 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreservational Learning Improves Self-supervised Medical Image Models by Reconstructing Diverse Contexts
Sep 09, 2021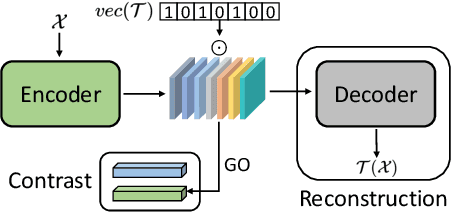
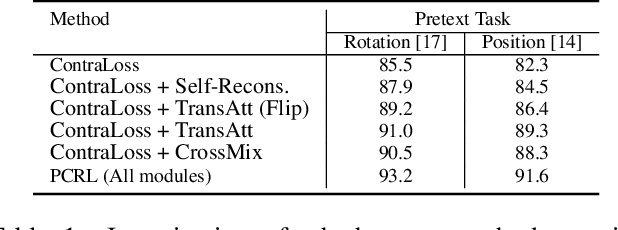
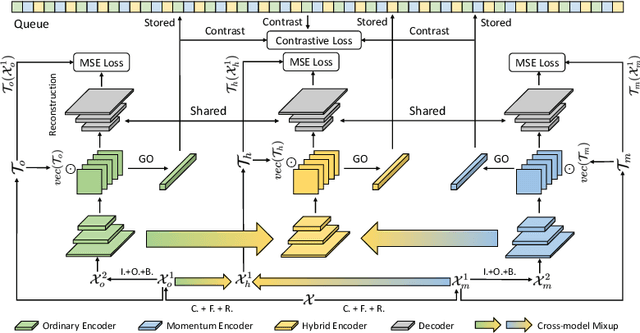
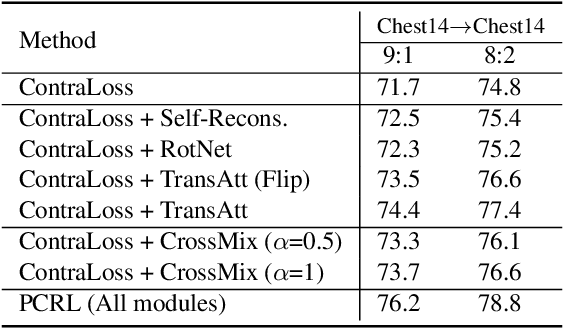
Preserving maximal information is one of principles of designing self-supervised learning methodologies. To reach this goal, contrastive learning adopts an implicit way which is contrasting image pairs. However, we believe it is not fully optimal to simply use the contrastive estimation for preservation. Moreover, it is necessary and complemental to introduce an explicit solution to preserve more information. From this perspective, we introduce Preservational Learning to reconstruct diverse image contexts in order to preserve more information in learned representations. Together with the contrastive loss, we present Preservational Contrastive Representation Learning (PCRL) for learning self-supervised medical representations. PCRL provides very competitive results under the pretraining-finetuning protocol, outperforming both self-supervised and supervised counterparts in 5 classification/segmentation tasks substantially.
