 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNip Rumors in the Bud: Retrieval-Guided Topic-Level Adaptation for Test-Time Fake News Video Detection
Jan 17, 2026Fake News Video Detection (FNVD) is critical for social stability. Existing methods typically assume consistent news topic distribution between training and test phases, failing to detect fake news videos tied to emerging events and unseen topics. To bridge this gap, we introduce RADAR, the first framework that enables test-time adaptation to unseen news videos. RADAR pioneers a new retrieval-guided adaptation paradigm that leverages stable (source-close) videos from the target domain to guide robust adaptation of semantically related but unstable instances. Specifically, we propose an Entropy Selection-Based Retrieval mechanism that provides videos with stable (low-entropy), relevant references for adaptation. We also introduce a Stable Anchor-Guided Alignment module that explicitly aligns unstable instances' representations to the source domain via distribution-level matching with their stable references, mitigating severe domain discrepancies. Finally, our novel Target-Domain Aware Self-Training paradigm can generate informative pseudo-labels augmented by stable references, capturing varying and imbalanced category distributions in the target domain and enabling RADAR to adapt to the fast-changing label distributions. Extensive experiments demonstrate that RADAR achieves superior performance for test-time FNVD, enabling strong on-the-fly adaptation to unseen fake news video topics.
TAMEing Long Contexts in Personalization: Towards Training-Free and State-Aware MLLM Personalized Assistant
Dec 25, 2025Multimodal Large Language Model (MLLM) Personalization is a critical research problem that facilitates personalized dialogues with MLLMs targeting specific entities (known as personalized concepts). However, existing methods and benchmarks focus on the simple, context-agnostic visual identification and textual replacement of the personalized concept (e.g., "A yellow puppy" -> "Your puppy Mochi"), overlooking the ability to support long-context conversations. An ideal personalized MLLM assistant is capable of engaging in long-context dialogues with humans and continually improving its experience quality by learning from past dialogue histories. To bridge this gap, we propose LCMP, the first Long-Context MLLM Personalization evaluation benchmark. LCMP assesses the capability of MLLMs in perceiving variations of personalized concepts and generating contextually appropriate personalized responses that reflect these variations. As a strong baseline for LCMP, we introduce a novel training-free and state-aware framework TAME. TAME endows MLLMs with double memories to manage the temporal and persistent variations of each personalized concept in a differentiated manner. In addition, TAME incorporates a new training-free Retrieve-then-Align Augmented Generation (RA2G) paradigm. RA2G introduces an alignment step to extract the contextually fitted information from the multi-memory retrieved knowledge to the current questions, enabling better interactions for complex real-world user queries. Experiments on LCMP demonstrate that TAME achieves the best performance, showcasing remarkable and evolving interaction experiences in long-context scenarios.
Towards Explainable Quantum AI: Informing the Encoder Selection of Quantum Neural Networks via Visualization
Dec 16, 2025



Quantum Neural Networks (QNNs) represent a promising fusion of quantum computing and neural network architectures, offering speed-ups and efficient processing of high-dimensional, entangled data. A crucial component of QNNs is the encoder, which maps classical input data into quantum states. However, choosing suitable encoders remains a significant challenge, largely due to the lack of systematic guidance and the trial-and-error nature of current approaches. This process is further impeded by two key challenges: (1) the difficulty in evaluating encoded quantum states prior to training, and (2) the lack of intuitive methods for analyzing an encoder's ability to effectively distinguish data features. To address these issues, we introduce a novel visualization tool, XQAI-Eyes, which enables QNN developers to compare classical data features with their corresponding encoded quantum states and to examine the mixed quantum states across different classes. By bridging classical and quantum perspectives, XQAI-Eyes facilitates a deeper understanding of how encoders influence QNN performance. Evaluations across diverse datasets and encoder designs demonstrate XQAI-Eyes's potential to support the exploration of the relationship between encoder design and QNN effectiveness, offering a holistic and transparent approach to optimizing quantum encoders. Moreover, domain experts used XQAI-Eyes to derive two key practices for quantum encoder selection, grounded in the principles of pattern preservation and feature mapping.
