 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Preference-Based Learning for High-dimensional Optimization of Exoskeleton Walking Gaits
Mar 13, 2020
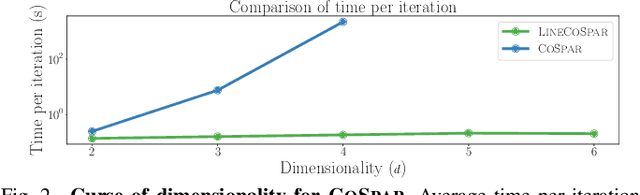
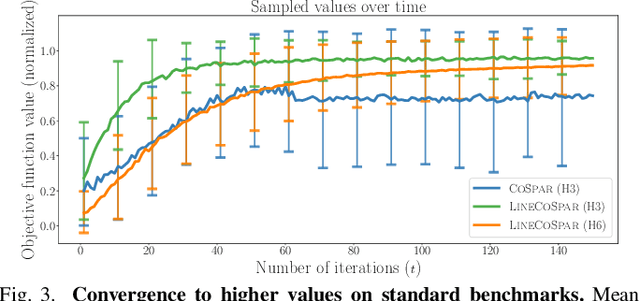
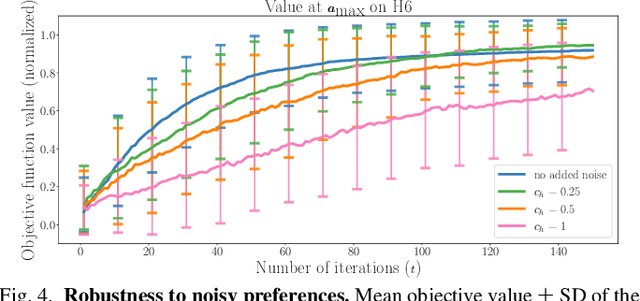
Understanding users' gait preferences of a lower-body exoskeleton requires optimizing over the high-dimensional gait parameter space. However, existing preference-based learning methods have only explored low-dimensional domains due to computational limitations. To learn user preferences in high dimensions, this work presents LineCoSpar, a human-in-the-loop preference-based framework that enables optimization over many parameters by iteratively exploring one-dimensional subspaces. Additionally, this work identifies gait attributes that characterize broader preferences across users. In simulations and human trials, we empirically verify that LineCoSpar is a sample-efficient approach for high-dimensional preference optimization. Our analysis of the experimental data reveals a correspondence between human preferences and objective measures of dynamic stability, while also highlighting inconsistencies in the utility functions underlying different users' gait preferences. This has implications for exoskeleton gait synthesis, an active field with applications to clinical use and patient rehabilitation.