Identification of Pediatric Respiratory Diseases Using Fine-grained Diagnosis System
Aug 24, 2021
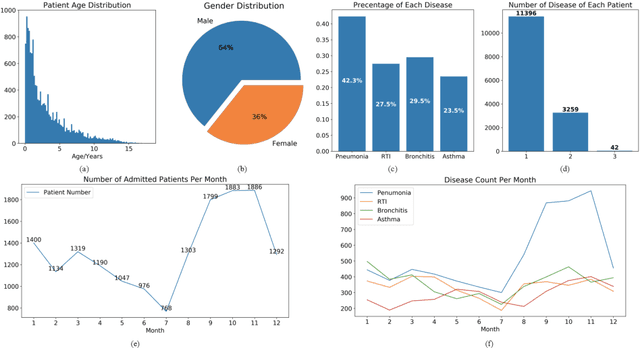
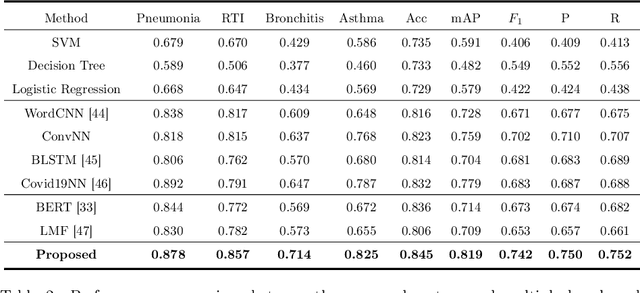
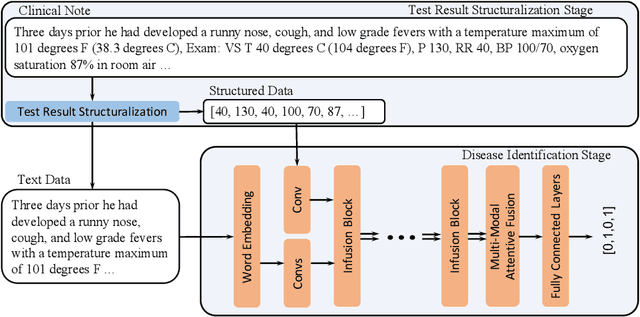
Respiratory diseases, including asthma, bronchitis, pneumonia, and upper respiratory tract infection (RTI), are among the most common diseases in clinics. The similarities among the symptoms of these diseases precludes prompt diagnosis upon the patients' arrival. In pediatrics, the patients' limited ability in expressing their situation makes precise diagnosis even harder. This becomes worse in primary hospitals, where the lack of medical imaging devices and the doctors' limited experience further increase the difficulty of distinguishing among similar diseases. In this paper, a pediatric fine-grained diagnosis-assistant system is proposed to provide prompt and precise diagnosis using solely clinical notes upon admission, which would assist clinicians without changing the diagnostic process. The proposed system consists of two stages: a test result structuralization stage and a disease identification stage. The first stage structuralizes test results by extracting relevant numerical values from clinical notes, and the disease identification stage provides a diagnosis based on text-form clinical notes and the structured data obtained from the first stage. A novel deep learning algorithm was developed for the disease identification stage, where techniques including adaptive feature infusion and multi-modal attentive fusion were introduced to fuse structured and text data together. Clinical notes from over 12000 patients with respiratory diseases were used to train a deep learning model, and clinical notes from a non-overlapping set of about 1800 patients were used to evaluate the performance of the trained model. The average precisions (AP) for pneumonia, RTI, bronchitis and asthma are 0.878, 0.857, 0.714, and 0.825, respectively, achieving a mean AP (mAP) of 0.819.
ME-PCN: Point Completion Conditioned on Mask Emptiness
Aug 18, 2021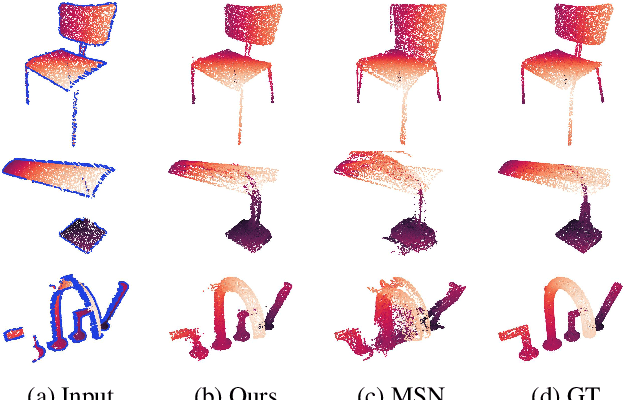
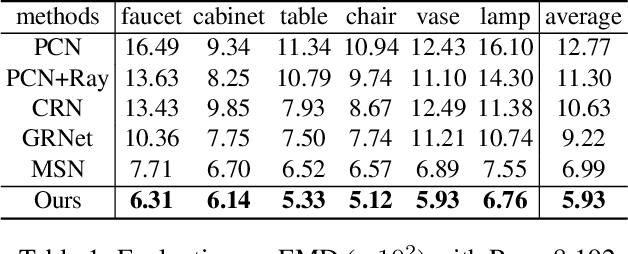
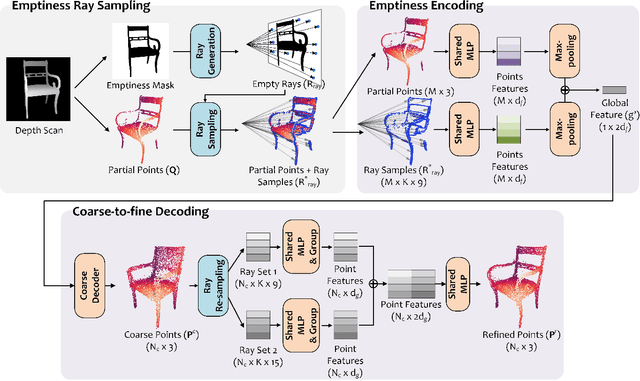
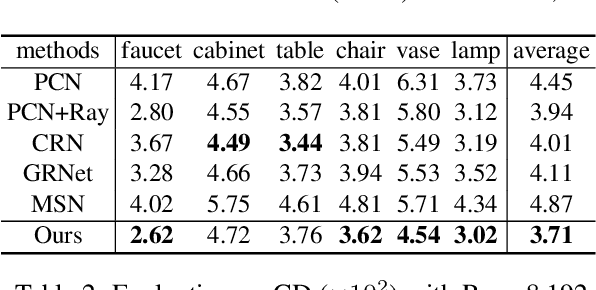
Point completion refers to completing the missing geometries of an object from incomplete observations. Main-stream methods predict the missing shapes by decoding a global feature learned from the input point cloud, which often leads to deficient results in preserving topology consistency and surface details. In this work, we present ME-PCN, a point completion network that leverages `emptiness' in 3D shape space. Given a single depth scan, previous methods often encode the