 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Based Reconstruction for Generalized Graph Signal Processing
Aug 14, 2023In generalized graph signal processing (GGSP), the signal associated with each vertex in a graph is an element from a Hilbert space. In this paper, we study GGSP signal reconstruction as a kernel ridge regression (KRR) problem. By devising an appropriate kernel, we show that this problem has a solution that can be evaluated in a distributed way. We interpret the problem and solution using both deterministic and Bayesian perspectives and link them to existing graph signal processing and GGSP frameworks. We then provide an online implementation via random Fourier features. Under the Bayesian framework, we investigate the statistical performance under the asymptotic sampling scheme. Finally, we validate our theory and methods on real-world datasets.
On the Learning of Digital Self-Interference Cancellation in Full-Duplex Radios
Aug 11, 2023



Full-duplex communication systems have the potential to achieve significantly higher data rates and lower latency compared to their half-duplex counterparts. This advantage stems from their ability to transmit and receive data simultaneously. However, to enable successful full-duplex operation, the primary challenge lies in accurately eliminating strong self-interference (SI). Overcoming this challenge involves addressing various issues, including the nonlinearity of power amplifiers, the time-varying nature of the SI channel, and the non-stationary transmit data distribution. In this article, we present a review of recent advancements in digital self-interference cancellation (SIC) algorithms. Our focus is on comparing the effectiveness of adaptable model-based SIC methods with their model-free counterparts that leverage data-driven machine learning techniques. Through our comparison study under practical scenarios, we demonstrate that the model-based SIC approach offers a more robust solution to the time-varying SI channel and the non-stationary transmission, achieving optimal SIC performance in terms of the convergence rate while maintaining low computational complexity. To validate our findings, we conduct experiments using a software-defined radio testbed that conforms to the IEEE 802.11a standards. The experimental results demonstrate the robustness of the model-based SIC methods, providing practical evidence of their effectiveness.
RIS-Aided Index Modulation with Greedy Detection over Rician Fading Channels
Jul 18, 2023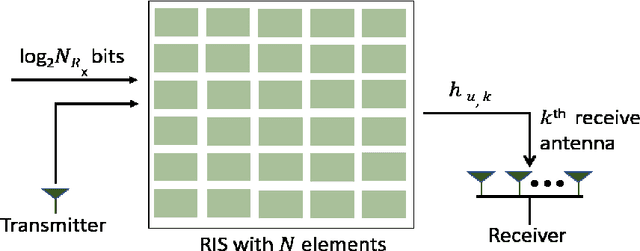
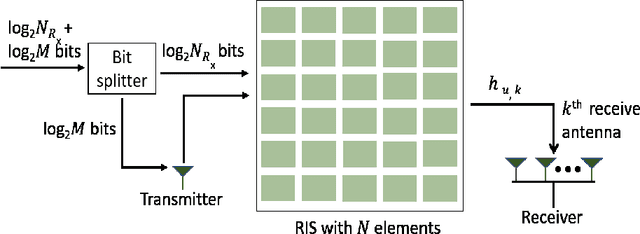
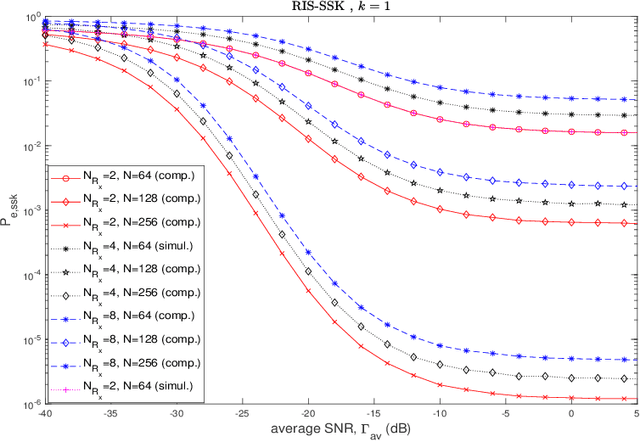
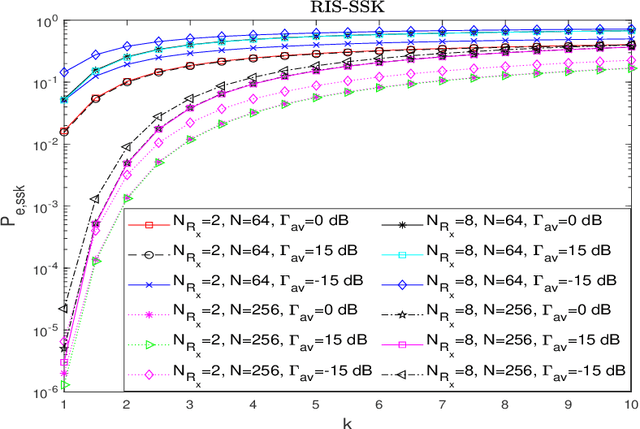
Index modulation schemes for reconfigurable intelligent surfaces (RIS)-assisted systems are envisioned as promising technologies for fifth-generation-advanced and sixth-generation (6G) wireless communication systems to enhance various system capabilities such as coverage area and network capacity. In this paper, we consider a receive diversity RIS-assisted wireless communication system employing IM schemes, namely, space-shift keying (SSK) for binary modulation and spatial modulation (SM) for M-ary modulation for data transmission. The RIS lies in close proximity to the transmitter, and the transmitted data is subjected to a fading environment with a prominent line-of-sight component modeled by a Rician distribution. A receiver structure based on a greedy detection rule is employed to select the receive diversity branch with the highest received signal energy for demodulation. The performance of the considered system is evaluated by obtaining a series-form expression for the probability of erroneous index detection (PED) of the considered target antenna using a characteristic function approach. In addition, closed-form and asymptotic expressions at high and low signal-to-noise ratios (SNRs) for the bit error rate (BER) for the SSK-based system, and the SM-based system employing M-ary phase-shift keying and M-ary quadrature amplitude modulation schemes, are derived. The dependencies of the system performance on the various parameters are corroborated via numerical results. The asymptotic expressions and results of PED and BER at high and low SNR values lead to the observation of a performance saturation and the presence of an SNR value as a point of inflection, which is attributed to the greedy detector's structure.
Model-Driven Sensing-Node Selection and Power Allocation for Tracking Maneuvering Targets in Perceptive Mobile Networks
Jul 11, 2023Maneuvering target tracking will be an important service of future wireless networks to assist innovative applications such as intelligent transportation. However, tracking maneuvering targets by cellular networks faces many challenges. For example, the dense network and high-speed targets make the selection of the sensing nodes (SNs), e.g., base stations, and the associated power allocation very difficult, given the stringent latency requirement of sensing applications. Existing methods have demonstrated engaging tracking performance, but with very high computational complexity. In this paper, we propose a model-driven deep learning approach for SN selection to meet the latency requirement. To this end, we first propose an iterative SN selection method by jointly exploiting the majorization-minimization (MM) framework and the alternating direction method of multipliers (ADMM). Then, we unfold the iterative algorithm as a deep neural network (DNN) and prove its convergence. The proposed model-driven method has a low computational complexity, because the number of layers is less than the number of iterations required by the original algorithm, and each layer only involves simple matrix-vector additions/multiplications. Finally, we propose an efficient power allocation method based on fixed point (FP) water filling (WF) and solve the joint SN selection and power allocation problem under the alternative optimization framework. Simulation results show that the proposed method achieves better performance than the conventional optimization-based methods with much lower computational complexity.
Joint Communications and Sensing Hybrid Beamforming Design via Deep Unfolding
Jul 10, 2023Joint communications and sensing (JCAS) is envisioned as a key feature in future wireless communications networks. In massive MIMO-JCAS systems, hybrid beamforming (HBF) is typically employed to achieve satisfactory beamforming gains with reasonable hardware cost and power consumption. Due to the coupling of the analog and digital precoders in HBF and the dual objective in JCAS, JCAS-HBF design problems are very challenging and usually require highly complex algorithms. In this paper, we propose a fast HBF design for JCAS based on deep unfolding to optimize a tradeoff between the communications rate and sensing accuracy. We first derive closed-form expressions for the gradients of the communications and sensing objectives with respect to the precoders and demonstrate that the magnitudes of the gradients pertaining to the analog precoder are typically smaller than those associated with the digital precoder. Based on this observation, we propose a modified projected gradient ascent (PGA) method with significantly improved convergence. We then develop a deep unfolded PGA scheme that efficiently optimizes the communications-sensing performance tradeoff with fast convergence thanks to the well-trained hyperparameters. In doing so, we preserve the interpretability and flexibility of the optimizer while leveraging data to improve performance. Finally, our simulations demonstrate the potential of the proposed deep unfolded method, which achieves up to 33.5% higher communications sum rate and 2.5 dB lower beampattern error compared with the conventional design based on successive convex approximation and Riemannian manifold optimization. Furthermore, it attains up to a 65% reduction in run time and computational complexity with respect to the PGA procedure without unfolding.
Near-Field Beamforming for STAR-RIS Networks
Jun 26, 2023



