 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Universal Backward-Compatible Representation Learning
Mar 18, 2022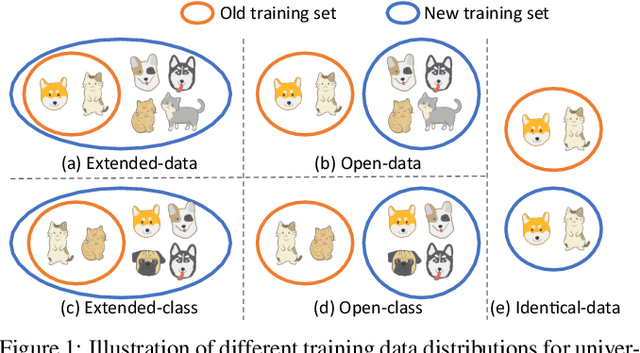
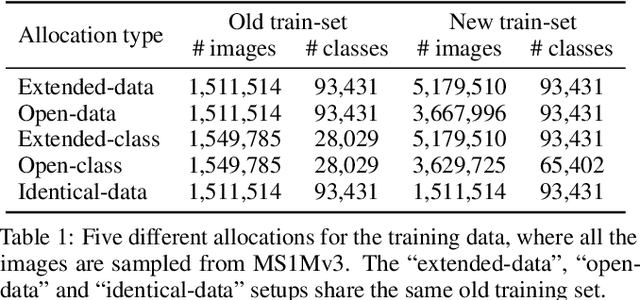
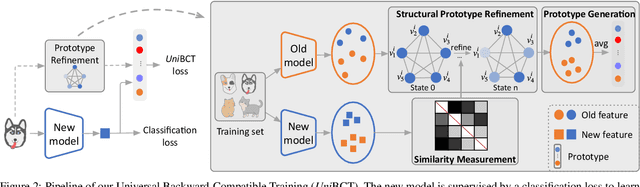
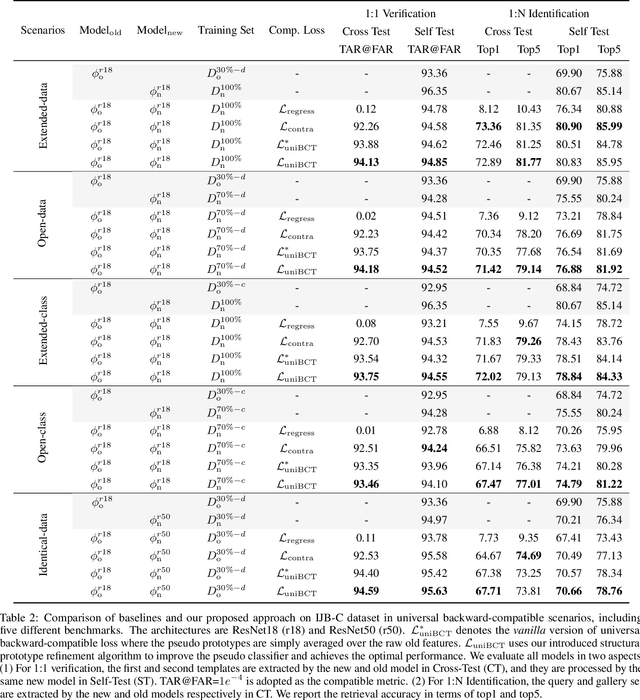
Conventional model upgrades for visual search systems require offline refresh of gallery features by feeding gallery images into new models (dubbed as "backfill"), which is time-consuming and expensive, especially in large-scale applications. The task of backward-compatible representation learning is therefore introduced to support backfill-free model upgrades, where the new query features are interoperable with the old gallery features. Despite the success, previous works only investigated a close-set training scenario (i.e., the new training set shares the same classes as the old one), and are limited by more realistic and challenging open-set scenarios. To this end, we first introduce a new problem of universal backward-compatible representation learning, covering all possible data split in model upgrades. We further propose a simple yet effective method, dubbed as Universal Backward-Compatible Training (UniBCT) with a novel structural prototype refinement algorithm, to learn compatible representations in all kinds of model upgrading benchmarks in a unified manner. Comprehensive experiments on the large-scale face recognition datasets MS1Mv3 and IJB-C fully demonstrate the effectiveness of our method.
