 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGestureGPT: Zero-shot Interactive Gesture Understanding and Grounding with Large Language Model Agents
Oct 30, 2023



Current gesture recognition systems primarily focus on identifying gestures within a predefined set, leaving a gap in connecting these gestures to interactive GUI elements or system functions (e.g., linking a 'thumb-up' gesture to a 'like' button). We introduce GestureGPT, a novel zero-shot gesture understanding and grounding framework leveraging large language models (LLMs). Gesture descriptions are formulated based on hand landmark coordinates from gesture videos and fed into our dual-agent dialogue system. A gesture agent deciphers these descriptions and queries about the interaction context (e.g., interface, history, gaze data), which a context agent organizes and provides. Following iterative exchanges, the gesture agent discerns user intent, grounding it to an interactive function. We validated the gesture description module using public first-view and third-view gesture datasets and tested the whole system in two real-world settings: video streaming and smart home IoT control. The highest zero-shot Top-5 grounding accuracies are 80.11% for video streaming and 90.78% for smart home tasks, showing potential of the new gesture understanding paradigm.
ZooPFL: Exploring Black-box Foundation Models for Personalized Federated Learning
Oct 08, 2023



When personalized federated learning (FL) meets large foundation models, new challenges arise from various limitations in resources. In addition to typical limitations such as data, computation, and communication costs, access to the models is also often limited. This paper endeavors to solve both the challenges of limited resources and personalization. i.e., distribution shifts between clients. To do so, we propose a method named ZOOPFL that uses Zeroth-Order Optimization for Personalized Federated Learning. ZOOPFL avoids direct interference with the foundation models and instead learns to adapt its inputs through zeroth-order optimization. In addition, we employ simple yet effective linear projections to remap its predictions for personalization. To reduce the computation costs and enhance personalization, we propose input surgery to incorporate an auto-encoder with low-dimensional and client-specific embeddings. We provide theoretical support for ZOOPFL to analyze its convergence. Extensive empirical experiments on computer vision and natural language processing tasks using popular foundation models demonstrate its effectiveness for FL on black-box foundation models.
DIVERSIFY: A General Framework for Time Series Out-of-distribution Detection and Generalization
Aug 04, 2023



Time series remains one of the most challenging modalities in machine learning research. The out-of-distribution (OOD) detection and generalization on time series tend to suffer due to its non-stationary property, i.e., the distribution changes over time. The dynamic distributions inside time series pose great challenges to existing algorithms to identify invariant distributions since they mainly focus on the scenario where the domain information is given as prior knowledge. In this paper, we attempt to exploit subdomains within a whole dataset to counteract issues induced by non-stationary for generalized representation learning. We propose DIVERSIFY, a general framework, for OOD detection and generalization on dynamic distributions of time series. DIVERSIFY takes an iterative process: it first obtains the "worst-case" latent distribution scenario via adversarial training, then reduces the gap between these latent distributions. We implement DIVERSIFY via combining existing OOD detection methods according to either extracted features or outputs of models for detection while we also directly utilize outputs for classification. In addition, theoretical insights illustrate that DIVERSIFY is theoretically supported. Extensive experiments are conducted on seven datasets with different OOD settings across gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition. Qualitative and quantitative results demonstrate that DIVERSIFY learns more generalized features and significantly outperforms other baselines.
FedBone: Towards Large-Scale Federated Multi-Task Learning
Jun 30, 2023



