 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAS: Towards Resource-Efficient Federated Multiple-Task Learning
Jul 21, 2023



Federated learning (FL) is an emerging distributed machine learning method that empowers in-situ model training on decentralized edge devices. However, multiple simultaneous FL tasks could overload resource-constrained devices. In this work, we propose the first FL system to effectively coordinate and train multiple simultaneous FL tasks. We first formalize the problem of training simultaneous FL tasks. Then, we present our new approach, MAS (Merge and Split), to optimize the performance of training multiple simultaneous FL tasks. MAS starts by merging FL tasks into an all-in-one FL task with a multi-task architecture. After training for a few rounds, MAS splits the all-in-one FL task into two or more FL tasks by using the affinities among tasks measured during the all-in-one training. It then continues training each split of FL tasks based on model parameters from the all-in-one training. Extensive experiments demonstrate that MAS outperforms other methods while reducing training time by 2x and reducing energy consumption by 40%. We hope this work will inspire the community to further study and optimize training simultaneous FL tasks.
FHA-Kitchens: A Novel Dataset for Fine-Grained Hand Action Recognition in Kitchen Scenes
Jun 19, 2023



A typical task in the field of video understanding is hand action recognition, which has a wide range of applications. Existing works either mainly focus on full-body actions, or the defined action categories are relatively coarse-grained. In this paper, we propose FHA-Kitchens, a novel dataset of fine-grained hand actions in kitchen scenes. In particular, we focus on human hand interaction regions and perform deep excavation to further refine hand action information and interaction regions. Our FHA-Kitchens dataset consists of 2,377 video clips and 30,047 images collected from 8 different types of dishes, and all hand interaction regions in each image are labeled with high-quality fine-grained action classes and bounding boxes. We represent the action information in each hand interaction region as a triplet, resulting in a total of 878 action triplets. Based on the constructed dataset, we benchmark representative action recognition and detection models on the following three tracks: (1) supervised learning for hand interaction region and object detection, (2) supervised learning for fine-grained hand action recognition, and (3) intra- and inter-class domain generalization for hand interaction region detection. The experimental results offer compelling empirical evidence that highlights the challenges inherent in fine-grained hand action recognition, while also shedding light on potential avenues for future research, particularly in relation to pre-training strategy, model design, and domain generalization. The dataset will be released at https://github.com/tingZ123/FHA-Kitchens.
Boosting Distributed Full-graph GNN Training with Asynchronous One-bit Communication
Mar 02, 2023



Training Graph Neural Networks (GNNs) on large graphs is challenging due to the conflict between the high memory demand and limited GPU memory. Recently, distributed full-graph GNN training has been widely adopted to tackle this problem. However, the substantial inter-GPU communication overhead can cause severe throughput degradation. Existing communication compression techniques mainly focus on traditional DNN training, whose bottleneck lies in synchronizing gradients and parameters. We find they do not work well in distributed GNN training as the barrier is the layer-wise communication of features during the forward pass & feature gradients during the backward pass. To this end, we propose an efficient distributed GNN training framework Sylvie, which employs one-bit quantization technique in GNNs and further pipelines the curtailed communication with computation to enormously shrink the overhead while maintaining the model quality. In detail, Sylvie provides a lightweight Low-bit Module to quantize the sent data and dequantize the received data back to full precision values in each layer. Additionally, we propose a Bounded Staleness Adaptor to control the introduced staleness to achieve further performance enhancement. We conduct theoretical convergence analysis and extensive experiments on various models & datasets to demonstrate Sylvie can considerably boost the training throughput by up to 28.1x.
FedABC: Targeting Fair Competition in Personalized Federated Learning
Feb 15, 2023Federated learning aims to collaboratively train models without accessing their client's local private data. The data may be Non-IID for different clients and thus resulting in poor performance. Recently, personalized federated learning (PFL) has achieved great success in handling Non-IID data by enforcing regularization in local optimization or improving the model aggregation scheme on the server. However, most of the PFL approaches do not take into account the unfair competition issue caused by the imbalanced data distribution and lack of positive samples for some classes in each client. To address this issue, we propose a novel and generic PFL framework termed Federated Averaging via Binary Classification, dubbed FedABC. In particular, we adopt the ``one-vs-all'' training strategy in each client to alleviate the unfair competition between classes by constructing a personalized binary classification problem for each class. This may aggravate the class imbalance challenge and thus a novel personalized binary classification loss that incorporates both the under-sampling and hard sample mining strategies is designed. Extensive experiments are conducted on two popular datasets under different settings, and the results demonstrate that our FedABC can significantly outperform the existing counterparts.