How Far are Modern Trackers from UAV-Anti-UAV? A Million-Scale Benchmark and New Baseline
Dec 08, 2025Unmanned Aerial Vehicles (UAVs) offer wide-ranging applications but also pose significant safety and privacy violation risks in areas like airport and infrastructure inspection, spurring the rapid development of Anti-UAV technologies in recent years. However, current Anti-UAV research primarily focuses on RGB, infrared (IR), or RGB-IR videos captured by fixed ground cameras, with little attention to tracking target UAVs from another moving UAV platform. To fill this gap, we propose a new multi-modal visual tracking task termed UAV-Anti-UAV, which involves a pursuer UAV tracking a target adversarial UAV in the video stream. Compared to existing Anti-UAV tasks, UAV-Anti-UAV is more challenging due to severe dual-dynamic disturbances caused by the rapid motion of both the capturing platform and the target. To advance research in this domain, we construct a million-scale dataset consisting of 1,810 videos, each manually annotated with bounding boxes, a language prompt, and 15 tracking attributes. Furthermore, we propose MambaSTS, a Mamba-based baseline method for UAV-Anti-UAV tracking, which enables integrated spatial-temporal-semantic learning. Specifically, we employ Mamba and Transformer models to learn global semantic and spatial features, respectively, and leverage the state space model's strength in long-sequence modeling to establish video-level long-term context via a temporal token propagation mechanism. We conduct experiments on the UAV-Anti-UAV dataset to validate the effectiveness of our method. A thorough experimental evaluation of 50 modern deep tracking algorithms demonstrates that there is still significant room for improvement in the UAV-Anti-UAV domain. The dataset and codes will be available at {\color{magenta}https://github.com/983632847/Awesome-Multimodal-Object-Tracking}.
AdaCuRL: Adaptive Curriculum Reinforcement Learning with Invalid Sample Mitigation and Historical Revisiting
Nov 12, 2025



Reinforcement learning (RL) has demonstrated considerable potential for enhancing reasoning in large language models (LLMs). However, existing methods suffer from Gradient Starvation and Policy Degradation when training directly on samples with mixed difficulty. To mitigate this, prior approaches leverage Chain-of-Thought (CoT) data, but the construction of high-quality CoT annotations remains labor-intensive. Alternatively, curriculum learning strategies have been explored but frequently encounter challenges, such as difficulty mismatch, reliance on manual curriculum design, and catastrophic forgetting. To address these issues, we propose AdaCuRL, a Adaptive Curriculum Reinforcement Learning framework that integrates coarse-to-fine difficulty estimation with adaptive curriculum scheduling. This approach dynamically aligns data difficulty with model capability and incorporates a data revisitation mechanism to mitigate catastrophic forgetting. Furthermore, AdaCuRL employs adaptive reference and sparse KL strategies to prevent Policy Degradation. Extensive experiments across diverse reasoning benchmarks demonstrate that AdaCuRL consistently achieves significant performance improvements on both LLMs and MLLMs.
Where and What Matters: Sensitivity-Aware Task Vectors for Many-Shot Multimodal In-Context Learning
Nov 11, 2025Large Multimodal Models (LMMs) have shown promising in-context learning (ICL) capabilities, but scaling to many-shot settings remains difficult due to limited context length and high inference cost. To address these challenges, task-vector-based methods have been explored by inserting compact representations of many-shot in-context demonstrations into model activations. However, existing task-vector-based methods either overlook the importance of where to insert task vectors or struggle to determine suitable values for each location. To this end, we propose a novel Sensitivity-aware Task Vector insertion framework (STV) to figure out where and what to insert. Our key insight is that activation deltas across query-context pairs exhibit consistent structural patterns, providing a reliable cue for insertion. Based on the identified sensitive-aware locations, we construct a pre-clustered activation bank for each location by clustering the activation values, and then apply reinforcement learning to choose the most suitable one to insert. We evaluate STV across a range of multimodal models (e.g., Qwen-VL, Idefics-2) and tasks (e.g., VizWiz, OK-VQA), demonstrating its effectiveness and showing consistent improvements over previous task-vector-based methods with strong generalization.