Heterogeneous federated multi-task learning (HFMTL) is a federated learning technique that combines heterogeneous tasks of different clients to achieve more accurate, comprehensive predictions. In real-world applications, visual and natural language tasks typically require large-scale models to extract high-level abstract features. However, large-scale models cannot be directly applied to existing federated multi-task learning methods. Existing HFML methods also disregard the impact of gradient conflicts on multi-task optimization during the federated aggregation process. In this work, we propose an innovative framework called FedBone, which enables the construction of large-scale models with better generalization from the perspective of server-client split learning and gradient projection. We split the entire model into two components: a large-scale general model (referred to as the general model) on the cloud server and multiple task-specific models (referred to as the client model) on edge clients, solving the problem of insufficient computing power on edge clients. The conflicting gradient projection technique is used to enhance the generalization of the large-scale general model between different tasks. The proposed framework is evaluated on two benchmark datasets and a real ophthalmic dataset. Comprehensive results demonstrate that FedBone efficiently adapts to heterogeneous local tasks of each client and outperforms existing federated learning algorithms in most dense prediction and classification tasks with off-the-shelf computational resources on the client side.
FIXED: Frustratingly Easy Domain Generalization with Mixup
Nov 07, 2022Domain generalization (DG) aims to learn a generalizable model from multiple training domains such that it can perform well on unseen target domains. A popular strategy is to augment training data to benefit generalization through methods such as Mixup~\cite{zhang2018mixup}. While the vanilla Mixup can be directly applied, theoretical and empirical investigations uncover several shortcomings that limit its performance. Firstly, Mixup cannot effectively identify the domain and class information that can be used for learning invariant representations. Secondly, Mixup may introduce synthetic noisy data points via random interpolation, which lowers its discrimination capability. Based on the analysis, we propose a simple yet effective enhancement for Mixup-based DG, namely domain-invariant Feature mIXup (FIX). It learns domain-invariant representations for Mixup. To further enhance discrimination, we leverage existing techniques to enlarge margins among classes to further propose the domain-invariant Feature MIXup with Enhanced Discrimination (FIXED) approach. We present theoretical insights about guarantees on its effectiveness. Extensive experiments on seven public datasets across two modalities including image classification (Digits-DG, PACS, Office-Home) and time series (DSADS, PAMAP2, UCI-HAR, and USC-HAD) demonstrate that our approach significantly outperforms nine state-of-the-art related methods, beating the best performing baseline by 6.5\% on average in terms of test accuracy.
Out-of-Distribution Representation Learning for Time Series Classification
Sep 26, 2022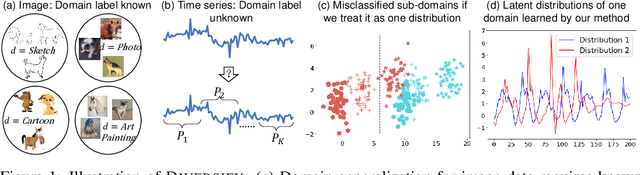
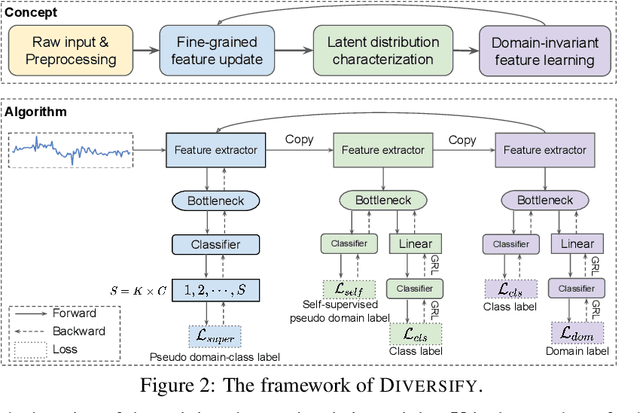
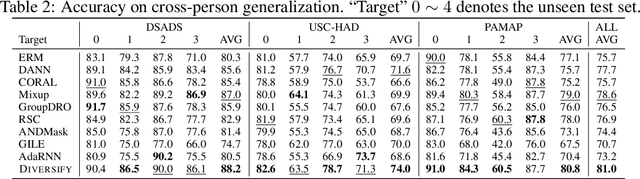
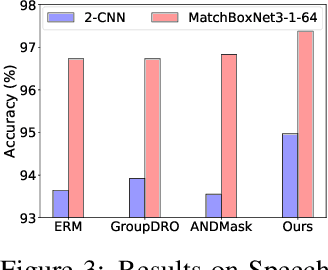
Time series classification is an important problem in real world. Due to its non-stationary property that the distribution changes over time, it remains challenging to build models for generalization to unseen distributions. In this paper, we propose to view the time series classification problem from the distribution perspective. We argue that the temporal complexity attributes to the unknown latent distributions within. To this end, we propose DIVERSIFY to learn generalized representations for time series classification. DIVERSIFY takes an iterative process: it first obtains the worst-case distribution scenario via adversarial training, then matches the distributions of the obtained sub-domains. We also present some theoretical insights. We conduct experiments on gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition with a total of seven datasets in different settings. Results demonstrate that DIVERSIFY significantly outperforms other baselines and effectively characterizes the latent distributions by qualitative and quantitative analysis.
Domain-invariant Feature Exploration for Domain Generalization
Jul 25, 2022