occupied partial shapes while ignoring the empty regions (e.g. holes) in depth maps. In contrast, we argue that these `emptiness' clues indicate shape boundaries that can be used to improve topology representation and detail granularity on surfaces. Specifically, our ME-PCN encodes both the occupied point cloud and the neighboring `empty points'. It estimates coarse-grained but complete and reasonable surface points in the first stage, followed by a refinement stage to produce fine-grained surface details. Comprehensive experiments verify that our ME-PCN presents better qualitative and quantitative performance against the state-of-the-art. Besides, we further prove that our `emptiness' design is lightweight and easy to embed in existing methods, which shows consistent effectiveness in improving the CD and EMD scores.
ConvNets vs. Transformers: Whose Visual Representations are More Transferable?
Aug 17, 2021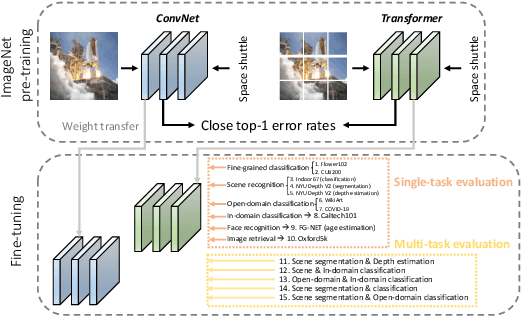
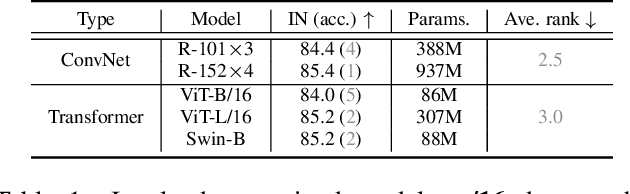
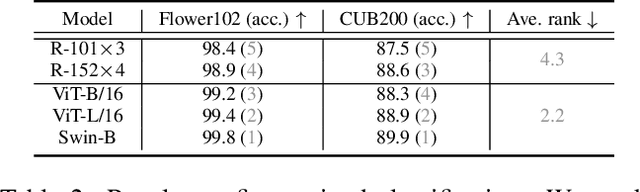

Vision transformers have attracted much attention from computer vision researchers as they are not restricted to the spatial inductive bias of ConvNets. However, although Transformer-based backbones have achieved much progress on ImageNet classification, it is still unclear whether the learned representations are as transferable as or even more transferable than ConvNets' features. To address this point, we systematically investigate the transfer learning ability of ConvNets and vision transformers in 15 single-task and multi-task performance evaluations. Given the strong correlation between the performance of pre-trained models and transfer learning, we include 2 residual ConvNets (i.e., R-101x3 and R-152x4) and 3 Transformer-based visual backbones (i.e., ViT-B, ViT-L and Swin-B), which have close error rates on ImageNet, that indicate similar transfer learning performance on downstream datasets. We observe consistent advantages of Transformer-based backbones on 13 downstream tasks (out of 15), including but not limited to fine-grained classification, scene recognition (classification, segmentation and depth estimation), open-domain classification, face recognition, etc. More specifically, we find that two ViT models heavily rely on whole network fine-tuning to achieve performance gains while Swin Transformer does not have such a requirement. Moreover, vision transformers behave more robustly in multi-task learning, i.e., bringing more improvements when managing mutually beneficial tasks and reducing performance losses when tackling irrelevant tasks. We hope our discoveries can facilitate the exploration and exploitation of vision transformers in the future.