Neural-Swarm: Decentralized Close-Proximity Multirotor Control Using Learned Interactions
Mar 06, 2020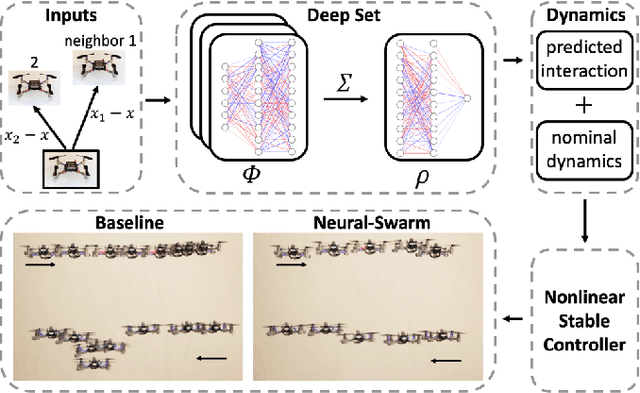
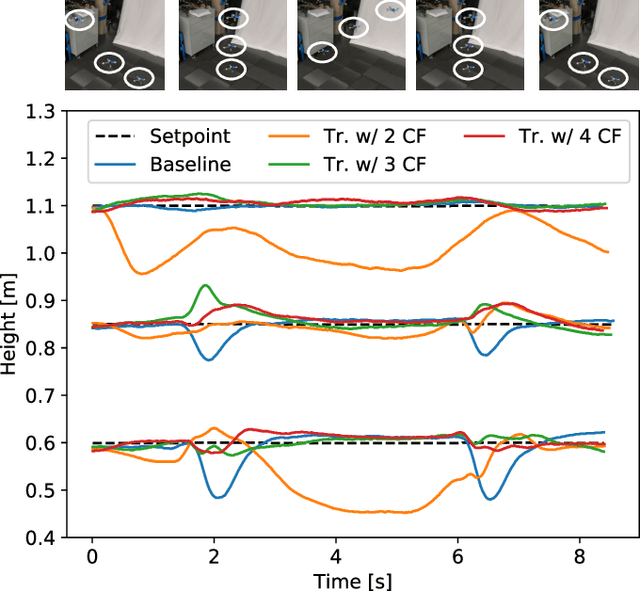
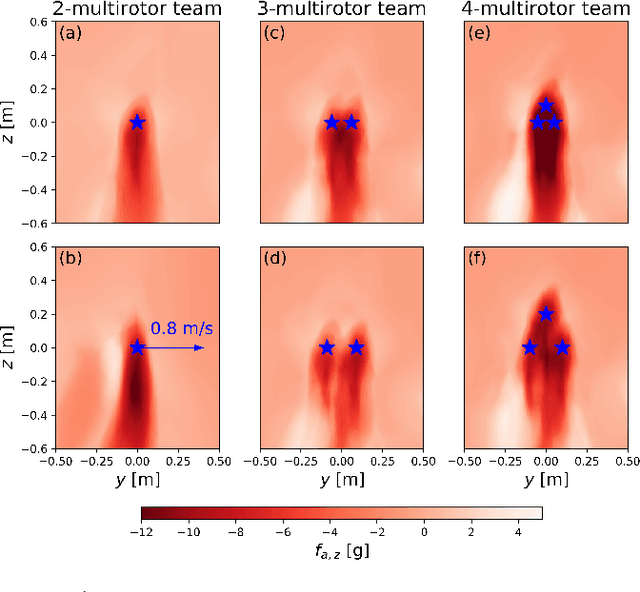
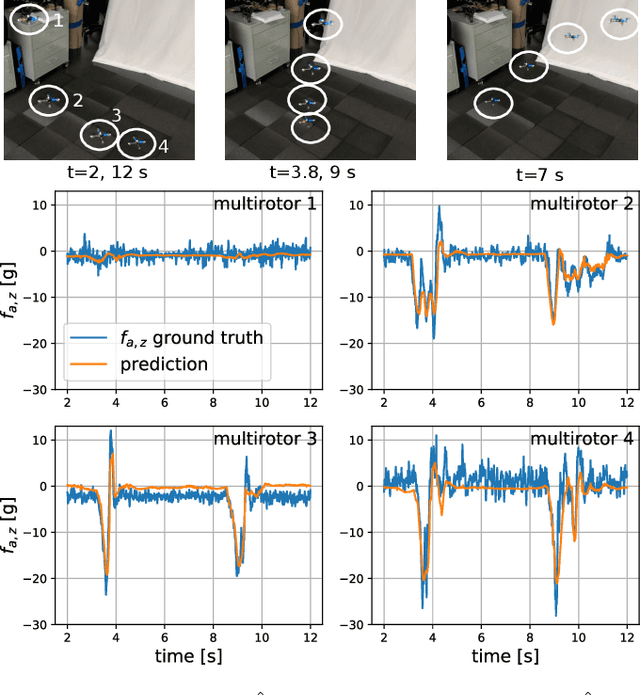
In this paper, we present Neural-Swarm, a nonlinear decentralized stable controller for close-proximity flight of multirotor swarms. Close-proximity control is challenging due to the complex aerodynamic interaction effects between multirotors, such as downwash from higher vehicles to lower ones. Conventional methods often fail to properly capture these interaction effects, resulting in controllers that must maintain large safety distances between vehicles, and thus are not capable of close-proximity flight. Our approach combines a nominal dynamics model with a regularized permutation-invariant Deep Neural Network (DNN) that accurately learns the high-order multi-vehicle interactions. We design a stable nonlinear tracking controller using the learned model. Experimental results demonstrate that the proposed controller significantly outperforms a baseline nonlinear tracking controller with up to four times smaller worst-case height tracking errors. We also empirically demonstrate the ability of our learned model to generalize to larger swarm sizes.