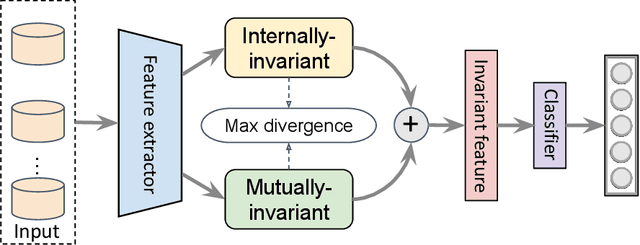

Deep learning has achieved great success in the past few years. However, the performance of deep learning is likely to impede in face of non-IID situations. Domain generalization (DG) enables a model to generalize to an unseen test distribution, i.e., to learn domain-invariant representations. In this paper, we argue that domain-invariant features should be originating from both internal and mutual sides. Internal invariance means that the features can be learned with a single domain and the features capture intrinsic semantics of data, i.e., the property within a domain, which is agnostic to other domains. Mutual invariance means that the features can be learned with multiple domains (cross-domain) and the features contain common information, i.e., the transferable features w.r.t. other domains. We then propose DIFEX for Domain-Invariant Feature EXploration. DIFEX employs a knowledge distillation framework to capture the high-level Fourier phase as the internally-invariant features and learn cross-domain correlation alignment as the mutually-invariant features. We further design an exploration loss to increase the feature diversity for better generalization. Extensive experiments on both time-series and visual benchmarks demonstrate that the proposed DIFEX achieves state-of-the-art performance.
Domain Generalization for Activity Recognition via Adaptive Feature Fusion
Jul 21, 2022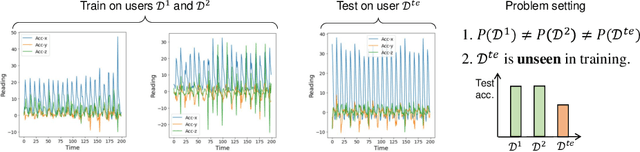