* 9 pages,5 figures
Toward Efficient Language Model Pretraining and Downstream Adaptation via Self-Evolution: A Case Study on SuperGLUE
Dec 04, 2022



This technical report briefly describes our JDExplore d-team's Vega v2 submission on the SuperGLUE leaderboard. SuperGLUE is more challenging than the widely used general language understanding evaluation (GLUE) benchmark, containing eight difficult language understanding tasks, including question answering, natural language inference, word sense disambiguation, coreference resolution, and reasoning. [Method] Instead of arbitrarily increasing the size of a pretrained language model (PLM), our aim is to 1) fully extract knowledge from the input pretraining data given a certain parameter budget, e.g., 6B, and 2) effectively transfer this knowledge to downstream tasks. To achieve goal 1), we propose self-evolution learning for PLMs to wisely predict the informative tokens that should be masked, and supervise the masked language modeling (MLM) process with rectified smooth labels. For goal 2), we leverage the prompt transfer technique to improve the low-resource tasks by transferring the knowledge from the foundation model and related downstream tasks to the target task. [Results] According to our submission record (Oct. 2022), with our optimized pretraining and fine-tuning strategies, our 6B Vega method achieved new state-of-the-art performance on 4/8 tasks, sitting atop the SuperGLUE leaderboard on Oct. 8, 2022, with an average score of 91.3.
Machine Learning for a Sustainable Energy Future
Oct 19, 2022Transitioning from fossil fuels to renewable energy sources is a critical global challenge; it demands advances at the levels of materials, devices, and systems for the efficient harvesting, storage, conversion, and management of renewable energy. Researchers globally have begun incorporating machine learning (ML) techniques with the aim of accelerating these advances. ML technologies leverage statistical trends in data to build models for prediction of material properties, generation of candidate structures, optimization of processes, among other uses; as a result, they can be incorporated into discovery and development pipelines to accelerate progress. Here we review recent advances in ML-driven energy research, outline current and future challenges, and describe what is required moving forward to best lever ML techniques. To start, we give an overview of key ML concepts. We then introduce a set of key performance indicators to help compare the benefits of different ML-accelerated workflows for energy research. We discuss and evaluate the latest advances in applying ML to the development of energy harvesting (photovoltaics), storage (batteries), conversion (electrocatalysis), and management (smart grids). Finally, we offer an outlook of potential research areas in the energy field that stand to further benefit from the application of ML.
Not All Instances Contribute Equally: Instance-adaptive Class Representation Learning for Few-Shot Visual Recognition
Sep 07, 2022
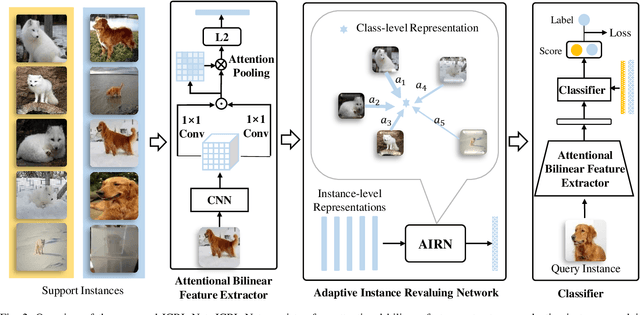
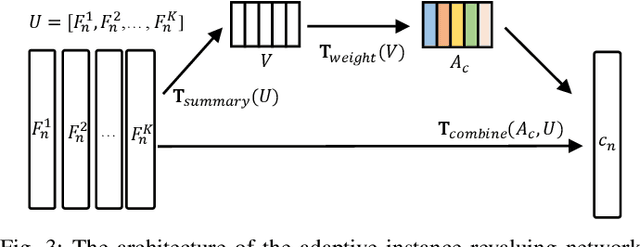
