 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRD: Local 4D Implicit Representation for High-Fidelity Dynamic Human Modeling
Aug 18, 2022


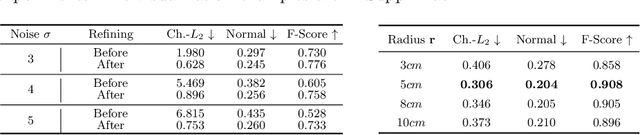
Recent progress in 4D implicit representation focuses on globally controlling the shape and motion with low dimensional latent vectors, which is prone to missing surface details and accumulating tracking error. While many deep local representations have shown promising results for 3D shape modeling, their 4D counterpart does not exist yet. In this paper, we fill this blank by proposing a novel Local 4D implicit Representation for Dynamic clothed human, named LoRD, which has the merits of both 4D human modeling and local representation, and enables high-fidelity reconstruction with detailed surface deformations, such as clothing wrinkles. Particularly, our key insight is to encourage the network to learn the latent codes of local part-level representation, capable of explaining the local geometry and temporal deformations. To make the inference at test-time, we first estimate the inner body skeleton motion to track local parts at each time step, and then optimize the latent codes for each part via auto-decoding based on different types of observed data. Extensive experiments demonstrate that the proposed method has strong capability for representing 4D human, and outperforms state-of-the-art methods on practical applications, including 4D reconstruction from sparse points, non-rigid depth fusion, both qualitatively and quantitatively.
PRIF: Primary Ray-based Implicit Function
Aug 12, 2022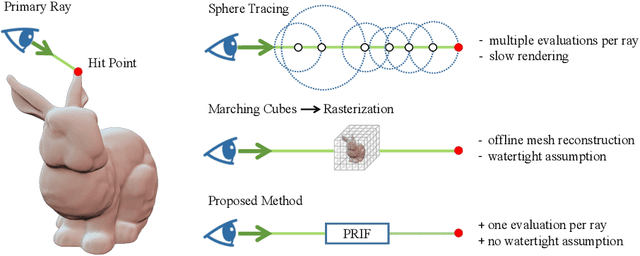
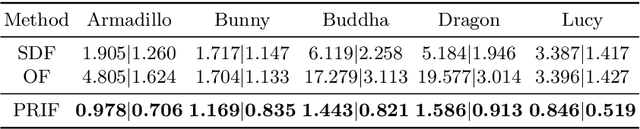
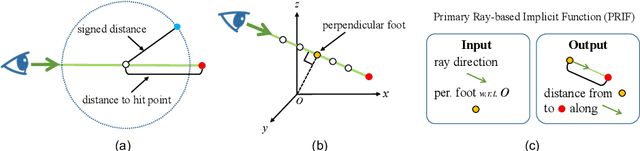

We introduce a new implicit shape representation called Primary Ray-based Implicit Function (PRIF). In contrast to most existing approaches based on the signed distance function (SDF) which handles spatial locations, our representation operates on oriented rays. Specifically, PRIF is formulated to directly produce the surface hit point of a given input ray, without the expensive sphere-tracing operations, hence enabling efficient shape extraction and differentiable rendering. We demonstrate that neural networks trained to encode PRIF achieve successes in various tasks including single shape representation, category-wise shape generation, shape completion from sparse or noisy observations, inverse rendering for camera pose estimation, and neural rendering with color.
