 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadminSense: Enabling Fine-Grained Badminton Stroke Evaluation on a Single Smartwatch
Mar 23, 2026Evaluating badminton performance often requires expert coaching, which is rarely accessible for amateur players. We present adminSense, a smartwatch-based system for fine-grained badminton performance analysis using wearable sensing. Through interviews with experienced badminton players, we identified four system design requirements with three implementation insights that guide the development of BadminSense. We then collected a badminton strokes dataset on 12 experienced badminton amateurs and annotated it with fine-grained labels, including stroke type, expert-assessed stroke rating, and shuttle impact location. Built on this dataset, BadminSense segments and classifies strokes, predicts stroke quality, and estimates shuttle impact location using vibration signal from an off-the-shelf smartwatch. Our evaluations show that
Cycle-Consistent Tuning for Layered Image Decomposition
Feb 24, 2026Disentangling visual layers in real-world images is a persistent challenge in vision and graphics, as such layers often involve non-linear and globally coupled interactions, including shading, reflection, and perspective distortion. In this work, we present an in-context image decomposition framework that leverages large diffusion foundation models for layered separation. We focus on the challenging case of logo-object decomposition, where the goal is to disentangle a logo from the surface on which it appears while faithfully preserving both layers. Our method fine-tunes a pretrained diffusion model via lightweight LoRA adaptation and introduces a cycle-consistent tuning strategy that jointly trains decomposition and composition models, enforcing reconstruction consistency between decomposed and recomposed images. This bidirectional supervision substantially enhances robustness in cases where the layers exhibit complex interactions. Furthermore, we introduce a progressive self-improving process, which iteratively augments the training set with high-quality model-generated examples to refine performance. Extensive experiments demonstrate that our approach achieves accurate and coherent decompositions and also generalizes effectively across other decomposition types, suggesting its potential as a unified framework for layered image decomposition.
Layered Image Vectorization via Semantic Simplification
Jun 08, 2024



This work presents a novel progressive image vectorization technique aimed at generating layered vectors that represent the original image from coarse to fine detail levels. Our approach introduces semantic simplification, which combines Score Distillation Sampling and semantic segmentation to iteratively simplify the input image. Subsequently, our method optimizes the vector layers for each of the progressively simplified images. Our method provides robust optimization, which avoids local minima and enables adjustable detail levels in the final output. The layered, compact vector representation enhances usability for further editing and modification. Comparative analysis with conventional vectorization methods demonstrates our technique's superiority in producing vectors with high visual fidelity, and more importantly, maintaining vector compactness and manageability. The project homepage is https://szuviz.github.io/layered_vectorization/.
EL-VIT: Probing Vision Transformer with Interactive Visualization
Jan 23, 2024



Nowadays, Vision Transformer (ViT) is widely utilized in various computer vision tasks, owing to its unique self-attention mechanism. However, the model architecture of ViT is complex and often challenging to comprehend, leading to a steep learning curve. ViT developers and users frequently encounter difficulties in interpreting its inner workings. Therefore, a visualization system is needed to assist ViT users in understanding its functionality. This paper introduces EL-VIT, an interactive visual analytics system designed to probe the Vision Transformer and facilitate a better understanding of its operations. The system consists of four layers of visualization views. The first three layers include model overview, knowledge background graph, and model detail view. These three layers elucidate the operation process of ViT from three perspectives: the overall model architecture, detailed explanation, and mathematical operations, enabling users to understand the underlying principles and the transition process between layers. The fourth interpretation view helps ViT users and experts gain a deeper understanding by calculating the cosine similarity between patches. Our two usage scenarios demonstrate the effectiveness and usability of EL-VIT in helping ViT users understand the working mechanism of ViT.
VoiceCoach: Interactive Evidence-based Training for Voice Modulation Skills in Public Speaking
Jan 22, 2020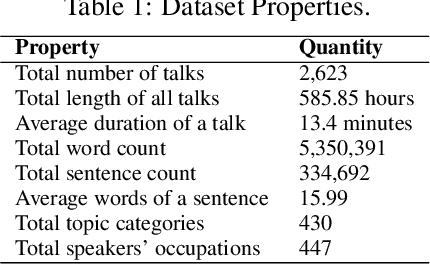
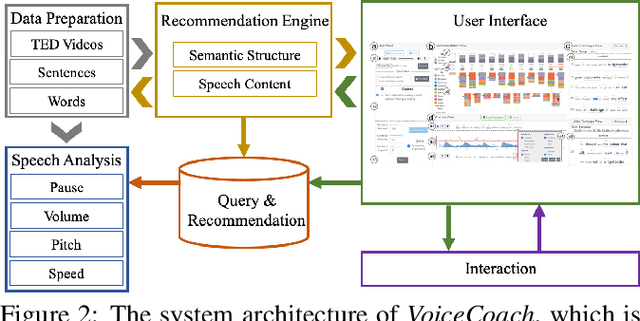

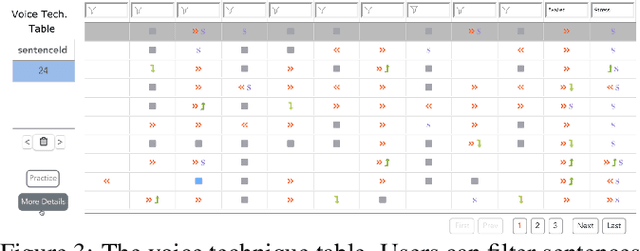
The modulation of voice properties, such as pitch, volume, and speed, is crucial for delivering a successful public speech. However, it is challenging to master different voice modulation skills. Though many guidelines are available, they are often not practical enough to be applied in different public speaking situations, especially for novice speakers. We present VoiceCoach, an interactive evidence-based approach to facilitate the effective training of voice modulation skills. Specifically, we have analyzed the voice modulation skills from 2623 high-quality speeches (i.e., TED Talks) and use them as the benchmark dataset. Given a voice input, VoiceCoach automatically recommends good voice modulation examples from the dataset based on the similarity of both sentence structures and voice modulation skills. Immediate and quantitative visual feedback is provided to guide further improvement. The expert interviews and the user study provide support for the effectiveness and usability of VoiceCoach.