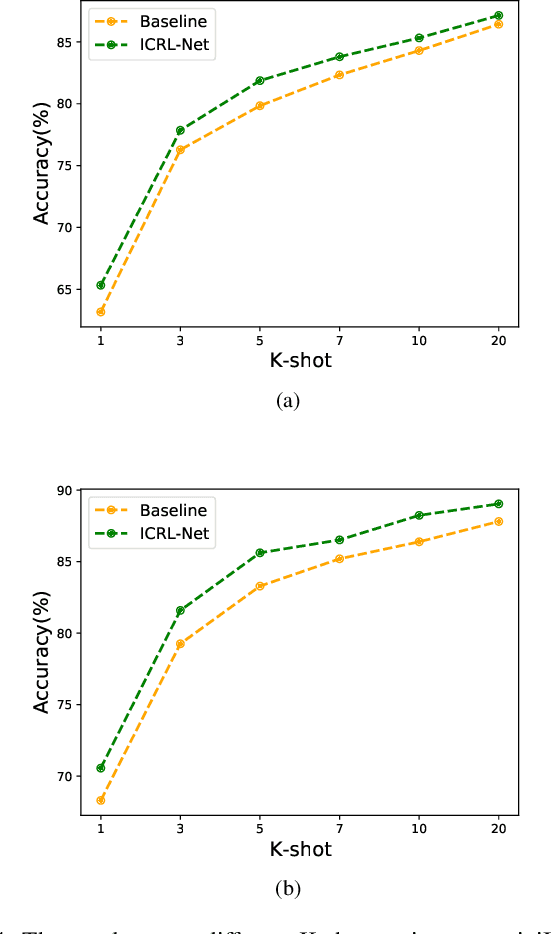
Few-shot visual recognition refers to recognize novel visual concepts from a few labeled instances. Many few-shot visual recognition methods adopt the metric-based meta-learning paradigm by comparing the query representation with class representations to predict the category of query instance. However, current metric-based methods generally treat all instances equally and consequently often obtain biased class representation, considering not all instances are equally significant when summarizing the instance-level representations for the class-level representation. For example, some instances may contain unrepresentative information, such as too much background and information of unrelated concepts, which skew the results. To address the above issues, we propose a novel metric-based meta-learning framework termed instance-adaptive class representation learning network (ICRL-Net) for few-shot visual recognition. Specifically, we develop an adaptive instance revaluing network with the capability to address the biased representation issue when generating the class representation, by learning and assigning adaptive weights for different instances according to their relative significance in the support set of corresponding class. Additionally, we design an improved bilinear instance representation and incorporate two novel structural losses, i.e., intra-class instance clustering loss and inter-class representation distinguishing loss, to further regulate the instance revaluation process and refine the class representation. We conduct extensive experiments on four commonly adopted few-shot benchmarks: miniImageNet, tieredImageNet, CIFAR-FS, and FC100 datasets. The experimental results compared with the state-of-the-art approaches demonstrate the superiority of our ICRL-Net.
Smart Multi-tenant Federated Learning
Jul 09, 2022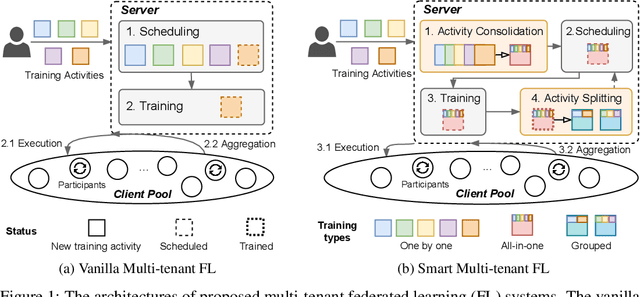
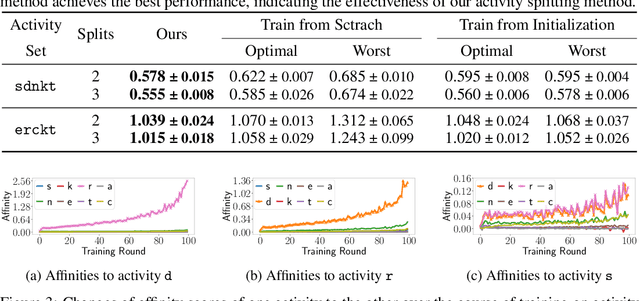
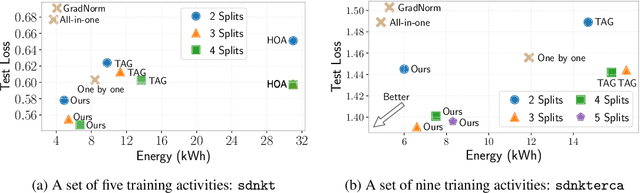
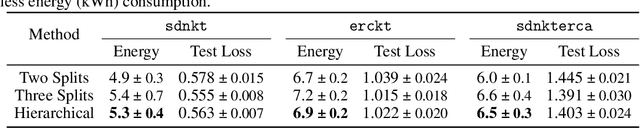
Federated learning (FL) is an emerging distributed machine learning method that empowers in-situ model training on decentralized edge devices. However, multiple simultaneous training activities could overload resource-constrained devices. In this work, we propose a smart multi-tenant FL system, MuFL, to effectively coordinate and execute simultaneous training activities. We first formalize the problem of multi-tenant FL, define multi-tenant FL scenarios, and introduce a vanilla multi-tenant FL system that trains activities sequentially to form baselines. Then, we propose two approaches to optimize multi-tenant FL: 1) activity consolidation merges training activities into one activity with a multi-task architecture; 2) after training it for rounds, activity splitting divides it into groups by employing affinities among activities such that activities within a group have better synergy. Extensive experiments demonstrate that MuFL outperforms other methods while consuming 40% less energy. We hope this work will inspire the community to further study and optimize multi-tenant FL.