GLAS: Global-to-Local Safe Autonomy Synthesis for Multi-Robot Motion Planning with End-to-End Learning
Feb 26, 2020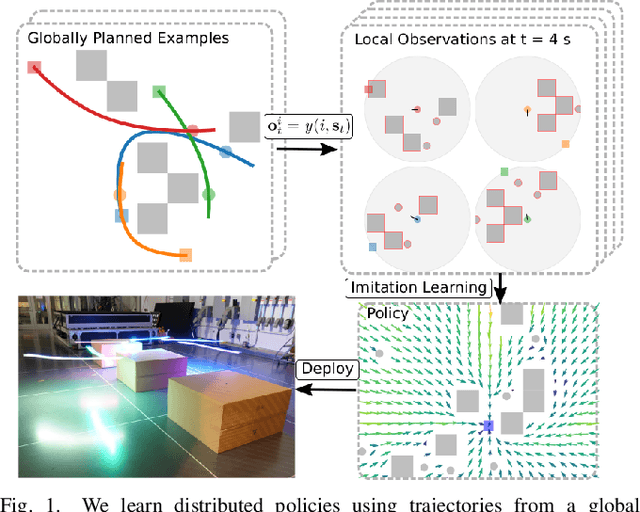
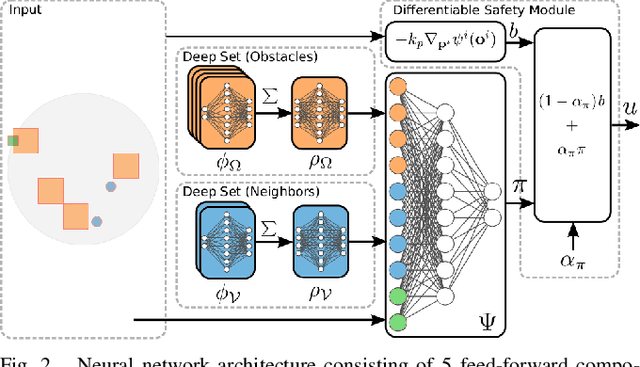
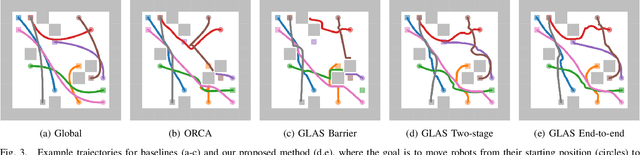
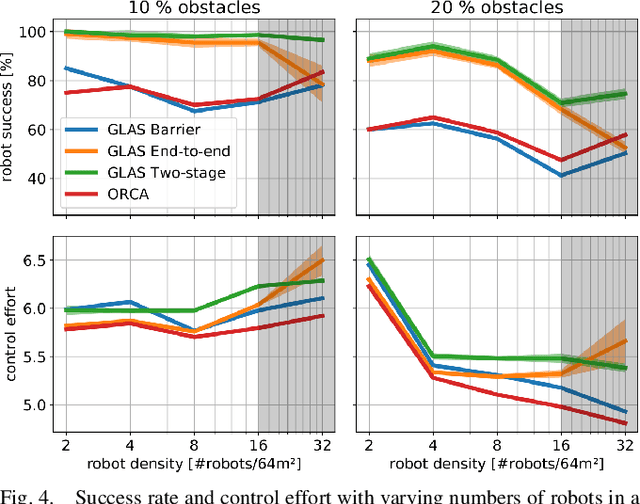
We present GLAS: Global-to-Local Autonomy Synthesis, a provably-safe, automated distributed policy generation for multi-robot motion planning. Our approach combines the advantage of centralized planning of avoiding local minima with the advantage of decentralized controllers of scalability and distributed computation. In particular, our synthesized policies only require relative state information of nearby neighbors and obstacles, and compute a provably-safe action. Our approach has three major components: i) we generate demonstration trajectories using a global planner and extract local observations from them, ii) we use deep imitation learning to learn a decentralized policy that can run efficiently online, and iii) we introduce a novel differentiable safety module to ensure collision-free operation, enabling end-to-end policy training. Our numerical experiments demonstrate that our policies have a 20% higher success rate than ORCA across a wide range of robot and obstacle densities. We demonstrate our method on an aerial swarm, executing the policy on low-end microcontrollers in real-time.
