 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYong-Jin Liu
Indoor Scene Reconstruction with Fine-Grained Details Using Hybrid Representation and Normal Prior Enhancement
Sep 14, 2023
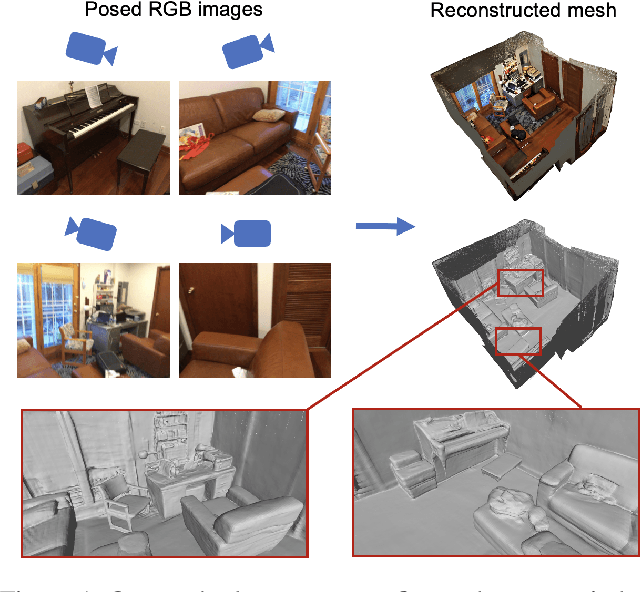
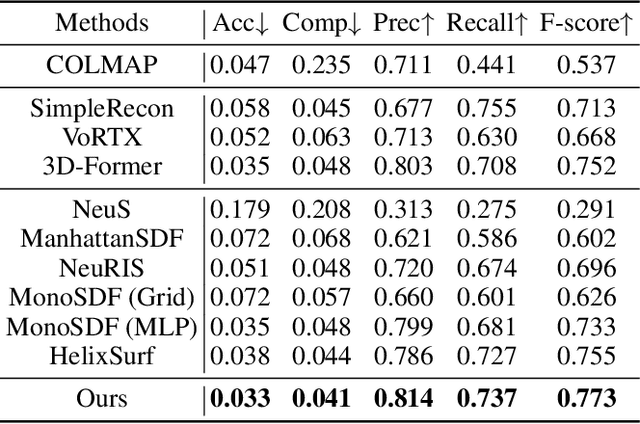
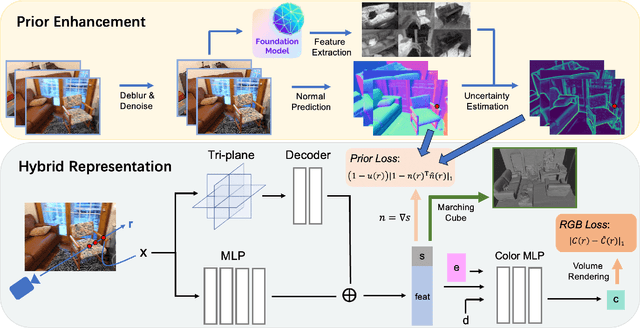
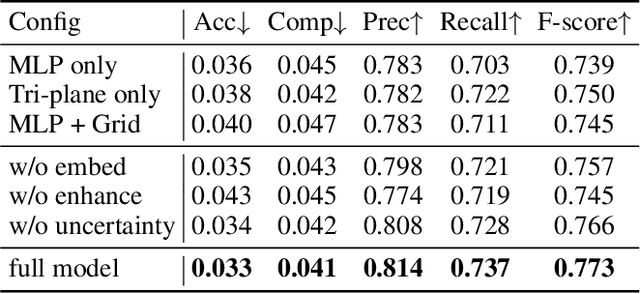
The reconstruction of indoor scenes from multi-view RGB images is challenging due to the coexistence of flat and texture-less regions alongside delicate and fine-grained regions. Recent methods leverage neural radiance fields aided by predicted surface normal priors to recover the scene geometry. These methods excel in producing complete and smooth results for floor and wall areas. However, they struggle to capture complex surfaces with high-frequency structures due to the inadequate neural representation and the inaccurately predicted normal priors. To improve the capacity of the implicit representation, we propose a hybrid architecture to represent low-frequency and high-frequency regions separately. To enhance the normal priors, we introduce a simple yet effective image sharpening and denoising technique, coupled with a network that estimates the pixel-wise uncertainty of the predicted surface normal vectors. Identifying such uncertainty can prevent our model from being misled by unreliable surface normal supervisions that hinder the accurate reconstruction of intricate geometries. Experiments on the benchmark datasets show that our method significantly outperforms existing methods in terms of reconstruction quality.