NeuMesh: Learning Disentangled Neural Mesh-based Implicit Field for Geometry and Texture Editing
Jul 25, 2022
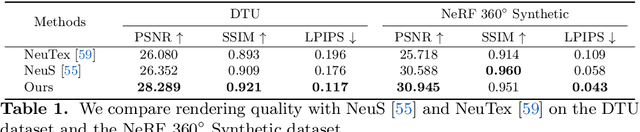
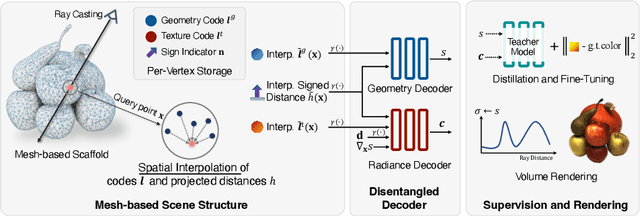
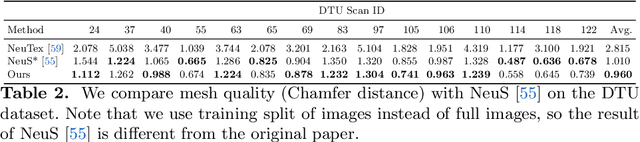
Very recently neural implicit rendering techniques have been rapidly evolved and shown great advantages in novel view synthesis and 3D scene reconstruction. However, existing neural rendering methods for editing purposes offer limited functionality, e.g., rigid transformation, or not applicable for fine-grained editing for general objects from daily lives. In this paper, we present a novel mesh-based representation by encoding the neural implicit field with disentangled geometry and texture codes on mesh vertices, which facilitates a set of editing functionalities, including mesh-guided geometry editing, designated texture editing with texture swapping, filling and painting operations. To this end, we develop several techniques including learnable sign indicators to magnify spatial distinguishability of mesh-based representation, distillation and fine-tuning mechanism to make a steady convergence, and the spatial-aware optimization strategy to realize precise texture editing. Extensive experiments and editing examples on both real and synthetic data demonstrate the superiority of our method on representation quality and editing ability. Code is available on the project webpage: https://zju3dv.github.io/neumesh/.
Neural Rendering in a Room: Amodal 3D Understanding and Free-Viewpoint Rendering for the Closed Scene Composed of Pre-Captured Objects
May 05, 2022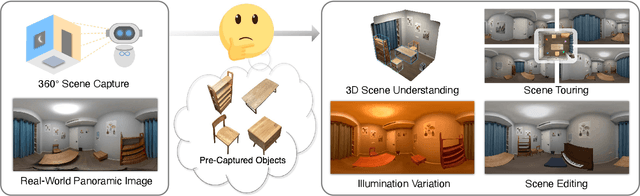
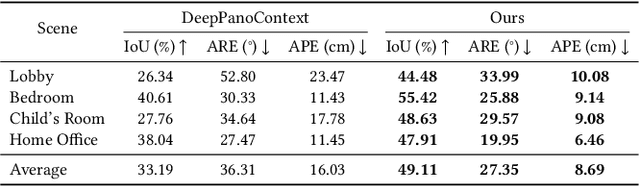
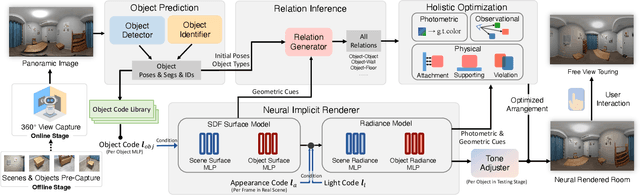
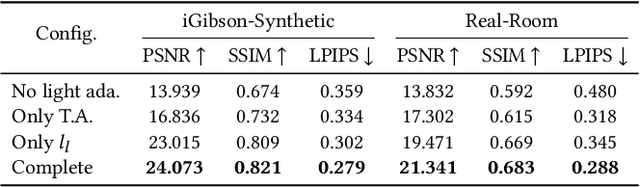
We, as human beings, can understand and picture a familiar scene from arbitrary viewpoints given a single image, whereas this is still a grand challenge for computers. We hereby present a novel solution to mimic such human perception capability based on a new paradigm of amodal 3D scene understanding with neural rendering for a closed scene. Specifically, we first learn the prior knowledge of the objects in a closed scene via an offline stage, which facilitates an online stage to understand the room with unseen furniture arrangement. During the online stage, given a panoramic image of the scene in different layouts, we utilize a holistic neural-rendering-based optimization framework to efficiently estimate the correct 3D scene layout and deliver realistic free-viewpoint rendering. In order to handle the domain gap between the offline and online stage, our method exploits compositional neural rendering techniques for data augmentation in the offline training. The experiments on both synthetic and real datasets demonstrate that our two-stage design achieves robust 3D scene understanding and outperforms competing methods by a large margin, and we also show that our realistic free-viewpoint rendering enables various applications, including scene touring and editing. Code and data are available on the project webpage: https://zju3dv.github.io/nr_in_a_room/.