Self-supervised Learning of Detailed 3D Face Reconstruction
Oct 25, 2019
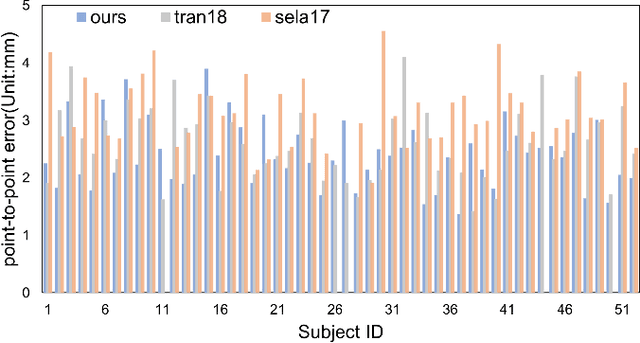
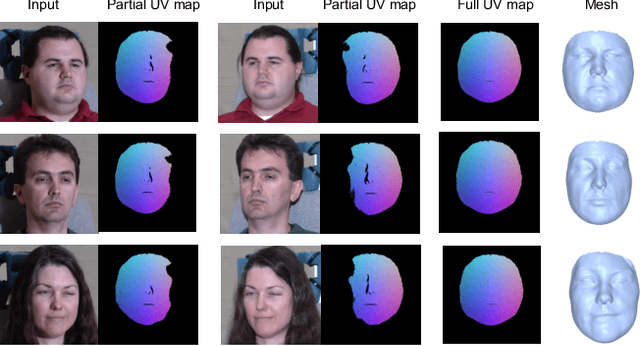

In this paper, we present an end-to-end learning framework for detailed 3D face reconstruction from a single image. Our approach uses a 3DMM-based coarse model and a displacement map in UV-space to represent a 3D face. Unlike previous work addressing the problem, our learning framework does not require supervision of surrogate ground-truth 3D models computed with traditional approaches. Instead, we utilize the input image itself as supervision during learning. In the first stage, we combine a photometric loss and a facial perceptual loss between the input face and the rendered face, to regress a 3DMM-based coarse model. In the second stage, both the input image and the regressed texture of the coarse model are unwrapped into UV-space, and then sent through an image-toimage translation network to predict a displacement map in UVspace. The displacement map and the coarse model are used to render a final detailed face, which again can be compared with the original input image to serve as a photometric loss for the second stage. The advantage of learning displacement map in UV-space is that face alignment can be explicitly done during the unwrapping, thus facial details are easier to learn from large amount of data. Extensive experiments demonstrate the superiority of the proposed method over previous work.
MVF-Net: Multi-View 3D Face Morphable Model Regression
Apr 09, 2019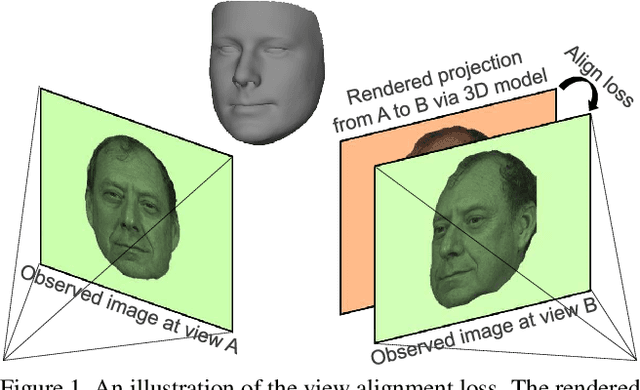
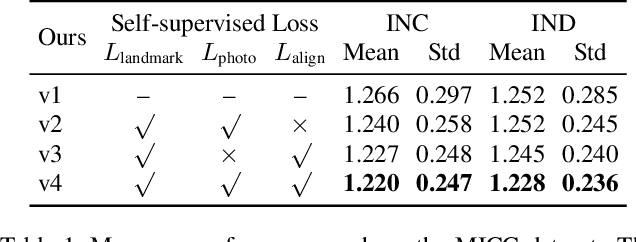
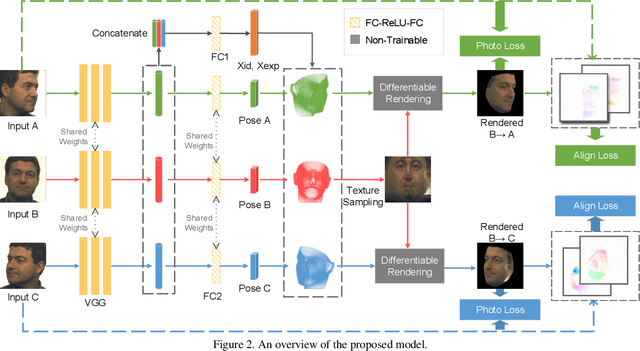
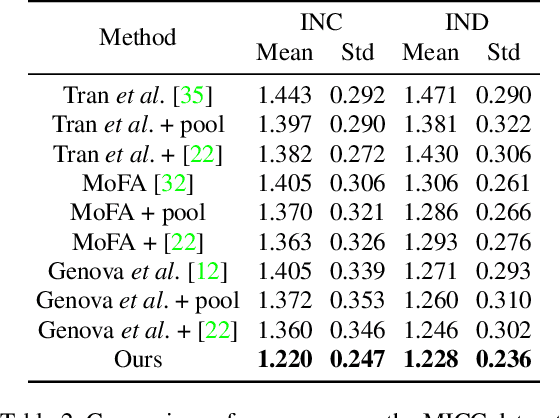
We address the problem of recovering the 3D geometry of a human face from a set of facial images in multiple views. While recent studies have shown impressive progress in 3D Morphable Model (3DMM) based facial reconstruction, the settings are mostly restricted to a single view. There is an inherent drawback in the single-view setting: the lack of reliable 3D constraints can cause unresolvable ambiguities. We in this paper explore 3DMM-based shape recovery in a different setting, where a set of multi-view facial images are given as input. A novel approach is