 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Generate Reliable Test Case Generators? A Study on Competition-Level Programming Problems
Jun 07, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in code generation, capable of tackling complex tasks during inference. However, the extent to which LLMs can be utilized for code checking or debugging through test case generation remains largely unexplored. We investigate this problem from the perspective of competition-level programming (CP) programs and propose TCGBench, a Benchmark for (LLM generation of) Test Case Generators. This benchmark comprises two tasks, aimed at studying the capabilities of LLMs in (1) generating valid test case generators for a given CP problem, and further (2) generating targeted test case generators that expose bugs in human-written code. Experimental results indicate that while state-of-the-art LLMs can generate valid test case generators in most cases, most LLMs struggle to generate targeted test cases that reveal flaws in human code effectively. Especially, even advanced reasoning models (e.g., o3-mini) fall significantly short of human performance in the task of generating targeted generators. Furthermore, we construct a high-quality, manually curated dataset of instructions for generating targeted generators. Analysis demonstrates that the performance of LLMs can be enhanced with the aid of this dataset, by both prompting and fine-tuning.
ChMusic: A Traditional Chinese Music Dataset for Evaluation of Instrument Recognition
Aug 19, 2021
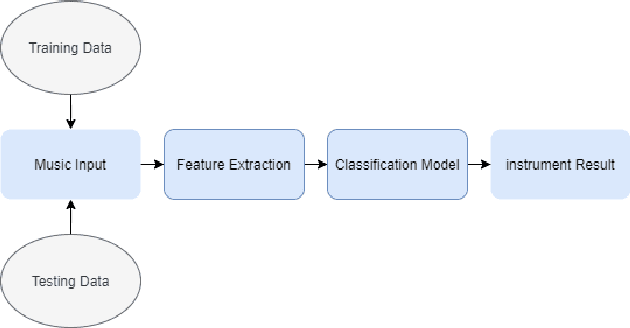
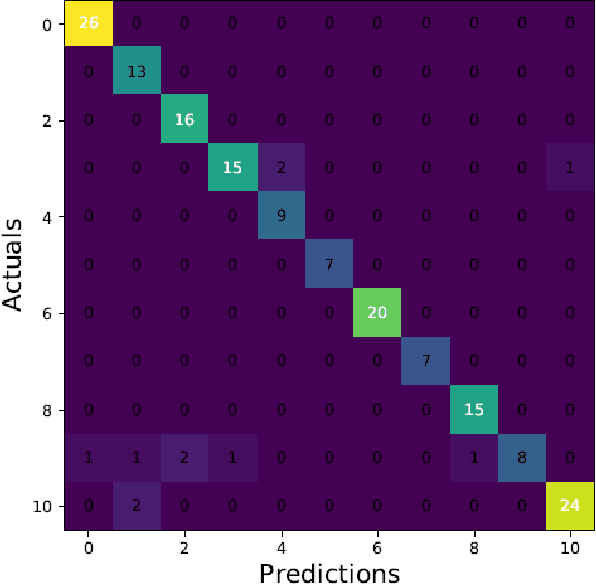
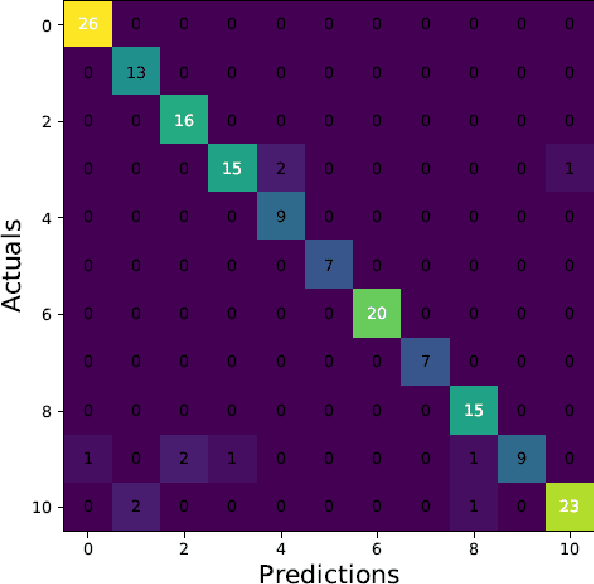
Musical instruments recognition is a widely used application for music information retrieval. As most of previous musical instruments recognition dataset focus on western musical instruments, it is difficult for researcher to study and evaluate the area of traditional Chinese musical instrument recognition. This paper propose a traditional Chinese music dataset for training model and performance evaluation, named ChMusic. This dataset is free and publicly available, 11 traditional Chinese musical instruments and 55 traditional Chinese music excerpts are recorded in this dataset. Then an evaluation standard is proposed based on ChMusic dataset. With this standard, researchers can compare their results following the same rule, and results from different researchers will become comparable.
