 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025



Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
WIP: Large Language Model-Enhanced Smart Tutor for Undergraduate Circuit Analysis
Jun 10, 2025This research-to-practice work-in-progress (WIP) paper presents an AI-enabled smart tutor designed to provide homework assessment and feedback for students in an undergraduate circuit analysis course. We detail the tutor's design philosophy and core components, including open-ended question answering and homework feedback generation. The prompts are carefully crafted to optimize responses across different problems. The smart tutor was deployed on the Microsoft Azure platform and is currently in use in an undergraduate circuit analysis course at the School of Electrical and Computer Engineering in a large, public, research-intensive institution in the Southeastern United States. Beyond offering personalized instruction and feedback, the tutor collects student interaction data, which is summarized and shared with the course instructor. To evaluate its effectiveness, we collected student feedback, with 90.9% of responses indicating satisfaction with the tutor. Additionally, we analyze a subset of collected data on preliminary circuit analysis topics to assess tutor usage frequency for each problem and identify frequently asked questions. These insights help instructors gain real-time awareness of student difficulties, enabling more targeted classroom instruction. In future work, we will release a full analysis once the complete dataset is available after the Spring 2025 semester. We also explore the potential applications of this smart tutor across a broader range of engineering disciplines by developing improved prompts, diagram-recognition methods, and database management strategies, which remain ongoing areas of research.
kTULA: A Langevin sampling algorithm with improved KL bounds under super-linear log-gradients
Jun 05, 2025Motivated by applications in deep learning, where the global Lipschitz continuity condition is often not satisfied, we examine the problem of sampling from distributions with super-linearly growing log-gradients. We propose a novel tamed Langevin dynamics-based algorithm, called kTULA, to solve the aforementioned sampling problem, and provide a theoretical guarantee for its performance. More precisely, we establish a non-asymptotic convergence bound in Kullback-Leibler (KL) divergence with the best-known rate of convergence equal to $2-\overline{\epsilon}$, $\overline{\epsilon}>0$, which significantly improves relevant results in existing literature. This enables us to obtain an improved non-asymptotic error bound in Wasserstein-2 distance, which can be used to further derive a non-asymptotic guarantee for kTULA to solve the associated optimization problems. To illustrate the applicability of kTULA, we apply the proposed algorithm to the problem of sampling from a high-dimensional double-well potential distribution and to an optimization problem involving a neural network. We show that our main results can be used to provide theoretical guarantees for the performance of kTULA.
Diversity of Transformer Layers: One Aspect of Parameter Scaling Laws
May 29, 2025



Transformers deliver outstanding performance across a wide range of tasks and are now a dominant backbone architecture for large language models (LLMs). Their task-solving performance is improved by increasing parameter size, as shown in the recent studies on parameter scaling laws. Although recent mechanistic-interpretability studies have deepened our understanding of the internal behavior of Transformers by analyzing their residual stream, the relationship between these internal mechanisms and the parameter scaling laws remains unclear. To bridge this gap, we focus on layers and their size, which mainly decide the parameter size of Transformers. For this purpose, we first theoretically investigate the layers within the residual stream through a bias-diversity decomposition. The decomposition separates (i) bias, the error of each layer's output from the ground truth, and (ii) diversity, which indicates how much the outputs of each layer differ from each other. Analyzing Transformers under this theory reveals that performance improves when individual layers make predictions close to the correct answer and remain mutually diverse. We show that diversity becomes especially critical when individual layers' outputs are far from the ground truth. Finally, we introduce an information-theoretic diversity and show our main findings that adding layers enhances performance only when those layers behave differently, i.e., are diverse. We also reveal the performance gains from increasing the number of layers exhibit submodularity: marginal improvements diminish as additional layers increase, mirroring the logarithmic convergence predicted by the parameter scaling laws. Experiments on multiple semantic-understanding tasks with various LLMs empirically confirm the theoretical properties derived in this study.
PreMoe: Lightening MoEs on Constrained Memory by Expert Pruning and Retrieval
May 23, 2025