Recently, simultaneously transmitting and reflecting reconfigurable intelligent surfaces (STAR-RISs) have received significant research interest. The employment of large STAR-RIS and high-frequency signaling inevitably make the near-field propagation dominant in wireless communications. In this work, a STAR-RIS aided near-field multiple-input multiple-multiple (MIMO) communication framework is proposed. A weighted sum rate maximization problem for the joint optimization of the active beamforming at the base station (BS) and the transmission/reflection-coefficients (TRCs) at the STAR-RIS is formulated. The non-convex problem is solved by a block coordinate descent (BCD)-based algorithm. In particular, under given STAR-RIS TRCs, the optimal active beamforming matrices are obtained by solving a convex quadratically constrained quadratic program. For given active beamforming matrices, two algorithms are suggested for optimizing the STAR-RIS TRCs: a penalty-based iterative (PEN) algorithm and an element-wise iterative (ELE) algorithm. The latter algorithm is conceived for STAR-RISs with a large number of elements. Numerical results illustrate that: i) near-field beamforming for STAR-RIS aided MIMO communications significantly improves the achieved weighted sum rate compared with far-field beamforming; ii) the near-field channels facilitated by the STAR-RIS provide enhanced degrees-of-freedom and accessibility for the multi-user MIMO system; and iii) the BCD-PEN algorithm achieves better performance than the BCD-ELE algorithm, while the latter has a significantly lower computational complexity.
One-shot Learning for Channel Estimation in Massive MIMO Systems
Jun 09, 2023