Multimodal LLMs for Visualization Reconstruction and Understanding
Jun 26, 2025Visualizations are crucial for data communication, yet understanding them requires comprehension of both visual elements and their underlying data relationships. Current multimodal large models, while effective in natural image understanding, struggle with visualization due to their inability to decode the data-to-visual mapping rules and extract structured information. To address these challenges, we present a novel dataset and train multimodal visualization LLMs specifically designed for understanding. Our approach combines chart images with their corresponding vectorized representations, encoding schemes, and data features. The proposed vector format enables compact and accurate reconstruction of visualization content. Experimental results demonstrate significant improvements in both data extraction accuracy and chart reconstruction quality.
Teaching in adverse scenes: a statistically feedback-driven threshold and mask adjustment teacher-student framework for object detection in UAV images under adverse scenes
Jun 12, 2025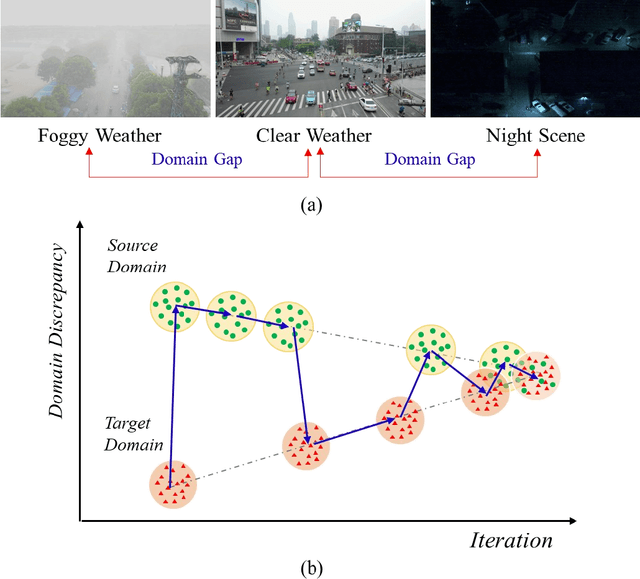
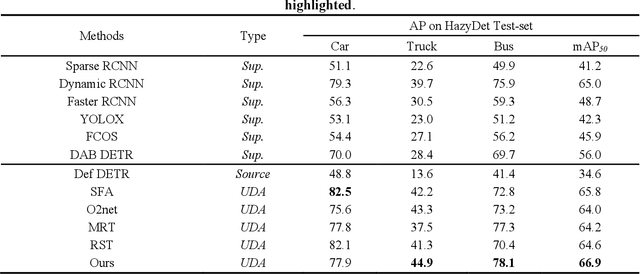
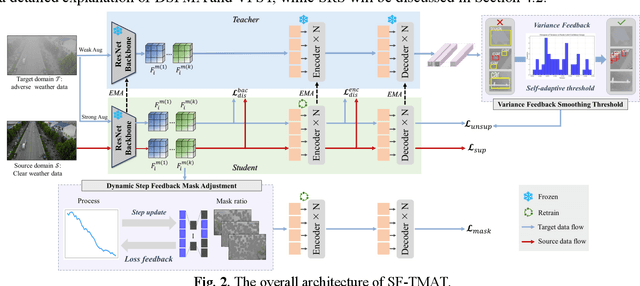
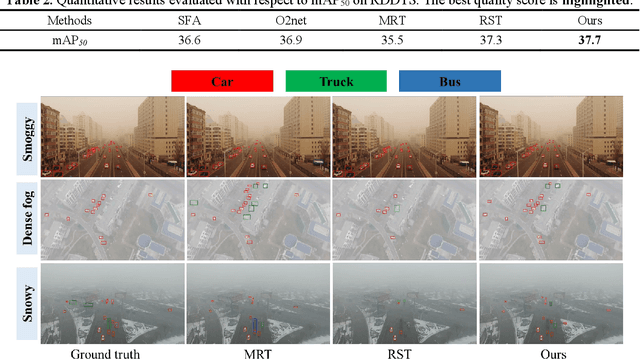
Unsupervised Domain Adaptation (UDA) has shown promise in effectively alleviating the performance degradation caused by domain gaps between source and target domains, and it can potentially be generalized to UAV object detection in adverse scenes. However, existing UDA studies are based on natural images or clear UAV imagery, and research focused on UAV imagery in adverse conditions is still in its infancy. Moreover, due to the unique perspective of UAVs and the interference from adverse conditions, these methods often fail to accurately align features and are influenced by limited or noisy pseudo-labels. To address this, we propose the first benchmark for UAV object detection in adverse scenes, the Statistical Feedback-Driven Threshold and Mask Adjustment Teacher-Student Framework (SF-TMAT). Specifically, SF-TMAT introduces a design called Dynamic Step Feedback Mask Adjustment Autoencoder (DSFMA), which dynamically adjusts the mask ratio and reconstructs feature maps by integrating training progress and loss feedback. This approach dynamically adjusts the learning focus at different training stages to meet the model's needs for learning features at varying levels of granularity. Additionally, we propose a unique Variance Feedback Smoothing Threshold (VFST) strategy, which statistically computes the mean confidence of each class and dynamically adjusts the selection threshold by incorporating a variance penalty term. This strategy improves the quality of pseudo-labels and uncovers potentially valid labels, thus mitigating domain bias. Extensive experiments demonstrate the superiority and generalization capability of the proposed SF-TMAT in UAV object detection under adverse scene conditions. The Code is released at https://github.com/ChenHuyoo .