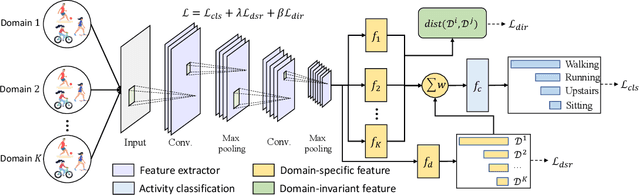

Human activity recognition requires the efforts to build a generalizable model using the training datasets with the hope to achieve good performance in test datasets. However, in real applications, the training and testing datasets may have totally different distributions due to various reasons such as different body shapes, acting styles, and habits, damaging the model's generalization performance. While such a distribution gap can be reduced by existing domain adaptation approaches, they typically assume that the test data can be accessed in the training stage, which is not realistic. In this paper, we consider a more practical and challenging scenario: domain-generalized activity recognition (DGAR) where the test dataset \emph{cannot} be accessed during training. To this end, we propose \emph{Adaptive Feature Fusion for Activity Recognition~(AFFAR)}, a domain generalization approach that learns to fuse the domain-invariant and domain-specific representations to improve the model's generalization performance. AFFAR takes the best of both worlds where domain-invariant representations enhance the transferability across domains and domain-specific representations leverage the model discrimination power from each domain. Extensive experiments on three public HAR datasets show its effectiveness. Furthermore, we apply AFFAR to a real application, i.e., the diagnosis of Children's Attention Deficit Hyperactivity Disorder~(ADHD), which also demonstrates the superiority of our approach.
MetaFed: Federated Learning among Federations with Cyclic Knowledge Distillation for Personalized Healthcare
Jun 17, 2022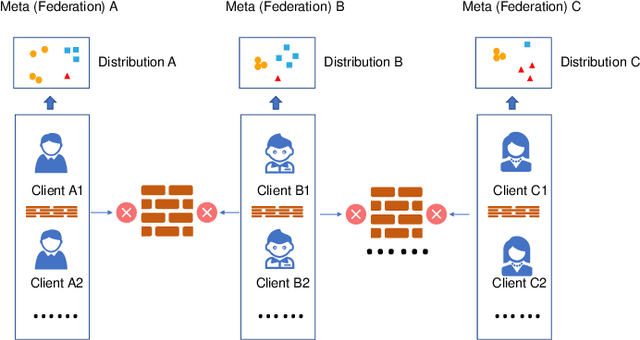
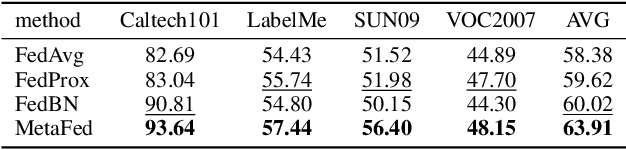
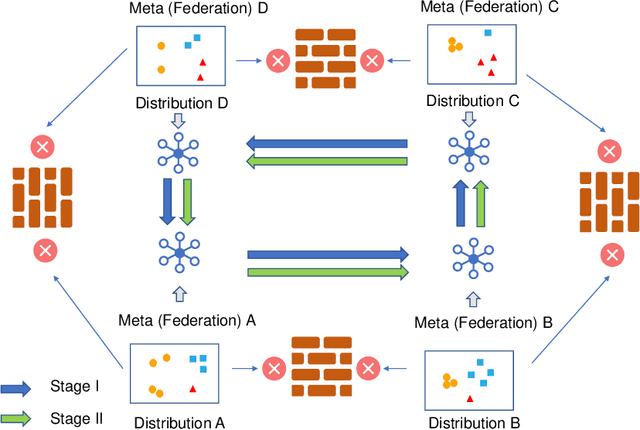