CarveMix: A Simple Data Augmentation Method for Brain Lesion Segmentation
Aug 17, 2021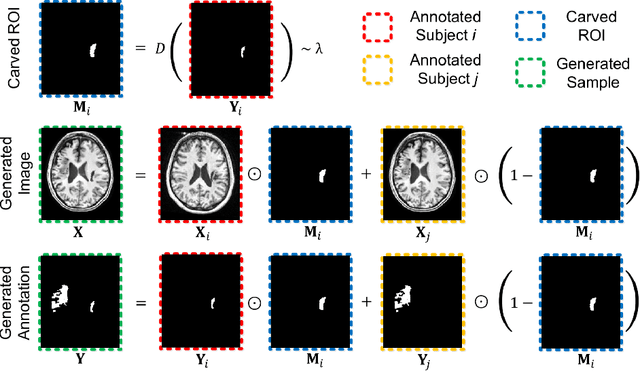

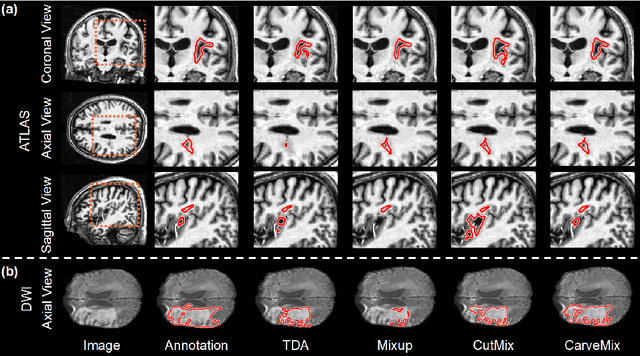
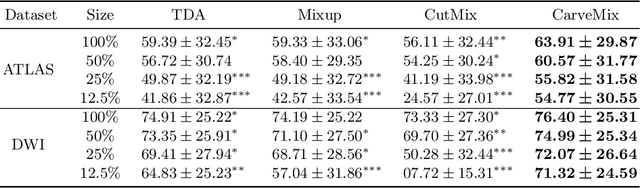
Brain lesion segmentation provides a valuable tool for clinical diagnosis, and convolutional neural networks (CNNs) have achieved unprecedented success in the task. Data augmentation is a widely used strategy that improves the training of CNNs, and the design of the augmentation method for brain lesion segmentation is still an open problem. In this work, we propose a simple data augmentation approach, dubbed as CarveMix, for CNN-based brain lesion segmentation. Like other "mix"-based methods, such as Mixup and CutMix, CarveMix stochastically combines two existing labeled images to generate new labeled samples. Yet, unlike these augmentation strategies based on image combination, CarveMix is lesion-aware, where the combination is performed with an attention on the lesions and a proper annotation is created for the generated image. Specifically, from one labeled image we carve a region of interest (ROI) according to the lesion location and geometry, and the size of the ROI is sampled from a probability distribution. The carved ROI then replaces the corresponding voxels in a second labeled image, and the annotation of the second image is replaced accordingly as well. In this way, we generate new labeled images for network training and the lesion information is preserved. To evaluate the proposed method, experiments were performed on two brain lesion datasets. The results show that our method improves the segmentation accuracy compared with other simple data augmentation approaches.