Multiresolution Tensor Learning for Efficient and Interpretable Spatial Analysis
Feb 15, 2020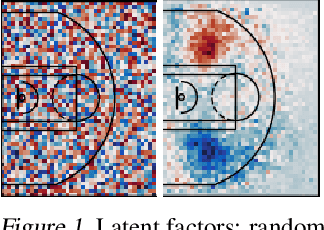

Efficient and interpretable spatial analysis is crucial in many fields such as geology, sports, and climate science. Large-scale spatial data often contains complex higher-order correlations across features and locations. While tensor latent factor models can describe higher-order correlations, they are inherently computationally expensive to train. Furthermore, for spatial analysis, these models should not only be predictive but also be spatially coherent. However, latent factor models are sensitive to initialization and can yield inexplicable results. We develop a novel Multi-resolution Tensor Learning (MRTL) algorithm for efficiently learning interpretable spatial patterns. MRTL initializes the latent factors from an approximate full-rank tensor model for improved interpretability and progressively learns from a coarse resolution to the fine resolution for an enormous computation speedup. We also prove the theoretical convergence and computational complexity of MRTL. When applied to two real-world datasets, MRTL demonstrates 4 ~ 5 times speedup compared to a fixed resolution while yielding accurate and interpretable models.
Beyond No-Regret: Competitive Control via Online Optimization with Memory
Feb 13, 2020
This paper studies online control with adversarial disturbances using tools from online optimization with memory. Most work that bridges learning and control theory focuses on designing policies that are no-regret with respect to the best static linear controller in hindsight. However, the optimal offline controller can have orders-of-magnitude lower cost than the best linear controller. We instead focus on achieving constant competitive ratio compared to the offline optimal controller, which need not be linear or static. We provide a novel reduction from online control of a class of controllable systems to online convex optimization with memory. We then design a new algorithm for online convex optimization with memory, Optimistic Regularized Online Balanced Descent, that has a constant, dimension-free competitive ratio. This result, in turn, leads to a new constant-competitive approach for online control.