In conventional supervised deep learning based channel estimation algorithms, a large number of training samples are required for offline training. However, in practical communication systems, it is difficult to obtain channel samples for every signal-to-noise ratio (SNR). Furthermore, the generalization ability of these deep neural networks (DNN) is typically poor. In this work, we propose a one-shot self-supervised learning framework for channel estimation in multi-input multi-output (MIMO) systems. The required number of samples for offline training is small and our approach can be directly deployed to adapt to variable channels. Our framework consists of a traditional channel estimation module and a denoising module. The denoising module is designed based on the one-shot learning method Self2Self and employs Bernoulli sampling to generate training labels. Besides,we further utilize a blind spot strategy and dropout technique to avoid overfitting. Simulation results show that the performance of the proposed one-shot self-supervised learning method is very close to the supervised learning approach while obtaining improved generalization ability for different channel environments.
Model-Based Deep Learning
Jun 05, 2023Signal processing traditionally relies on classical statistical modeling techniques. Such model-based methods utilize mathematical formulations that represent the underlying physics, prior information and additional domain knowledge. Simple classical models are useful but sensitive to inaccuracies and may lead to poor performance when real systems display complex or dynamic behavior. More recently, deep learning approaches that use deep neural networks are becoming increasingly popular. Deep learning systems do not rely on mathematical modeling, and learn their mapping from data, which allows them to operate in complex environments. However, they lack the interpretability and reliability of model-based methods, typically require large training sets to obtain good performance, and tend to be computationally complex. Model-based signal processing methods and data-centric deep learning each have their pros and cons. These paradigms can be characterized as edges of a continuous spectrum varying in specificity and parameterization. The methodologies that lie in the middle ground of this spectrum, thus integrating model-based signal processing with deep learning, are referred to as model-based deep learning, and are the focus here. This monograph provides a tutorial style presentation of model-based deep learning methodologies. These are families of algorithms that combine principled mathematical models with data-driven systems to benefit from the advantages of both approaches. Such model-based deep learning methods exploit both partial domain knowledge, via mathematical structures designed for specific problems, as well as learning from limited data. We accompany our presentation with running examples, in super-resolution, dynamic systems, and array processing. We show how they are expressed using the provided characterization and specialized in each of the detailed methodologies.
Spectrum Breathing: Protecting Over-the-Air Federated Learning Against Interference
May 10, 2023



Federated Learning (FL) is a widely embraced paradigm for distilling artificial intelligence from distributed mobile data. However, the deployment of FL in mobile networks can be compromised by exposure to interference from neighboring cells or jammers. Existing interference mitigation techniques require multi-cell cooperation or at least interference channel state information, which is expensive in practice. On the other hand, power control that treats interference as noise may not be effective due to limited power budgets, and also that this mechanism can trigger countermeasures by interference sources. As a practical approach for protecting FL against interference, we propose Spectrum Breathing, which cascades stochastic-gradient pruning and spread spectrum to suppress interference without bandwidth expansion. The cost is higher learning latency by exploiting the graceful degradation of learning speed due to pruning. We synchronize the two operations such that their levels are controlled by the same parameter, Breathing Depth. To optimally control the parameter, we develop a martingale-based approach to convergence analysis of Over-the-Air FL with spectrum breathing, termed AirBreathing FL. We show a performance tradeoff between gradient-pruning and interference-induced error as regulated by the breathing depth. Given receive SIR and model size, the optimization of the tradeoff yields two schemes for controlling the breathing depth that can be either fixed or adaptive to channels and the learning process. As shown by experiments, in scenarios where traditional Over-the-Air FL fails to converge in the presence of strong interference, AirBreahing FL with either fixed or adaptive breathing depth can ensure convergence where the adaptive scheme achieves close-to-ideal performance.
Generalization and Estimation Error Bounds for Model-based Neural Networks
Apr 19, 2023



Model-based neural networks provide unparalleled performance for various tasks, such as sparse coding and compressed sensing problems. Due to the strong connection with the sensing model, these networks are interpretable and inherit prior structure of the problem. In practice, model-based neural networks exhibit higher generalization capability compared to ReLU neural networks. However, this phenomenon was not addressed theoretically. Here, we leverage complexity measures including the global and local Rademacher complexities, in order to provide upper bounds on the generalization and estimation errors of model-based networks. We show that the generalization abilities of model-based networks for sparse recovery outperform those of regular ReLU networks, and derive practical design rules that allow to construct model-based networks with guaranteed high generalization. We demonstrate through a series of experiments that our theoretical insights shed light on a few behaviours experienced in practice, including the fact that ISTA and ADMM networks exhibit higher generalization abilities (especially for small number of training samples), compared to ReLU networks.