GraphFPN: Graph Feature Pyramid Network for Object Detection
Aug 02, 2021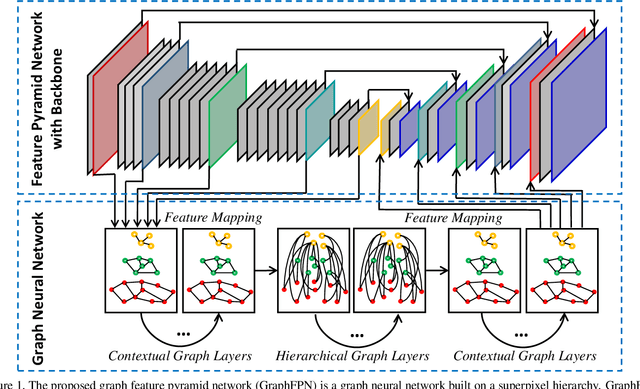
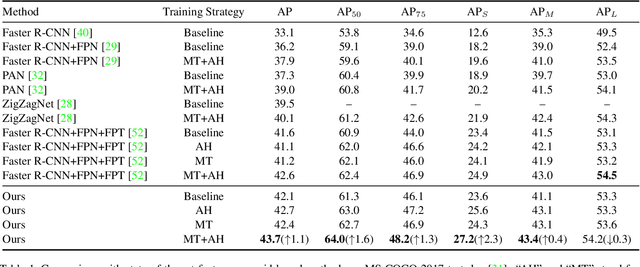
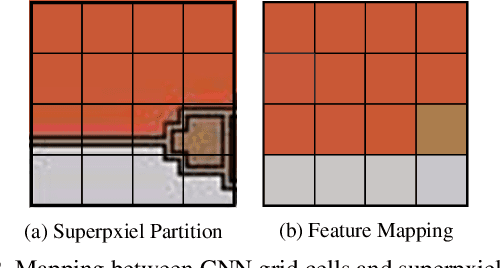

Feature pyramids have been proven powerful in image understanding tasks that require multi-scale features. State-of-the-art methods for multi-scale feature learning focus on performing feature interactions across space and scales using neural networks with a fixed topology. In this paper, we propose graph feature pyramid networks that are capable of adapting their topological structures to varying intrinsic image structures and supporting simultaneous feature interactions across all scales. We first define an image-specific superpixel hierarchy for each input image to represent its intrinsic image structures. The graph feature pyramid network inherits its structure from this superpixel hierarchy. Contextual and hierarchical layers are designed to achieve feature interactions within the same scale and across different scales. To make these layers more powerful, we introduce two types of local channel attention for graph neural networks by generalizing global channel attention for convolutional neural networks. The proposed graph feature pyramid network can enhance the multiscale features from a convolutional feature pyramid network. We evaluate our graph feature pyramid network in the object detection task by integrating it into the Faster R-CNN algorithm. The modified algorithm outperforms not only previous state-of-the-art feature pyramid-based methods with a clear margin but also other popular detection methods on both MS-COCO 2017 validation and test datasets.