ExpeL: LLM Agents Are Experiential Learners
Aug 20, 2023The recent surge in research interest in applying large language models (LLMs) to decision-making tasks has flourished by leveraging the extensive world knowledge embedded in LLMs. While there is a growing demand to tailor LLMs for custom decision-making tasks, finetuning them for specific tasks is resource-intensive and may diminish the model's generalization capabilities. Moreover, state-of-the-art language models like GPT-4 and Claude are primarily accessible through API calls, with their parametric weights remaining proprietary and unavailable to the public. This scenario emphasizes the growing need for new methodologies that allow learning from agent experiences without requiring parametric updates. To address these problems, we introduce the Experiential Learning (ExpeL) agent. Our agent autonomously gathers experiences and extracts knowledge using natural language from a collection of training tasks. At inference, the agent recalls its extracted insights and past experiences to make informed decisions. Our empirical results highlight the robust learning efficacy of the ExpeL agent, indicating a consistent enhancement in its performance as it accumulates experiences. We further explore the emerging capabilities and transfer learning potential of the ExpeL agent through qualitative observations and additional experiments.
O^2-Recon: Completing 3D Reconstruction of Occluded Objects in the Scene with a Pre-trained 2D Diffusion Model
Aug 18, 2023Occlusion is a common issue in 3D reconstruction from RGB-D videos, often blocking the complete reconstruction of objects and presenting an ongoing problem. In this paper, we propose a novel framework, empowered by a 2D diffusion-based in-painting model, to reconstruct complete surfaces for the hidden parts of objects. Specifically, we utilize a pre-trained diffusion model to fill in the hidden areas of 2D images. Then we use these in-painted images to optimize a neural implicit surface representation for each instance for 3D reconstruction. Since creating the in-painting masks needed for this process is tricky, we adopt a human-in-the-loop strategy that involves very little human engagement to generate high-quality masks. Moreover, some parts of objects can be totally hidden because the videos are usually shot from limited perspectives. To ensure recovering these invisible areas, we develop a cascaded network architecture for predicting signed distance field, making use of different frequency bands of positional encoding and maintaining overall smoothness. Besides the commonly used rendering loss, Eikonal loss, and silhouette loss, we adopt a CLIP-based semantic consistency loss to guide the surface from unseen camera angles. Experiments on ScanNet scenes show that our proposed framework achieves state-of-the-art accuracy and completeness in object-level reconstruction from scene-level RGB-D videos.