proposed to regress 3DMM parameters from multi-view inputs with an end-to-end trainable Convolutional Neural Network (CNN). Multiview geometric constraints are incorporated into the network by establishing dense correspondences between different views leveraging a novel self-supervised view alignment loss. The main ingredient of the view alignment loss is a differentiable dense optical flow estimator that can backpropagate the alignment errors between an input view and a synthetic rendering from another input view, which is projected to the target view through the 3D shape to be inferred. Through minimizing the view alignment loss, better 3D shapes can be recovered such that the synthetic projections from one view to another can better align with the observed image. Extensive experiments demonstrate the superiority of the proposed method over other 3DMM methods.
3D Facial Expression Reconstruction using Cascaded Regression
Aug 17, 2018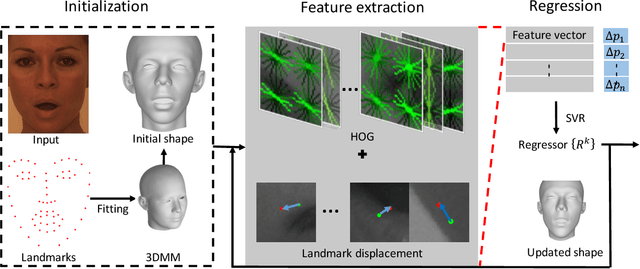
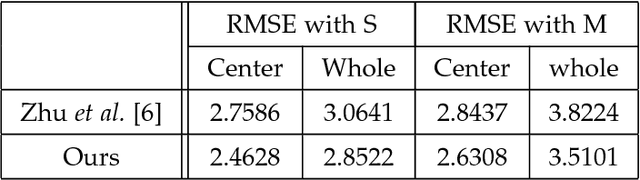
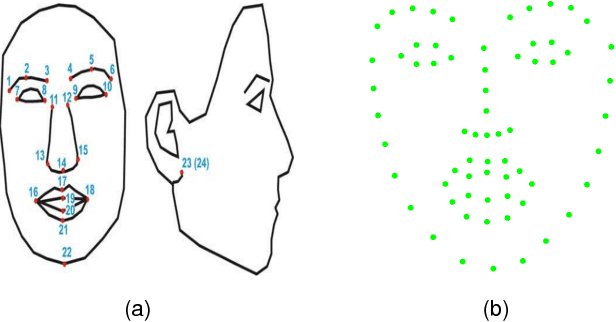
This paper proposes a novel model fitting algorithm for 3D facial expression reconstruction from a single image. Face expression reconstruction from a single image is a challenging task in computer vision. Most state-of-the-art methods fit the input image to a 3D Morphable Model (3DMM). These methods need to solve a stochastic problem and cannot deal with expression and pose variations. To solve this problem, we adopt a 3D face expression model and use a combined feature which is robust to scale, rotation and different lighting conditions. The proposed method applies a cascaded regression framework to estimate parameters for the 3DMM. 2D landmarks are detected and used to initialize the 3D shape and mapping matrices. In each iteration, residues between the current 3DMM parameters and the ground truth are estimated and then used to update the 3D shapes. The mapping matrices are also calculated based on the updated shapes and 2D landmarks. HOG features of the local patches and displacements between 3D landmark projections and 2D landmarks are exploited. Compared with existing methods, the proposed method is robust to expression and pose changes and can reconstruct higher fidelity 3D face shape.