Multi-scale Matching Networks for Semantic Correspondence
Jul 31, 2021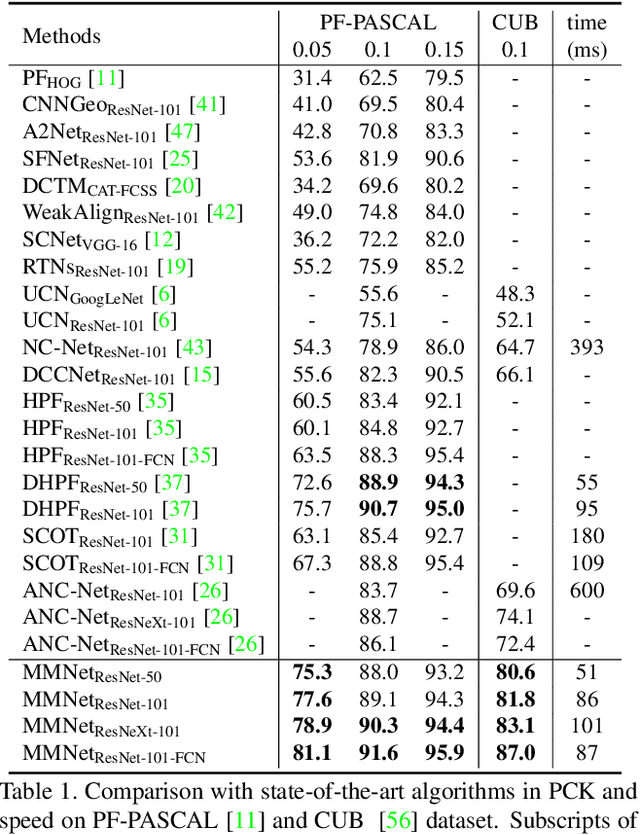

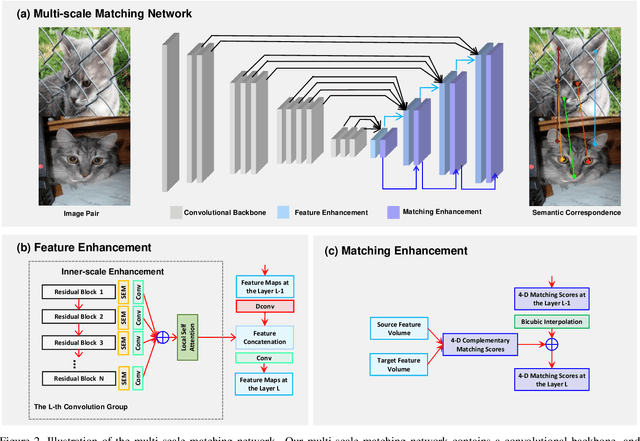
Deep features have been proven powerful in building accurate dense semantic correspondences in various previous works. However, the multi-scale and pyramidal hierarchy of convolutional neural networks has not been well studied to learn discriminative pixel-level features for semantic correspondence. In this paper, we propose a multi-scale matching network that is sensitive to tiny semantic differences between neighboring pixels. We follow the coarse-to-fine matching strategy and build a top-down feature and matching enhancement scheme that is coupled with the multi-scale hierarchy of deep convolutional neural networks. During feature enhancement, intra-scale enhancement fuses same-resolution feature maps from multiple layers together via local self-attention and cross-scale enhancement hallucinates higher-resolution feature maps along the top-down hierarchy. Besides, we learn complementary matching details at different scales thus the overall matching score is refined by features of different semantic levels gradually. Our multi-scale matching network can be trained end-to-end easily with few additional learnable parameters. Experimental results demonstrate that the proposed method achieves state-of-the-art performance on three popular benchmarks with high computational efficiency.
Domain Generalization on Medical Imaging Classification using Episodic Training with Task Augmentation
Jun 13, 2021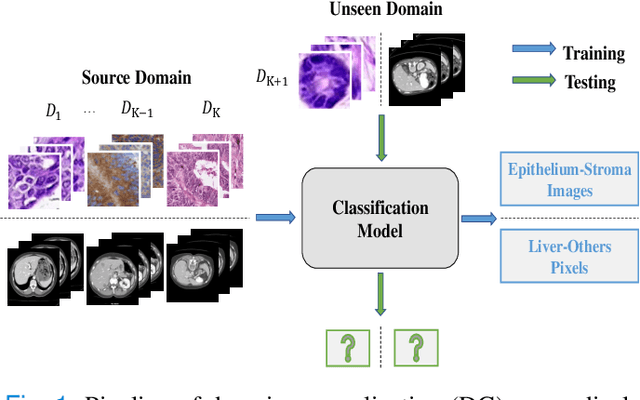
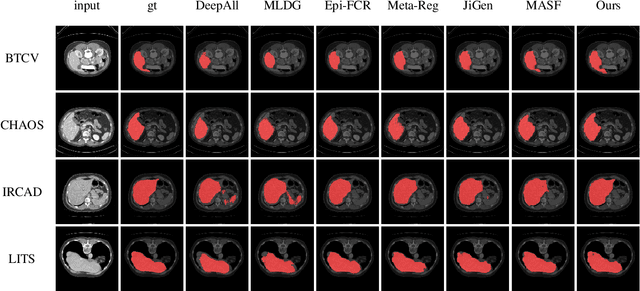
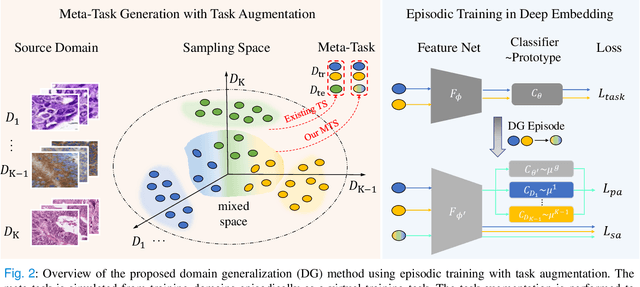
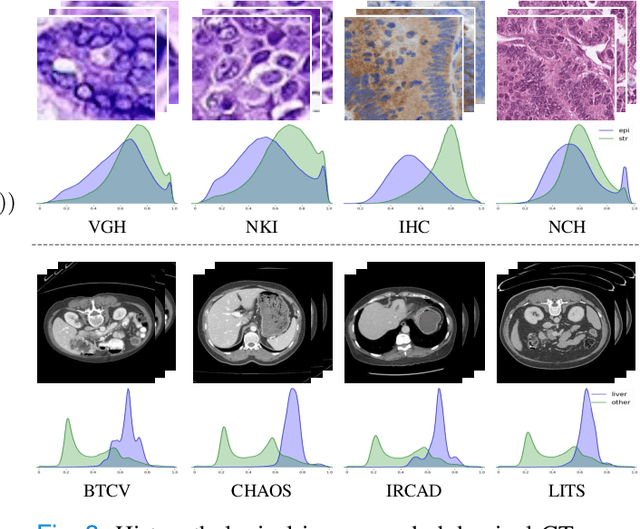
Medical imaging datasets usually exhibit domain shift due to the variations of scanner vendors, imaging protocols, etc. This raises the concern about the generalization capacity of machine learning models. Domain generalization (DG), which aims to learn a model from multiple source domains such that it can be directly generalized to unseen test domains, seems particularly promising to medical imaging community. To address DG, recent model-agnostic meta-learning (MAML) has been introduced, which transfers the knowledge from previous training tasks to facilitate the learning of novel testing