free adaptive parallel decoding strategy, named LocalLeap, to address these inefficiencies. LocalLeap is built on two fundamental empirical principles: local determinism propagation centered on high-confidence anchors and progressive spatial consistency decay. By applying these principles, LocalLeap identifies anchors and performs localized relaxed parallel decoding within bounded neighborhoods, achieving substantial inference step reduction through early commitment of already-determined tokens without compromising output quality. Comprehensive evaluation on various benchmarks demonstrates that LocalLeap achieves 6.94$\times$ throughput improvements and reduces decoding steps to just 14.2\% of the original requirement, achieving these gains with negligible performance impact. The source codes are available at: https://github.com/friedrichor/LocalLeap.
MobileRAG: Enhancing Mobile Agent with Retrieval-Augmented Generation
Sep 04, 2025Smartphones have become indispensable in people's daily lives, permeating nearly every aspect of modern society. With the continuous advancement of large language models (LLMs), numerous LLM-based mobile agents have emerged. These agents are capable of accurately parsing diverse user queries and automatically assisting users in completing complex or repetitive operations. However, current agents 1) heavily rely on the comprehension ability of LLMs, which can lead to errors caused by misoperations or omitted steps during tasks, 2) lack interaction with the external environment, often terminating tasks when an app cannot fulfill user queries, and 3) lack memory capabilities, requiring each instruction to reconstruct the interface and being unable to learn from and correct previous mistakes. To alleviate the above issues, we propose MobileRAG, a mobile agents framework enhanced by Retrieval-Augmented Generation (RAG), which includes InterRAG, LocalRAG, and MemRAG. It leverages RAG to more quickly and accurately identify user queries and accomplish complex and long-sequence mobile tasks. Additionally, to more comprehensively assess the performance of MobileRAG, we introduce MobileRAG-Eval, a more challenging benchmark characterized by numerous complex, real-world mobile tasks that require external knowledge assistance. Extensive experimental results on MobileRAG-Eval demonstrate that MobileRAG can easily handle real-world mobile tasks, achieving 10.3\% improvement over state-of-the-art methods with fewer operational steps. Our code is publicly available at: https://github.com/liuxiaojieOutOfWorld/MobileRAG_arxiv
Tailored Teaching with Balanced Difficulty: Elevating Reasoning in Multimodal Chain-of-Thought via Prompt Curriculum
Aug 26, 2025The effectiveness of Multimodal Chain-of-Thought (MCoT) prompting is often limited by the use of randomly or manually selected examples. These examples fail to account for both model-specific knowledge distributions and the intrinsic complexity of the tasks, resulting in suboptimal and unstable model performance. To address this, we propose a novel framework inspired by the pedagogical principle of "tailored teaching with balanced difficulty". We reframe prompt selection as a prompt curriculum design problem: constructing a well ordered set of training examples that align with the model's current capabilities. Our approach integrates two complementary signals: (1) model-perceived difficulty, quantified through prediction disagreement in an active learning setup, capturing what the model itself finds challenging; and (2) intrinsic sample complexity, which measures the inherent difficulty of each question-image pair independently of any model. By jointly analyzing these signals, we develop a difficulty-balanced sampling strategy that ensures the selected prompt examples are diverse across both dimensions. Extensive experiments conducted on five challenging benchmarks and multiple popular Multimodal Large Language Models (MLLMs) demonstrate that our method yields substantial and consistent improvements and greatly reduces performance discrepancies caused by random sampling, providing a principled and robust approach for enhancing multimodal reasoning.
MultiMedEdit: A Scenario-Aware Benchmark for Evaluating Knowledge Editing in Medical VQA
Aug 09, 2025Knowledge editing (KE) provides a scalable approach for updating factual knowledge in large language models without full retraining. While previous studies have demonstrated effectiveness in general domains and medical QA tasks, little attention has been paid to KE in multimodal medical scenarios. Unlike text-only settings, medical KE demands integrating updated knowledge with visual reasoning to support safe and interpretable clinical decisions. To address this gap, we propose MultiMedEdit, the first benchmark tailored to evaluating KE in clinical multimodal tasks. Our framework spans both understanding and reasoning task types, defines a three-dimensional metric suite (reliability, generality, and locality), and supports cross-paradigm comparisons across general and domain-specific models. We conduct extensive experiments under single-editing and lifelong-editing settings. Results suggest that current methods struggle with generalization and long-tail reasoning, particularly in complex clinical workflows. We further present an efficiency analysis (e.g., edit latency, memory footprint), revealing practical trade-offs in real-world deployment across KE paradigms. Overall, MultiMedEdit not only reveals the limitations of current approaches but also provides a solid foundation for developing clinically robust knowledge editing techniques in the future.