Federated learning has attracted increasing attention to building models without accessing the raw user data, especially in healthcare. In real applications, different federations can seldom work together due to possible reasons such as data heterogeneity and distrust/inexistence of the central server. In this paper, we propose a novel framework called MetaFed to facilitate trustworthy FL between different federations. MetaFed obtains a personalized model for each federation without a central server via the proposed Cyclic Knowledge Distillation. Specifically, MetaFed treats each federation as a meta distribution and aggregates knowledge of each federation in a cyclic manner. The training is split into two parts: common knowledge accumulation and personalization. Comprehensive experiments on three benchmarks demonstrate that MetaFed without a server achieves better accuracy compared to state-of-the-art methods (e.g., 10%+ accuracy improvement compared to the baseline for PAMAP2) with fewer communication costs.
Semantic-Discriminative Mixup for Generalizable Sensor-based Cross-domain Activity Recognition
Jun 14, 2022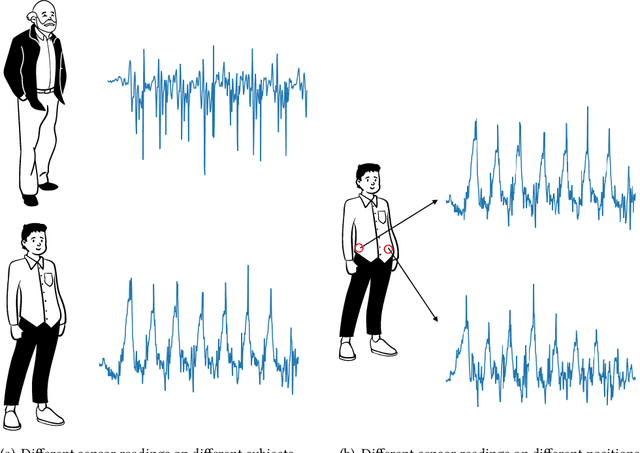
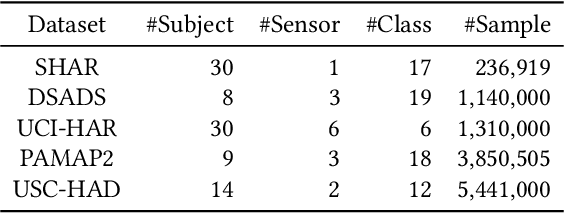
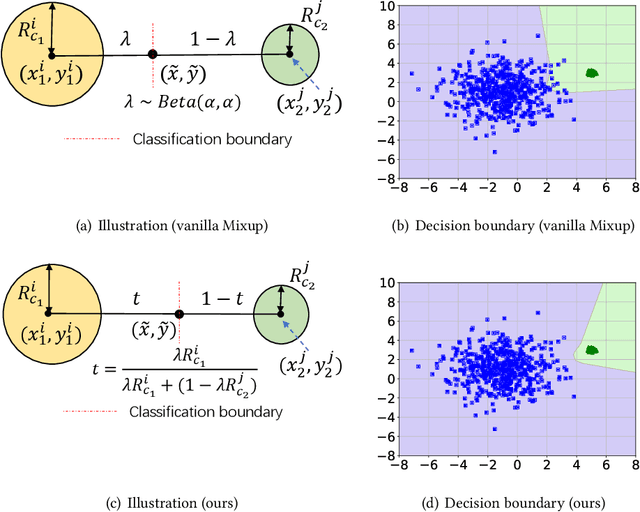
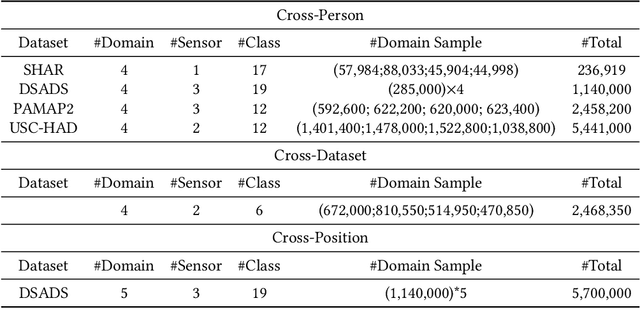
It is expensive and time-consuming to collect sufficient labeled data to build human activity recognition (HAR) models. Training on existing data often makes the model biased towards the distribution of the training data, thus the model might perform terribly on test data with different distributions. Although existing efforts on transfer learning and domain adaptation try to solve the above problem, they still need access to unlabeled data on the target domain, which may not be possible in real scenarios. Few works pay attention to training a model that can generalize well to unseen target domains for HAR. In this paper, we propose a novel method called Semantic-Discriminative Mixup (SDMix) for generalizable cross-domain HAR. Firstly, we introduce semantic-aware Mixup that considers the activity semantic ranges to overcome the semantic inconsistency brought by domain differences. Secondly, we introduce the large margin loss to enhance the discrimination of Mixup to prevent misclassification brought by noisy virtual labels. Comprehensive generalization experiments on five public datasets demonstrate that our SDMix substantially outperforms the state-of-the-art approaches with 6% average accuracy improvement on cross-person, cross-dataset, and cross-position HAR.