tasks. However, in clinical practice, there are usually only a few annotated source domains available, which decreases the capacity of training task generation and thus increases the risk of overfitting to training tasks in the paradigm. In this paper, we propose a novel DG scheme of episodic training with task augmentation on medical imaging classification. Based on meta-learning, we develop the paradigm of episodic training to construct the knowledge transfer from episodic training-task simulation to the real testing task of DG. Motivated by the limited number of source domains in real-world medical deployment, we consider the unique task-level overfitting and we propose task augmentation to enhance the variety during training task generation to alleviate it. With the established learning framework, we further exploit a novel meta-objective to regularize the deep embedding of training domains. To validate the effectiveness of the proposed method, we perform experiments on histopathological images and abdominal CT images.
SSMD: Semi-Supervised Medical Image Detection with Adaptive Consistency and Heterogeneous Perturbation
Jun 03, 2021Semi-Supervised classification and segmentation methods have been widely investigated in medical image analysis. Both approaches can improve the performance of fully-supervised methods with additional unlabeled data. However, as a fundamental task, semi-supervised object detection has not gained enough attention in the field of medical image analysis. In this paper, we propose a novel Semi-Supervised Medical image Detector (SSMD). The motivation behind SSMD is to provide free yet effective supervision for unlabeled data, by regularizing the predictions at each position to be consistent. To achieve the above idea, we develop a novel adaptive consistency cost function to regularize different components in the predictions. Moreover, we introduce heterogeneous perturbation strategies that work in both feature space and image space, so that the proposed detector is promising to produce powerful image representations and robust predictions. Extensive experimental results show that the proposed SSMD achieves the state-of-the-art performance at a wide range of settings. We also demonstrate the strength of each proposed module with comprehensive ablation studies.