On the distance between two neural networks and the stability of learning
Feb 09, 2020
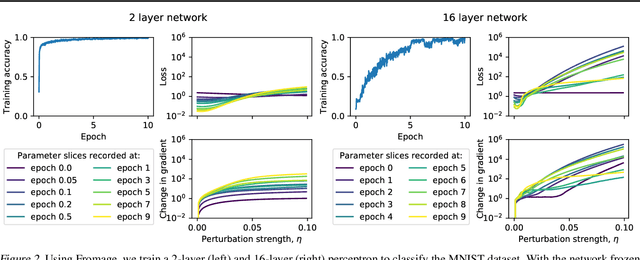
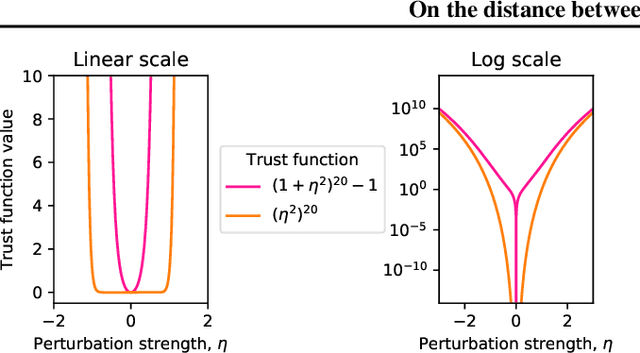
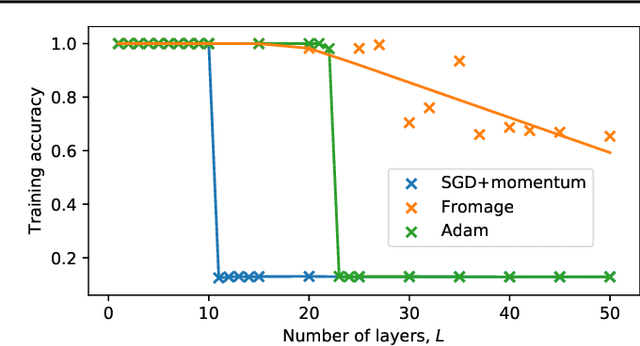
How far apart are two neural networks? This is a foundational question in their theory. We derive a simple and tractable bound that relates distance in function space to distance in parameter space for a broad class of nonlinear compositional functions. The bound distills a clear dependence on depth of the composition. The theory is of practical relevance since it establishes a trust region for first-order optimisation. In turn, this suggests an optimiser that we call Frobenius matched gradient descent---or Fromage. Fromage involves a principled form of gradient rescaling and enjoys guarantees on stability of both the spectra and Frobenius norms of the weights. We find that the new algorithm increases the depth at which a multilayer perceptron may be trained as compared to Adam and SGD and is competitive with Adam for training generative adversarial networks. We further verify that Fromage scales up to a language transformer with over $10^8$ parameters. Please find code & reproducibility instructions at: https://github.com/jxbz/fromage.
Learning for Safety-Critical Control with Control Barrier Functions
Dec 20, 2019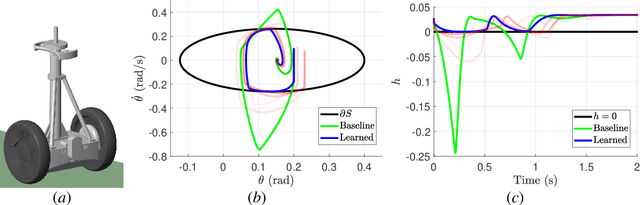
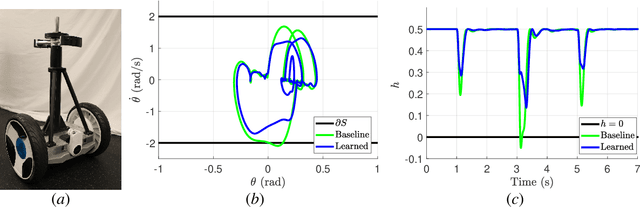
Modern nonlinear control theory seeks to endow systems with properties of stability and safety, and have been deployed successfully in multiple domains. Despite this success, model uncertainty remains a significant challenge in synthesizing safe controllers, leading to degradation in the properties provided by the controllers. This paper develops a machine learning framework utilizing Control Barrier Functions (CBFs) to reduce model uncertainty as it impact the safe behavior of a system. This approach iteratively collects data and updates a controller, ultimately achieving safe behavior. We validate this method in simulation and experimentally on a Segway platform.