Mixture-of-experts (MoE) architectures enable scaling large language models (LLMs) to vast parameter counts without a proportional rise in computational costs. However, the significant memory demands of large MoE models hinder their deployment across various computational environments, from cloud servers to consumer devices. This study first demonstrates pronounced task-specific specialization in expert activation patterns within MoE layers. Building on this, we introduce PreMoe, a novel framework that enables efficient deployment of massive MoE models in memory-constrained environments. PreMoe features two main components: probabilistic expert pruning (PEP) and task-adaptive expert retrieval (TAER). PEP employs a new metric, the task-conditioned expected selection score (TCESS), derived from router logits to quantify expert importance for specific tasks, thereby identifying a minimal set of critical experts. TAER leverages these task-specific expert importance profiles for efficient inference. It pre-computes and stores compact expert patterns for diverse tasks. When a user query is received, TAER rapidly identifies the most relevant stored task pattern and reconstructs the model by loading only the small subset of experts crucial for that task. This approach dramatically reduces the memory footprint across all deployment scenarios. DeepSeek-R1 671B maintains 97.2\% accuracy on MATH500 when pruned to 8/128 configuration (50\% expert reduction), and still achieves 72.0\% with aggressive 8/32 pruning (87.5\% expert reduction). Pangu-Ultra-MoE 718B achieves 97.15\% on MATH500 and 81.3\% on AIME24 with 8/128 pruning, while even more aggressive pruning to 4/64 (390GB memory) preserves 96.95\% accuracy on MATH500. We make our code publicly available at https://github.com/JarvisPei/PreMoe.
Code Graph Model (CGM): A Graph-Integrated Large Language Model for Repository-Level Software Engineering Tasks
May 22, 2025



Recent advances in Large Language Models (LLMs) have shown promise in function-level code generation, yet repository-level software engineering tasks remain challenging. Current solutions predominantly rely on proprietary LLM agents, which introduce unpredictability and limit accessibility, raising concerns about data privacy and model customization. This paper investigates whether open-source LLMs can effectively address repository-level tasks without requiring agent-based approaches. We demonstrate this is possible by enabling LLMs to comprehend functions and files within codebases through their semantic information and structural dependencies. To this end, we introduce Code Graph Models (CGMs), which integrate repository code graph structures into the LLM's attention mechanism and map node attributes to the LLM's input space using a specialized adapter. When combined with an agentless graph RAG framework, our approach achieves a 43.00% resolution rate on the SWE-bench Lite benchmark using the open-source Qwen2.5-72B model. This performance ranks first among open weight models, second among methods with open-source systems, and eighth overall, surpassing the previous best open-source model-based method by 12.33%.
Understanding Fact Recall in Language Models: Why Two-Stage Training Encourages Memorization but Mixed Training Teaches Knowledge
May 22, 2025



Fact recall, the ability of language models (LMs) to retrieve specific factual knowledge, remains a challenging task despite their impressive general capabilities. Common training strategies often struggle to promote robust recall behavior with two-stage training, which first trains a model with fact-storing examples (e.g., factual statements) and then with fact-recalling examples (question-answer pairs), tending to encourage rote memorization rather than generalizable fact retrieval. In contrast, mixed training, which jointly uses both types of examples, has been empirically shown to improve the ability to recall facts, but the underlying mechanisms are still poorly understood. In this work, we investigate how these training strategies affect how model parameters are shaped during training and how these differences relate to their ability to recall facts. We introduce cross-task gradient trace to identify shared parameters, those strongly influenced by both fact-storing and fact-recalling examples. Our analysis on synthetic fact recall datasets with the Llama-3.2B and Pythia-2.8B models reveals that mixed training encouraging a larger and more centralized set of shared parameters. These findings suggest that the emergence of parameters may play a key role in enabling LMs to generalize factual knowledge across task formulations.
ProDS: Preference-oriented Data Selection for Instruction Tuning
May 19, 2025Instruction data selection aims to identify a high-quality subset from the training set that matches or exceeds the performance of the full dataset on target tasks. Existing methods focus on the instruction-to-response mapping, but neglect the human preference for diverse responses. In this paper, we propose Preference-oriented Data Selection method (ProDS) that scores training samples based on their alignment with preferences observed in the target set. Our key innovation lies in shifting the data selection criteria from merely estimating features for accurate response generation to explicitly aligning training samples with human preferences in target tasks. Specifically, direct preference optimization (DPO) is employed to estimate human preferences across diverse responses. Besides, a bidirectional preference synthesis strategy is designed to score training samples according to both positive preferences and negative preferences. Extensive experimental results demonstrate our superiority to existing task-agnostic and targeted methods.
Video-GPT via Next Clip Diffusion
May 18, 2025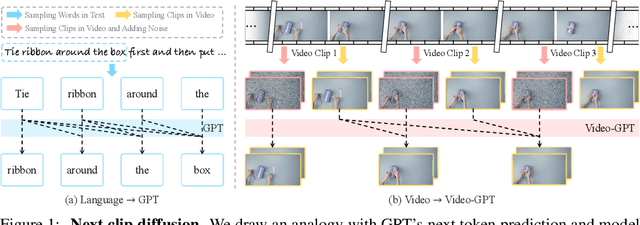