Density-preserving Deep Point Cloud Compression
Apr 27, 2022
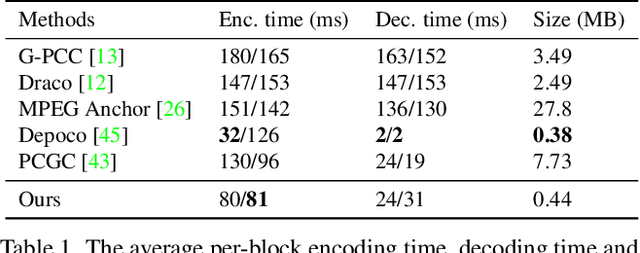

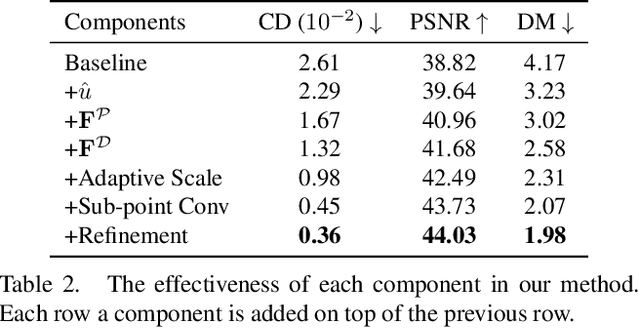
Local density of point clouds is crucial for representing local details, but has been overlooked by existing point cloud compression methods. To address this, we propose a novel deep point cloud compression method that preserves local density information. Our method works in an auto-encoder fashion: the encoder downsamples the points and learns point-wise features, while the decoder upsamples the points using these features. Specifically, we propose to encode local geometry and density with three embeddings: density embedding, local position embedding and ancestor embedding. During the decoding, we explicitly predict the upsampling factor for each point, and the directions and scales of the upsampled points. To mitigate the clustered points issue in existing methods, we design a novel sub-point convolution layer, and an upsampling block with adaptive scale. Furthermore, our method can also compress point-wise attributes, such as normal. Extensive qualitative and quantitative results on SemanticKITTI and ShapeNet demonstrate that our method achieves the state-of-the-art rate-distortion trade-off.
Pixel2Mesh++: 3D Mesh Generation and Refinement from Multi-View Images
Apr 21, 2022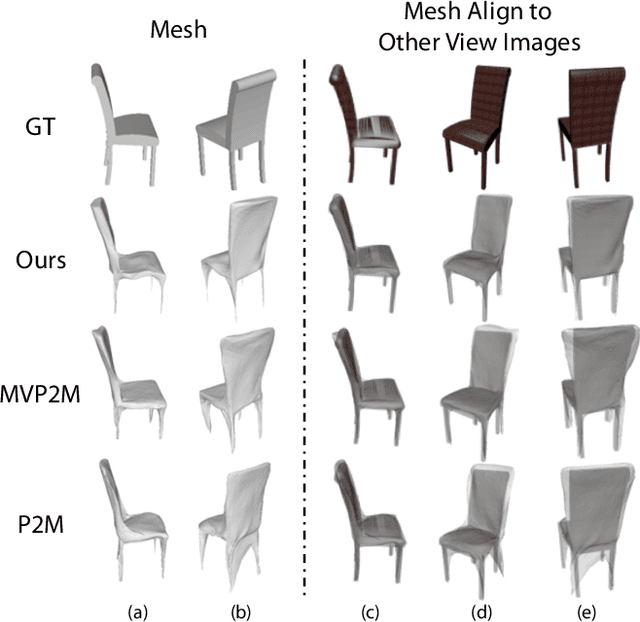
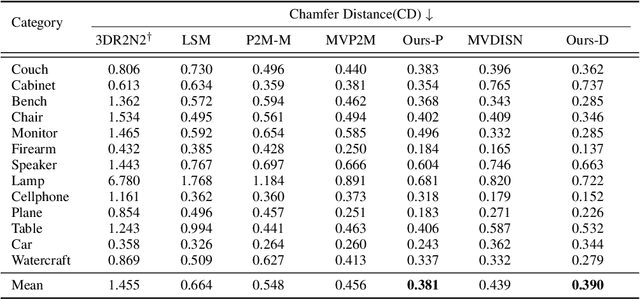
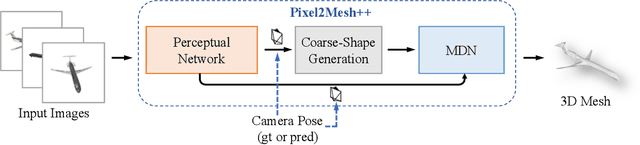
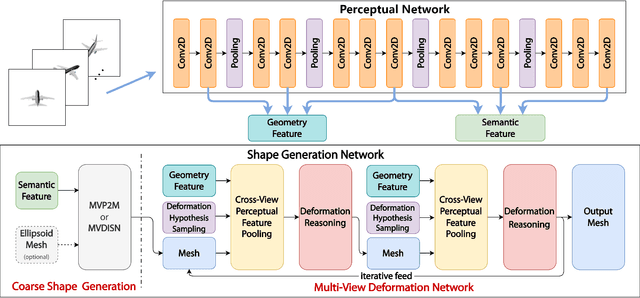
We study the problem of shape generation in 3D mesh representation from a small number of color images with or without camera poses. While many previous works learn to hallucinate the shape directly from priors, we adopt to further improve the shape quality by leveraging cross-view information with a graph convolution network. Instead of building a direct mapping function from images to 3D shape, our model learns to predict series of deformations to improve a coarse shape iteratively. Inspired by traditional multiple view geometry methods, our network samples