Deep Learning Workload Scheduling in GPU Datacenters: Taxonomy, Challenges and Vision
Jun 01, 2022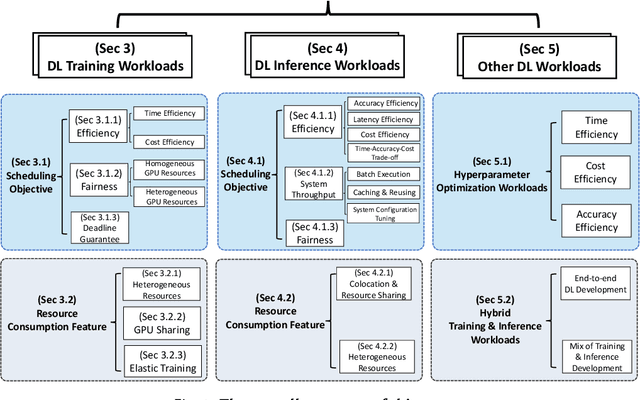
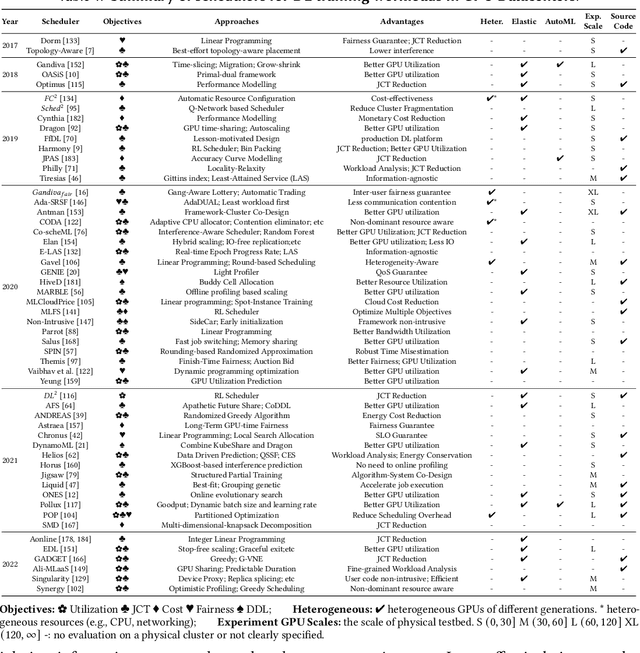
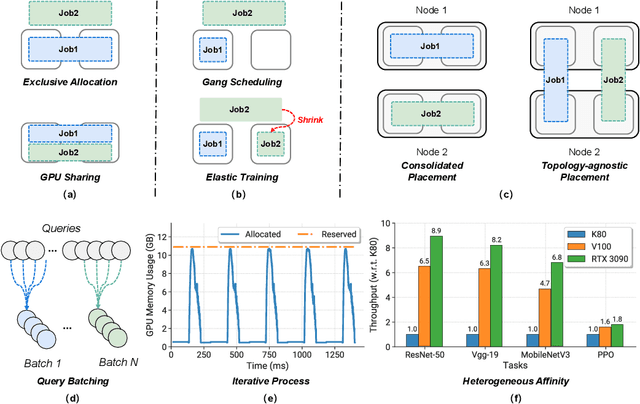

Deep learning (DL) shows its prosperity in a wide variety of fields. The development of a DL model is a time-consuming and resource-intensive procedure. Hence, dedicated GPU accelerators have been collectively constructed into a GPU datacenter. An efficient scheduler design for such GPU datacenter is crucially important to reduce the operational cost and improve resource utilization. However, traditional approaches designed for big data or high performance computing workloads can not support DL workloads to fully utilize the GPU resources. Recently, substantial schedulers are proposed to tailor for DL workloads in GPU datacenters. This paper surveys existing research efforts for both training and inference workloads. We primarily present how existing schedulers facilitate the respective workloads from the scheduling objectives and resource consumption features. Finally, we prospect several promising future research directions. More detailed summary with the surveyed paper and code links can be found at our project website: https://github.com/S-Lab-System-Group/Awesome-DL-Scheduling-Papers
Optimizing Performance of Federated Person Re-identification: Benchmarking and Analysis
May 24, 2022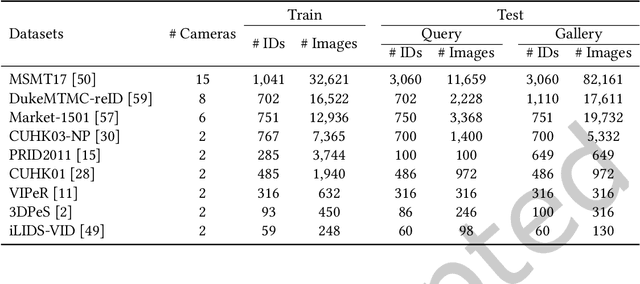
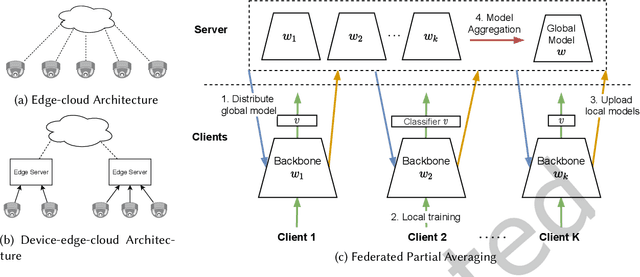
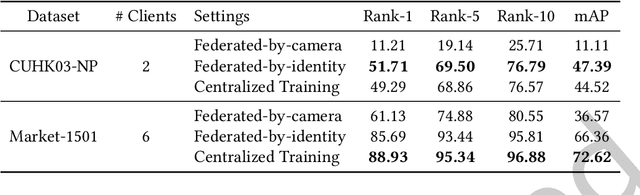
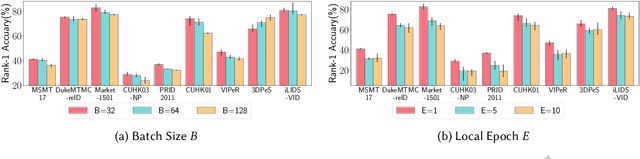