Efficient Semantic Segmentation by Altering Resolutions for Compressed Videos
Mar 13, 2023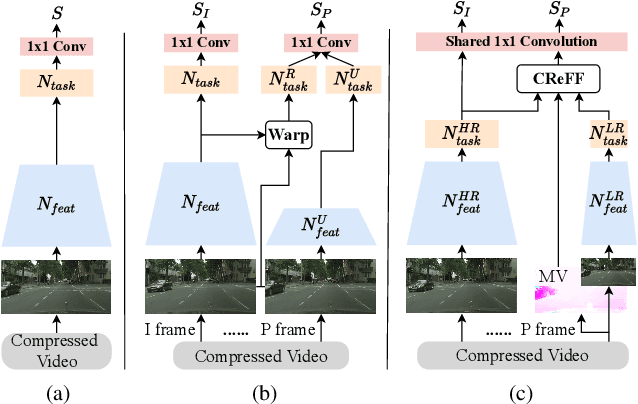
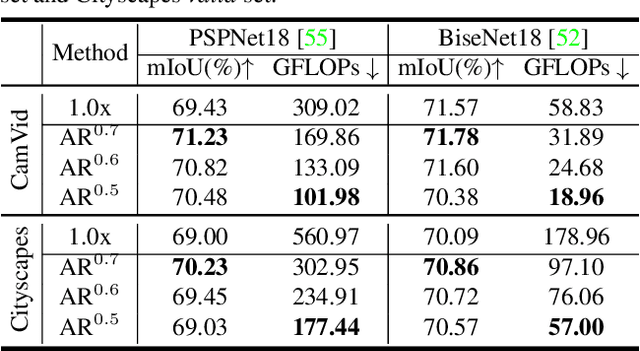
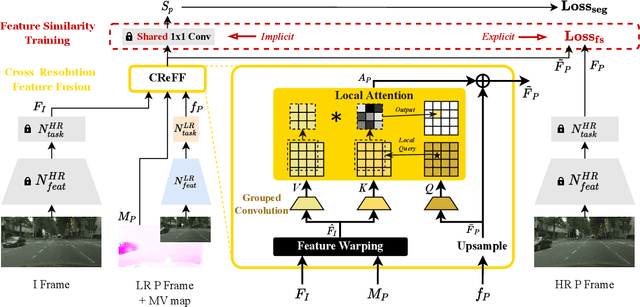
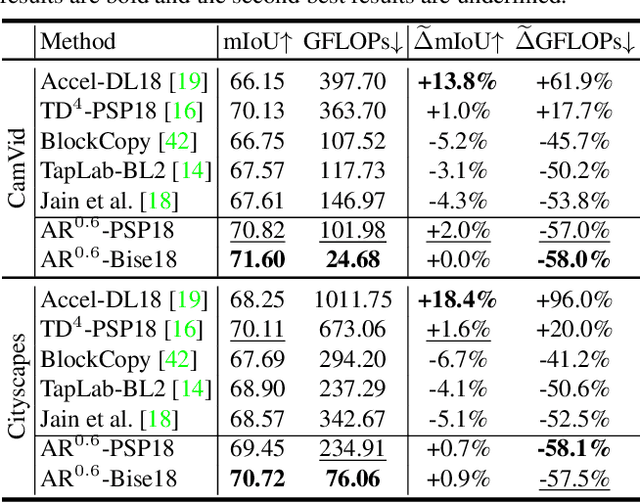
Video semantic segmentation (VSS) is a computationally expensive task due to the per-frame prediction for videos of high frame rates. In recent work, compact models or adaptive network strategies have been proposed for efficient VSS. However, they did not consider a crucial factor that affects the computational cost from the input side: the input resolution. In this paper, we propose an altering resolution framework called AR-Seg for compressed videos to achieve efficient VSS. AR-Seg aims to reduce the computational cost by using low resolution for non-keyframes. To prevent the performance degradation caused by downsampling, we design a Cross Resolution Feature Fusion (CReFF) module, and supervise it with a novel Feature Similarity Training (FST) strategy. Specifically, CReFF first makes use of motion vectors stored in a compressed video to warp features from high-resolution keyframes to low-resolution non-keyframes for better spatial alignment, and then selectively aggregates the warped features with local attention mechanism. Furthermore, the proposed FST supervises the aggregated features with high-resolution features through an explicit similarity loss and an implicit constraint from the shared decoding layer. Extensive experiments on CamVid and Cityscapes show that AR-Seg achieves state-of-the-art performance and is compatible with different segmentation backbones. On CamVid, AR-Seg saves 67% computational cost (measured in GFLOPs) with the PSPNet18 backbone while maintaining high segmentation accuracy. Code: https://github.com/THU-LYJ-Lab/AR-Seg.