Three Kinds of Negation in Knowledge and Their Mathematical Foundations
May 30, 2025



In the field of artificial intelligence, understanding, distinguishing, expressing, and computing the negation in knowledge is a fundamental issue in knowledge processing and research. In this paper, we examine and analyze the understanding and characteristics of negation in various fields such as philosophy, logic, and linguistics etc. Based on the distinction between the concepts of contradiction and opposition, we propose that there are three different types of negation in knowledge from a conceptual perspective: contradictory negation, opposite negation, and intermediary negation. To establish a mathematical foundation that fully reflects the intrinsic connections, properties, and laws of these different forms of negation, we introduce SCOI: sets with contradictory negation, opposite negation and intermediary negation, and LCOI: logic with contradictory negation, opposite negation and intermediary negation, and we proved the main operational properties of SCOI as well as the formal inference relations in LCOI.
HS-STAR: Hierarchical Sampling for Self-Taught Reasoners via Difficulty Estimation and Budget Reallocation
May 26, 2025Self-taught reasoners (STaRs) enhance the mathematical reasoning abilities of large language models (LLMs) by leveraging self-generated responses for self-training. Recent studies have incorporated reward models to guide response selection or decoding, aiming to obtain higher-quality data. However, they typically allocate a uniform sampling budget across all problems, overlooking the varying utility of problems at different difficulty levels. In this work, we conduct an empirical study and find that problems near the boundary of the LLM's reasoning capability offer significantly greater learning utility than both easy and overly difficult ones. To identify and exploit such problems, we propose HS-STaR, a Hierarchical Sampling framework for Self-Taught Reasoners. Given a fixed sampling budget, HS-STaR first performs lightweight pre-sampling with a reward-guided difficulty estimation strategy to efficiently identify boundary-level problems. Subsequently, it dynamically reallocates the remaining budget toward these high-utility problems during a re-sampling phase, maximizing the generation of valuable training data. Extensive experiments across multiple reasoning benchmarks and backbone LLMs demonstrate that HS-STaR significantly outperforms other baselines without requiring additional sampling budget.