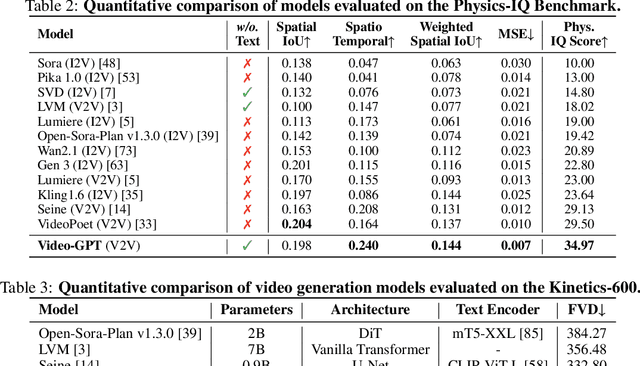
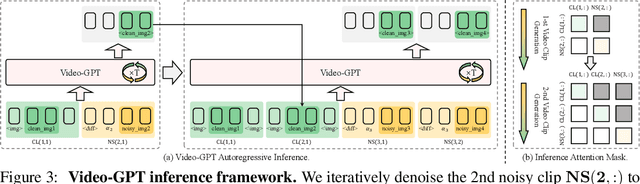
GPT has shown its remarkable success in natural language processing. However, the language sequence is not sufficient to describe spatial-temporal details in the visual world. Alternatively, the video sequence is good at capturing such details. Motivated by this fact, we propose a concise Video-GPT in this paper by treating video as new language for visual world modeling. By analogy to next token prediction in GPT, we introduce a novel next clip diffusion paradigm for pretraining Video-GPT. Different from the previous works, this distinct paradigm allows Video-GPT to tackle both short-term generation and long-term prediction, by autoregressively denoising the noisy clip according to the clean clips in the history. Extensive experiments show our Video-GPT achieves the state-of-the-art performance on video prediction, which is the key factor towards world modeling (Physics-IQ Benchmark: Video-GPT 34.97 vs. Kling 23.64 vs. Wan 20.89). Moreover, it can be well adapted on 6 mainstream video tasks in both video generation and understanding, showing its great generalization capacity in downstream. The project page is at https://Video-GPT.github.io.
JointDistill: Adaptive Multi-Task Distillation for Joint Depth Estimation and Scene Segmentation
May 15, 2025Depth estimation and scene segmentation are two important tasks in intelligent transportation systems. A joint modeling of these two tasks will reduce the requirement for both the storage and training efforts. This work explores how the multi-task distillation could be used to improve such unified modeling. While existing solutions transfer multiple teachers' knowledge in a static way, we propose a self-adaptive distillation method that can dynamically adjust the knowledge amount from each teacher according to the student's current learning ability. Furthermore, as multiple teachers exist, the student's gradient update direction in the distillation is more prone to be erroneous where knowledge forgetting may occur. To avoid this, we propose a knowledge trajectory to record the most essential information that a model has learnt in the past, based on which a trajectory-based distillation loss is designed to guide the student to follow the learning curve similarly in a cost-effective way. We evaluate our method on multiple benchmarking datasets including Cityscapes and NYU-v2. Compared to the state-of-the-art solutions, our method achieves a clearly improvement. The code is provided in the supplementary materials.