A Mixture of Surprises for Unsupervised Reinforcement Learning
Oct 13, 2022
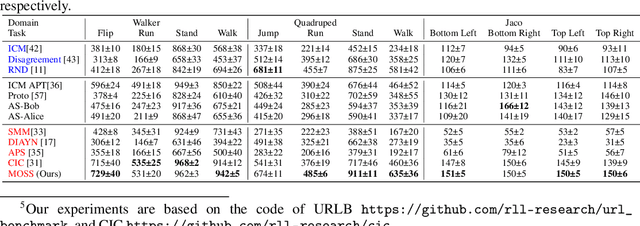


Unsupervised reinforcement learning aims at learning a generalist policy in a reward-free manner for fast adaptation to downstream tasks. Most of the existing methods propose to provide an intrinsic reward based on surprise. Maximizing or minimizing surprise drives the agent to either explore or gain control over its environment. However, both strategies rely on a strong assumption: the entropy of the environment's dynamics is either high or low. This assumption may not always hold in real-world scenarios, where the entropy of the environment's dynamics may be unknown. Hence, choosing between the two objectives is a dilemma. We propose a novel yet simple mixture of policies to address this concern, allowing us to optimize an objective that simultaneously maximizes and minimizes the surprise. Concretely, we train one mixture component whose objective is to maximize the surprise and another whose objective is to minimize the surprise. Hence, our method does not make assumptions about the entropy of the environment's dynamics. We call our method a $\textbf{M}\text{ixture }\textbf{O}\text{f }\textbf{S}\text{urprise}\textbf{S}$ (MOSS) for unsupervised reinforcement learning. Experimental results show that our simple method achieves state-of-the-art performance on the URLB benchmark, outperforming previous pure surprise maximization-based objectives. Our code is available at: https://github.com/LeapLabTHU/MOSS.
KRF: Keypoint Refinement with Fusion Network for 6D Pose Estimation
Oct 07, 2022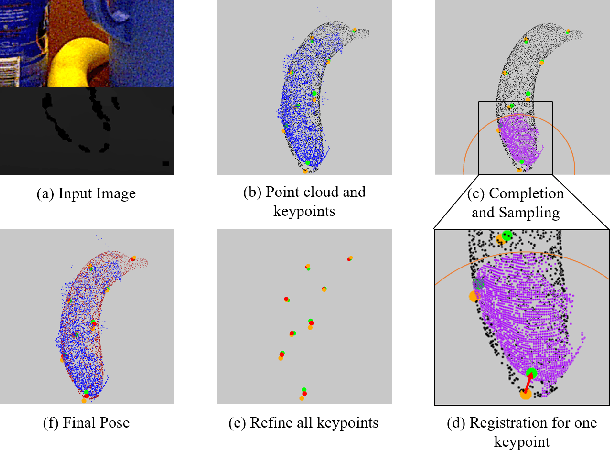
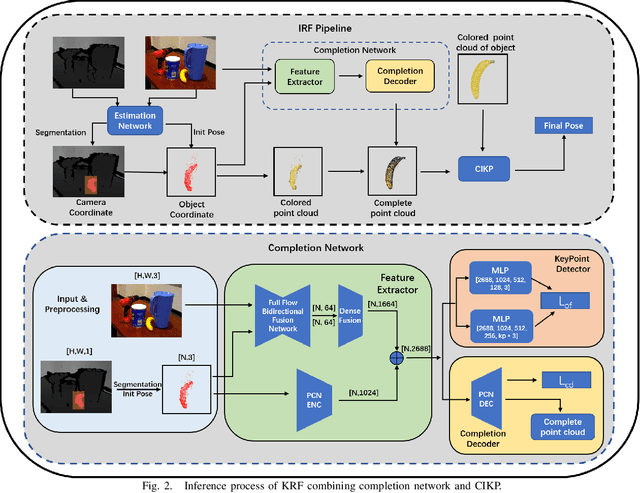

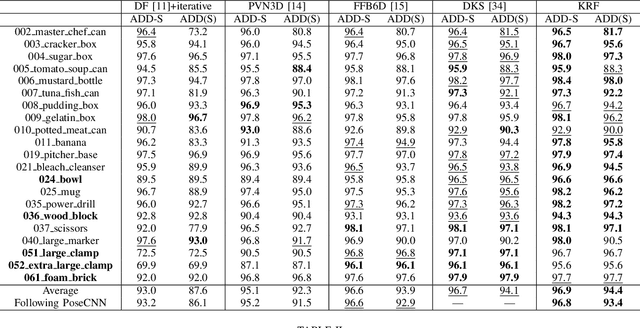
Existing refinement methods gradually lose their ability to further improve pose estimation methods' accuracy. In this paper, we propose a new refinement pipeline, Keypoint Refinement with Fusion Network (KRF), for 6D pose estimation, especially for objects with serious occlusion. The pipeline consists of two steps. It first completes the input point clouds via a novel point completion network. The network uses both local and global features, considering the pose information during point completion. Then, it registers the completed object point cloud with corresponding target point cloud by Color supported Iterative