Hierarchical Deep Network with Uncertainty-aware Semi-supervised Learning for Vessel Segmentation
May 31, 2021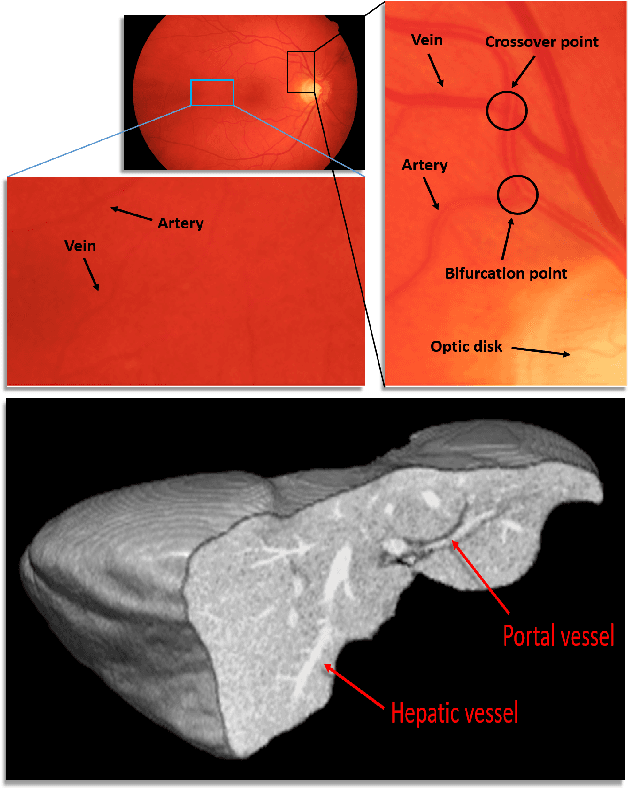
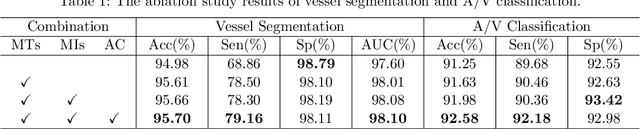
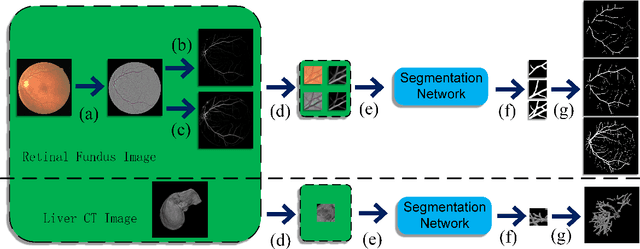
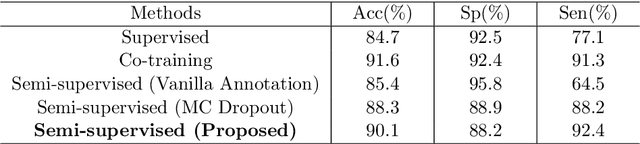
The analysis of organ vessels is essential for computer-aided diagnosis and surgical planning. But it is not a easy task since the fine-detailed connected regions of organ vessel bring a lot of ambiguity in vessel segmentation and sub-type recognition, especially for the low-contrast capillary regions. Furthermore, recent two-staged approaches would accumulate and even amplify these inaccuracies from the first-stage whole vessel segmentation into the second-stage sub-type vessel pixel-wise classification. Moreover, the scarcity of manual annotation in organ vessels poses another challenge. In this paper, to address the above issues, we propose a hierarchical deep network where an attention mechanism localizes the low-contrast capillary regions guided by the whole vessels, and enhance the spatial activation in those areas for the sub-type vessels. In addition, we propose an uncertainty-aware semi-supervised training framework to alleviate the annotation-hungry limitation of deep models. The proposed method achieves the state-of-the-art performance in the benchmarks of both retinal artery/vein segmentation in fundus images and liver portal/hepatic vessel segmentation in CT images.