The increasingly stringent data privacy regulations limit the development of person re-identification (ReID) because person ReID training requires centralizing an enormous amount of data that contains sensitive personal information. To address this problem, we introduce federated person re-identification (FedReID) -- implementing federated learning, an emerging distributed training method, to person ReID. FedReID preserves data privacy by aggregating model updates, instead of raw data, from clients to a central server. Furthermore, we optimize the performance of FedReID under statistical heterogeneity via benchmark analysis. We first construct a benchmark with an enhanced algorithm, two architectures, and nine person ReID datasets with large variances to simulate the real-world statistical heterogeneity. The benchmark results present insights and bottlenecks of FedReID under statistical heterogeneity, including challenges in convergence and poor performance on datasets with large volumes. Based on these insights, we propose three optimization approaches: (1) We adopt knowledge distillation to facilitate the convergence of FedReID by better transferring knowledge from clients to the server; (2) We introduce client clustering to improve the performance of large datasets by aggregating clients with similar data distributions; (3) We propose cosine distance weight to elevate performance by dynamically updating the weights for aggregation depending on how well models are trained in clients. Extensive experiments demonstrate that these approaches achieve satisfying convergence with much better performance on all datasets. We believe that FedReID will shed light on implementing and optimizing federated learning on more computer vision applications.