KeyPoint (CIKP). The CIKP method introduces color information into registration and registers point cloud around each keypoint to increase stability. The KRF pipeline can be integrated with existing popular 6D pose estimation methods, e.g. the full flow bidirectional fusion network, to further improved their pose estimation accuracy. Experiments show that our method outperforms the state-of-the-art method from 93.9\% to 94.4\% on YCB-Video dataset and from 64.4\% to 66.8\% on Occlusion LineMOD dataset. Our source code is available at https://github.com/zhanhz/KRF.
Continuously Controllable Facial Expression Editing in Talking Face Videos
Sep 17, 2022
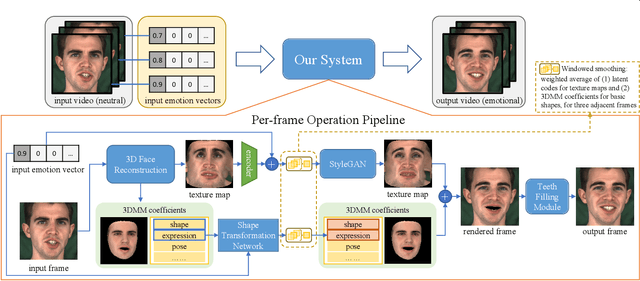
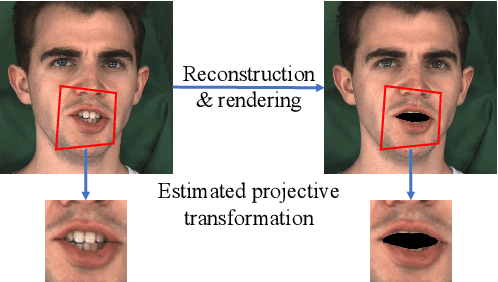

Recently audio-driven talking face video generation has attracted considerable attention. However, very few researches address the issue of emotional editing of these talking face videos with continuously controllable expressions, which is a strong demand in the industry. The challenge is that speech-related expressions and emotion-related expressions are often highly coupled. Meanwhile, traditional image-to-image translation methods cannot work well in our application due to the coupling of expressions with other attributes such as poses, i.e., translating the expression of the character in each frame may simultaneously change the head pose due to the bias of the training data distribution. In this paper, we propose a high-quality facial expression editing method for talking face videos, allowing the user to control the target emotion in the edited video continuously. We present a new perspective for this task as a special case of motion information editing, where we use a 3DMM to capture major facial movements and an associated texture map modeled by a StyleGAN to capture appearance details. Both representations (3DMM and texture map) contain emotional information and can be continuously modified by neural networks and easily smoothed by averaging in coefficient/latent spaces, making our method simple yet effective. We also introduce a mouth shape preservation loss to control the trade-off between lip synchronization and the degree of exaggeration of the edited expression. Extensive experiments and a user study show that our method achieves state-of-the-art performance across various evaluation criteria.