A Bug or a Suggestion? An Automatic Way to Label Issues
Sep 03, 2019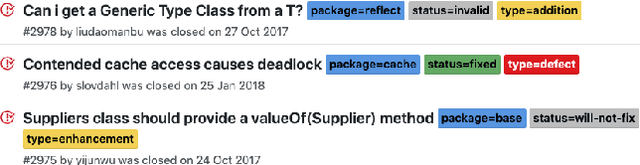
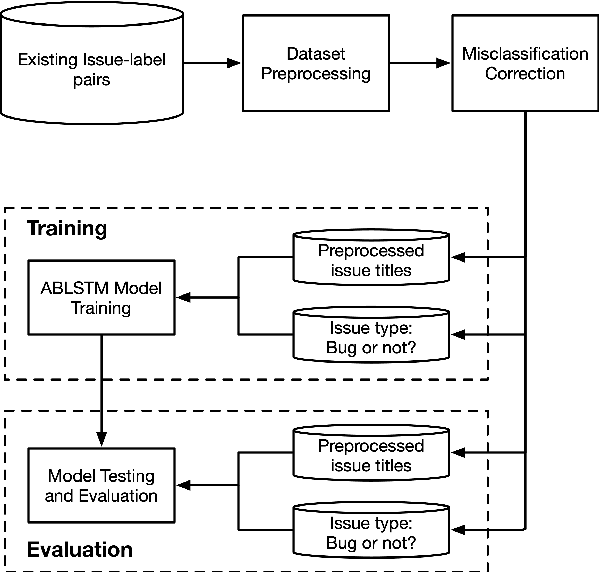
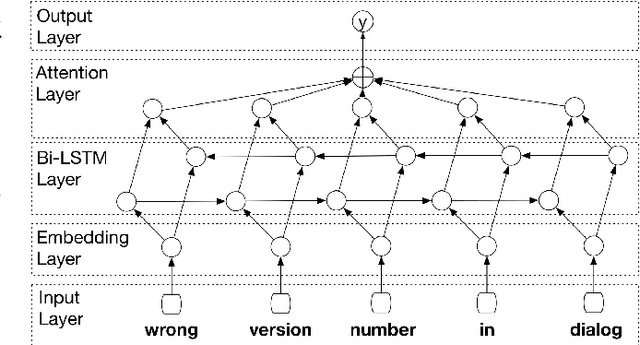
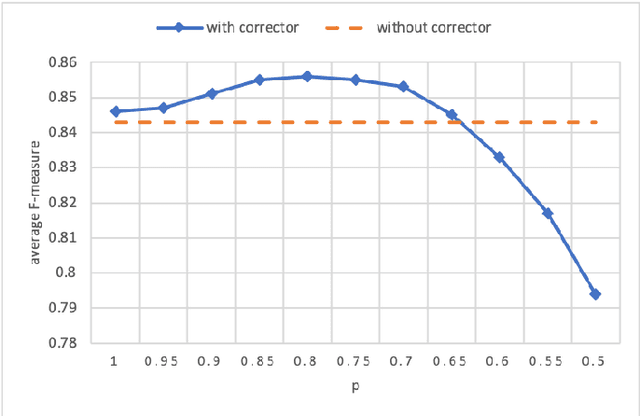
More and more users and developers are using Issue Tracking Systems (ITSs) to report issues, including bugs, feature requests, enhancement suggestions, etc. Different information, however, is gathered from users when issues are reported on different ITSs, which presents considerable challenges for issue classification tools to work effectively across the ITSs. Besides, bugs often take higher priority when it comes to classifying the issues, while existing approaches to issue classification seldom focus on distinguishing bugs and the other non-bug issues, leading to suboptimal accuracy in bug identification. In this paper, we propose a deep learning-based approach to automatically identify bug-reporting issues across various ITSs. The approach implements the k-NN algorithm to detect and correct misclassifications in data extracted from the ITSs, and trains an attention-based bi-directional long short-term memory (ABLSTM) network using a dataset of over 1.2 million labelled issues to identify bug reports. Experimental evaluation shows that our approach achieved an F-measure of 85.6\% in distinguishing bugs and other issues, significantly outperforming the other benchmark and state-of-the-art approaches examined in the experiment.