Triply Robust Off-Policy Evaluation
Nov 16, 2019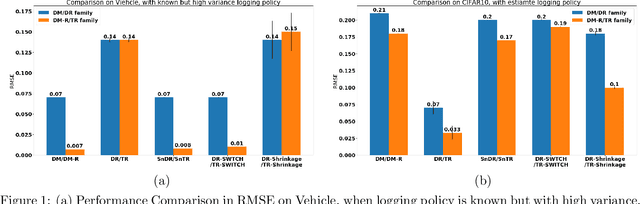
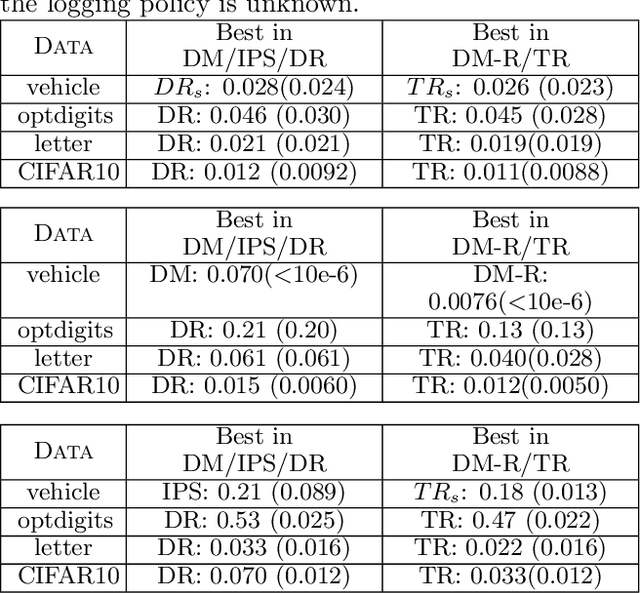
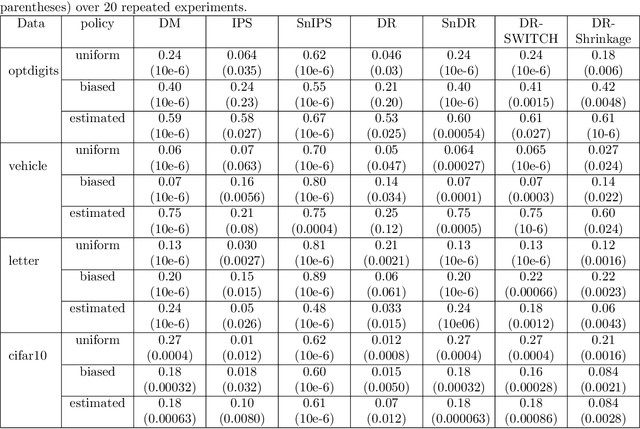
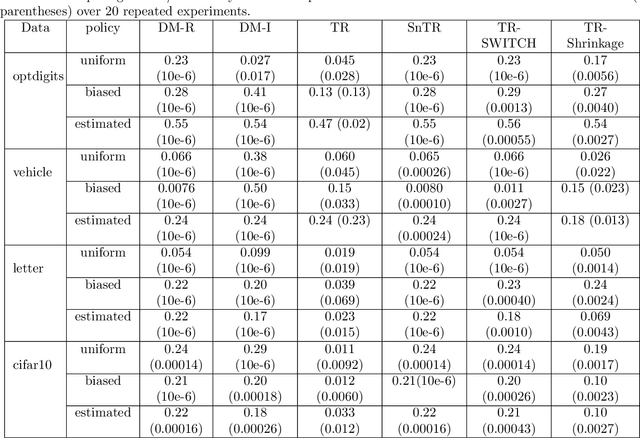
We propose a robust regression approach to off-policy evaluation (OPE) for contextual bandits. We frame OPE as a covariate-shift problem and leverage modern robust regression tools. Ours is a general approach that can be used to augment any existing OPE method that utilizes the direct method. When augmenting doubly robust methods, we call the resulting method Triply Robust. We prove upper bounds on the resulting bias and variance, as well as derive novel minimax bounds based on robust minimax analysis for covariate shift. Our robust regression method is compatible with deep learning, and is thus applicable to complex OPE settings that require powerful function approximators. Finally, we demonstrate superior empirical performance across the standard OPE benchmarks, especially in the case where the logging policy is unknown and must be estimated from data.