ParticleSfM: Exploiting Dense Point Trajectories for Localizing Moving Cameras in the Wild
Jul 19, 2022
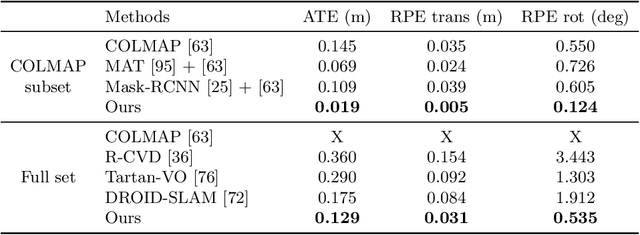
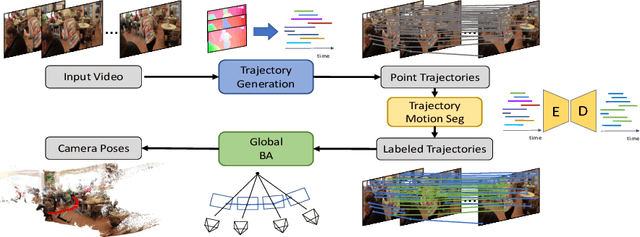
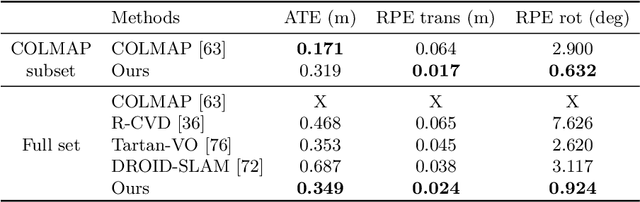
Estimating the pose of a moving camera from monocular video is a challenging problem, especially due to the presence of moving objects in dynamic environments, where the performance of existing camera pose estimation methods are susceptible to pixels that are not geometrically consistent. To tackle this challenge, we present a robust dense indirect structure-from-motion method for videos that is based on dense correspondence initialized from pairwise optical flow. Our key idea is to optimize long-range video correspondence as dense point trajectories and use it to learn robust estimation of motion segmentation. A novel neural network architecture is proposed for processing irregular point trajectory data. Camera poses are then estimated and optimized with global bundle adjustment over the portion of long-range point trajectories that are classified as static. Experiments on MPI Sintel dataset show that our system produces significantly more accurate camera trajectories compared to existing state-of-the-art methods. In addition, our method is able to retain reasonable accuracy of camera poses on fully static scenes, which consistently outperforms strong state-of-the-art dense correspondence based methods with end-to-end deep learning, demonstrating the potential of dense indirect methods based on optical flow and point trajectories. As the point trajectory representation is general, we further present results and comparisons on in-the-wild monocular videos with complex motion of dynamic objects. Code is available at https://github.com/bytedance/particle-sfm.