Integrating clinical reasoning into large language model-based diagnosis through etiology-aware attention steering
Aug 01, 2025Objective: Large Language Models (LLMs) demonstrate significant capabilities in medical text understanding and generation. However, their diagnostic reliability in complex clinical scenarios remains limited. This study aims to enhance LLMs' diagnostic accuracy and clinical reasoning ability. Method: We propose an Etiology-Aware Attention Steering Framework to integrate structured clinical reasoning into LLM-based diagnosis. Specifically, we first construct Clinical Reasoning Scaffolding (CRS) based on authoritative clinical guidelines for three representative acute abdominal emergencies: acute appendicitis, acute pancreatitis, and acute cholecystitis. Next, we develop the Etiology-Aware Head Identification algorithm to pinpoint attention heads crucial for the model's etiology reasoning. To ensure reliable clinical reasoning alignment, we introduce the Reasoning-Guided Parameter-Efficient Fine-tuning that embeds etiological reasoning cues into input representations and steers the selected Etiology-Aware Heads toward critical information through a Reasoning-Guided Loss function. Result: On the Consistent Diagnosis Cohort, our framework improves average diagnostic accuracy by 15.65% and boosts the average Reasoning Focus Score by 31.6% over baselines. External validation on the Discrepant Diagnosis Cohort further confirms its effectiveness in enhancing diagnostic accuracy. Further assessments via Reasoning Attention Frequency indicate that our models exhibit enhanced reliability when faced with real-world complex scenarios. Conclusion: This study presents a practical and effective approach to enhance clinical reasoning in LLM-based diagnosis. By aligning model attention with structured CRS, the proposed framework offers a promising paradigm for building more interpretable and reliable AI diagnostic systems in complex clinical settings.
TUNA: Comprehensive Fine-grained Temporal Understanding Evaluation on Dense Dynamic Videos
May 26, 2025Videos are unique in their integration of temporal elements, including camera, scene, action, and attribute, along with their dynamic relationships over time. However, existing benchmarks for video understanding often treat these properties separately or narrowly focus on specific aspects, overlooking the holistic nature of video content. To address this, we introduce TUNA, a temporal-oriented benchmark for fine-grained understanding on dense dynamic videos, with two complementary tasks: captioning and QA. Our TUNA features diverse video scenarios and dynamics, assisted by interpretable and robust evaluation criteria. We evaluate several leading models on our benchmark, providing fine-grained performance assessments across various dimensions. This evaluation reveals key challenges in video temporal understanding, such as limited action description, inadequate multi-subject understanding, and insensitivity to camera motion, offering valuable insights for improving video understanding models. The data and code are available at https://friedrichor.github.io/projects/TUNA.
Modality Curation: Building Universal Embeddings for Advanced Multimodal Information Retrieval
May 26, 2025
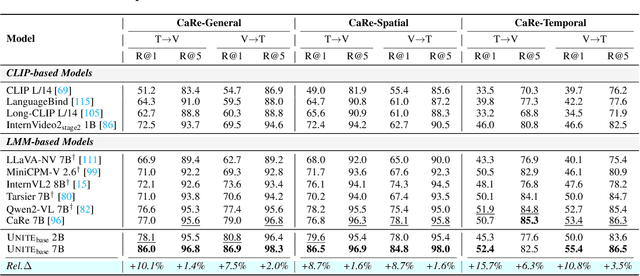

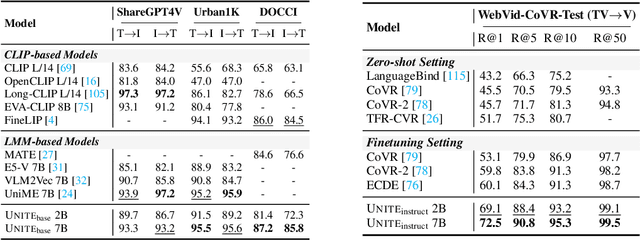
Multimodal information retrieval (MIR) faces inherent challenges due to the heterogeneity of data sources and the complexity of cross-modal alignment. While previous studies have identified modal gaps in feature spaces, a systematic approach to address these challenges remains unexplored. In this work, we introduce UNITE, a universal framework that tackles these challenges through two critical yet underexplored aspects: data curation and modality-aware training configurations. Our work provides the first comprehensive analysis of how modality-specific data properties influence downstream task performance across diverse scenarios. Moreover, we propose Modal-Aware Masked Contrastive Learning (MAMCL) to mitigate the competitive relationships among the instances of different modalities. Our framework achieves state-of-the-art results on multiple multimodal retrieval benchmarks, outperforming existing methods by notable margins. Through extensive experiments, we demonstrate that strategic modality curation and tailored training protocols are pivotal for robust cross-modal representation learning. This work not only advances MIR performance but also provides a foundational blueprint for future research in multimodal systems. Our project is available at https://friedrichor.github.io/projects/UNITE.
ViPlan: A Benchmark for Visual Planning with Symbolic Predicates and Vision-Language Models
May 19, 2025Integrating Large Language Models with symbolic planners is a promising direction for obtaining verifiable and grounded plans compared to planning in natural language, with recent works extending this idea to visual domains using Vision-Language Models (VLMs). However, rigorous comparison between VLM-grounded symbolic approaches and methods that plan directly with a VLM has been hindered by a lack of common environments, evaluation protocols and model coverage. We introduce ViPlan, the first open-source benchmark for Visual Planning with symbolic predicates and VLMs. ViPlan features a series of increasingly challenging tasks in two domains: a visual variant of the classic Blocksworld planning problem and a simulated household robotics environment. We benchmark nine open-source VLM families across multiple sizes, along with selected closed models, evaluating both VLM-grounded symbolic planning and using the models directly to propose actions. We find symbolic planning to outperform direct VLM planning in Blocksworld, where accurate image grounding is crucial, whereas the opposite is true in the household robotics tasks, where commonsense knowledge and the ability to recover from errors are beneficial. Finally, we show that across most models and methods, there is no significant benefit to using Chain-of-Thought prompting, suggesting that current VLMs still struggle with visual reasoning.