Empirical Study of Off-Policy Policy Evaluation for Reinforcement Learning
Nov 15, 2019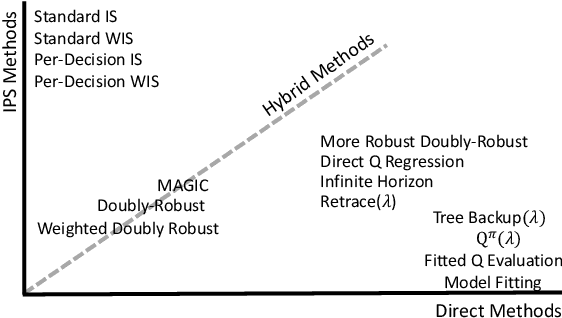


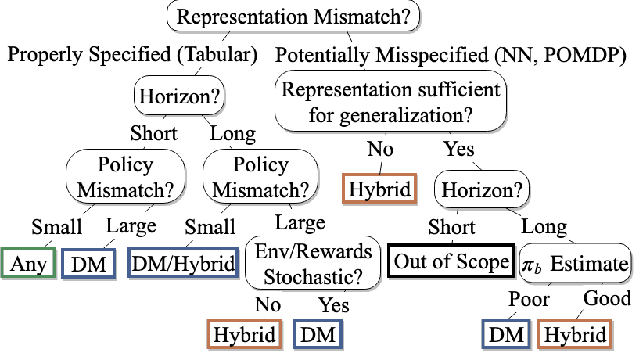
Off-policy policy evaluation (OPE) is the problem of estimating the online performance of a policy using only pre-collected historical data generated by another policy. Given the increasing interest in deploying learning-based methods for safety-critical applications, many recent OPE methods have recently been proposed. Due to disparate experimental conditions from recent literature, the relative performance of current OPE methods is not well understood. In this work, we present the first comprehensive empirical analysis of a broad suite of OPE methods. Based on thousands of experiments and detailed empirical analyses, we offer a summarized set of guidelines for effectively using OPE in practice, and suggest directions for future research.
Landmark Ordinal Embedding
Oct 27, 2019
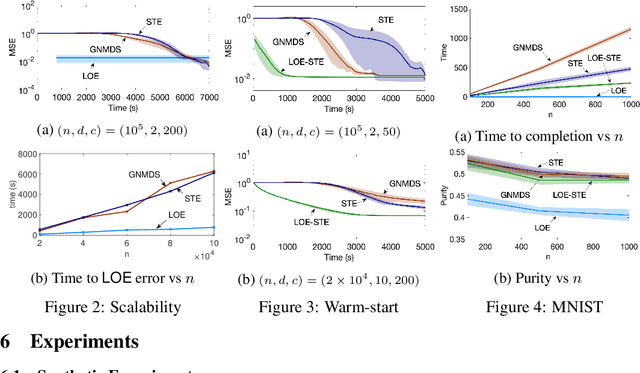
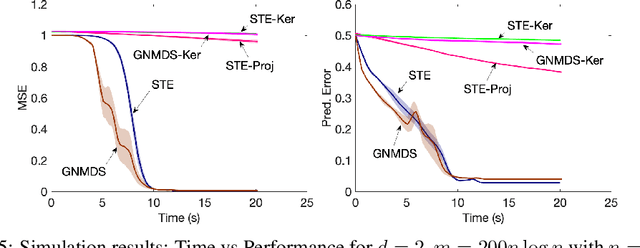
In this paper, we aim to learn a low-dimensional Euclidean representation from a set of constraints of the form "item j is closer to item i than item k". Existing approaches for this "ordinal embedding" problem require expensive optimization procedures, which cannot scale to handle increasingly larger datasets. To address this issue, we propose a landmark-based strategy, which we call Landmark Ordinal Embedding (LOE). Our approach trades off statistical efficiency for computational efficiency by exploiting the low-dimensionality of the latent embedding. We derive bounds establishing the statistical consistency of LOE under the popular Bradley-Terry-Luce noise model. Through a rigorous analysis of the computational complexity, we show that LOE is significantly more efficient than conventional ordinal embedding approaches as the number of items grows. We validate these characterizations empirically on both synthetic and real datasets. We also present a practical approach that achieves the "best of both worlds", by using LOE to warm-start existing methods that are more statistically efficient but computationally expensive.