Dynamic Neural Textures: Generating Talking-Face Videos with Continuously Controllable Expressions
Apr 13, 2022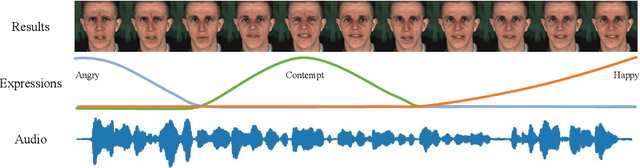
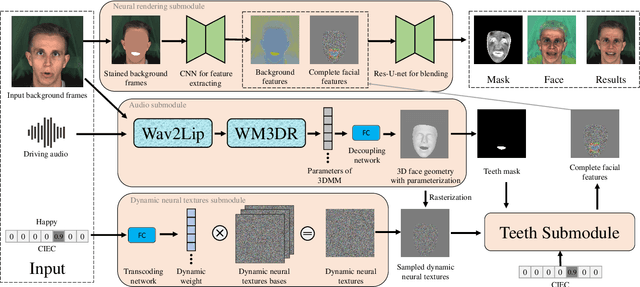
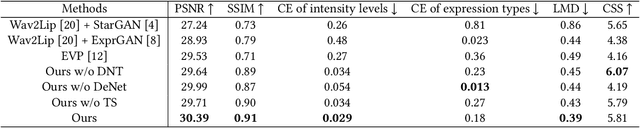
Recently, talking-face video generation has received considerable attention. So far most methods generate results with neutral expressions or expressions that are implicitly determined by neural networks in an uncontrollable way. In this paper, we propose a method to generate talking-face videos with continuously controllable expressions in real-time. Our method is based on an important observation: In contrast to facial geometry of moderate resolution, most expression information lies in textures. Then we make use of neural textures to generate high-quality talking face videos and design a novel neural network that can generate neural textures for image frames (which we called dynamic neural textures) based on the input expression and continuous intensity expression coding (CIEC). Our method uses 3DMM as a 3D model to sample the dynamic neural texture. The 3DMM does not cover the teeth area, so we propose a teeth submodule to complete the details in teeth. Results and an ablation study show the effectiveness of our method in generating high-quality talking-face videos with continuously controllable expressions. We also set up four baseline methods by combining existing representative methods and compare them with our method. Experimental results including a user study show that our method has the best performance.
PD-Flow: A Point Cloud Denoising Framework with Normalizing Flows
Mar 11, 2022
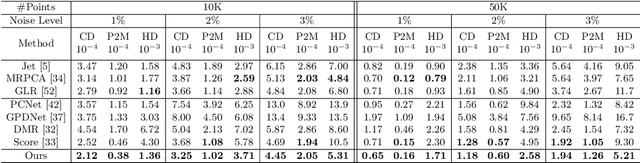
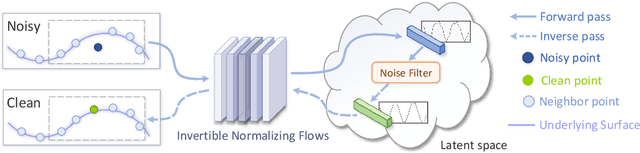
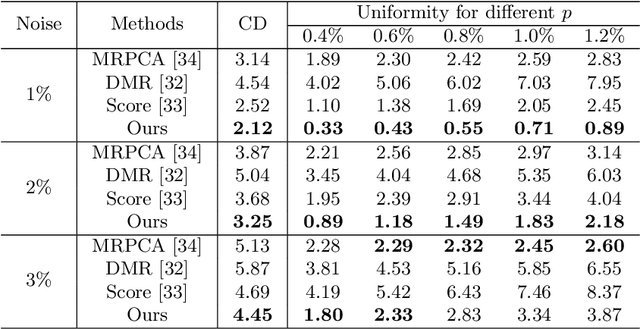
Point cloud denoising aims to restore clean point clouds from raw observations corrupted by noise and outliers while preserving the fine-grained details. We present a novel deep learning-based denoising model, that incorporates normalizing flows and noise disentanglement techniques to achieve high denoising accuracy. Unlike existing works that extract features of point clouds for point-wise correction, we formulate the denoising process from the perspective of distribution learning and feature disentanglement. By considering noisy point clouds as a joint distribution of clean points and noise, the denoised results can be derived from disentangling the noise counterpart from latent point representation, and the mapping between Euclidean and latent spaces is modeled by normalizing flows. We evaluate our method on synthesized 3D models and real-world datasets with various noise settings. Qualitative and quantitative results show that our method outperforms previous state-of-the-art deep learning-based approaches. %in terms of detail preservation and distribution uniformity.