nearby area around the initial mesh's vertex locations and reasons an optimal deformation using perceptual feature statistics built from multiple input images. Extensive experiments show that our model produces accurate 3D shapes that are not only visually plausible from the input perspectives, but also well aligned to arbitrary viewpoints. With the help of physically driven architecture, our model also exhibits generalization capability across different semantic categories, and the number of input images. Model analysis experiments show that our model is robust to the quality of the initial mesh and the error of camera pose, and can be combined with a differentiable renderer for test-time optimization.
Efficient Virtual View Selection for 3D Hand Pose Estimation
Mar 29, 2022
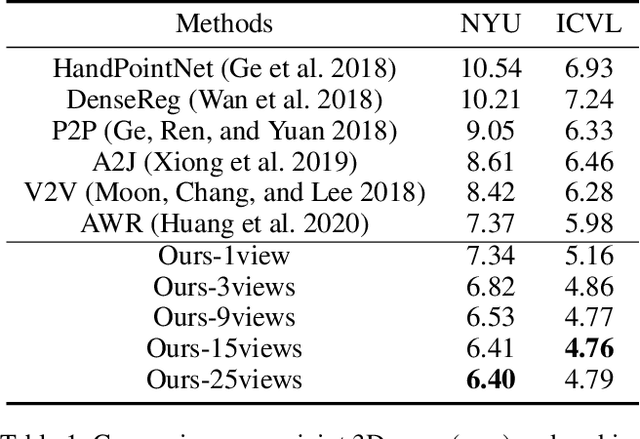
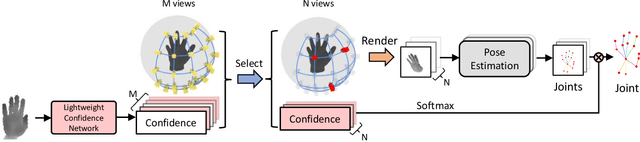
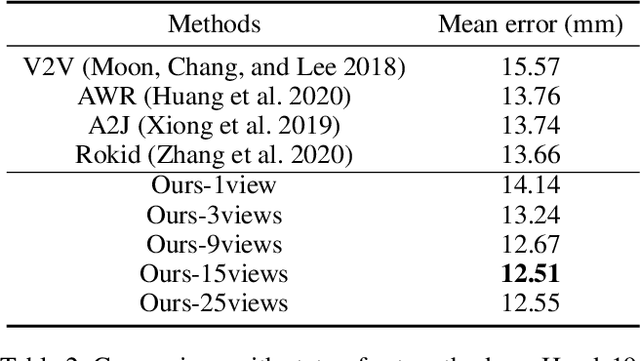
3D hand pose estimation from single depth is a fundamental problem in computer vision, and has wide applications.However, the existing methods still can not achieve satisfactory hand pose estimation results due to view variation and occlusion of human hand. In this paper, we propose a new virtual view selection and fusion module for 3D hand pose estimation from single depth.We propose to automatically select multiple virtual viewpoints for pose estimation and fuse the results of all and find this empirically delivers accurate and robust pose estimation. In order to select most effective virtual views for pose fusion, we evaluate the virtual views based on the confidence of virtual views using a light-weight network via network distillation. Experiments on three main benchmark datasets including NYU, ICVL and Hands2019 demonstrate that our method outperforms the state-of-the-arts on NYU and ICVL, and achieves very competitive performance on Hands2019-Task1, and our proposed virtual view selection and fusion module is both effective for 3D hand pose estimation.
H4D: Human 4D Modeling by Learning Neural Compositional Representation
Mar 02, 2022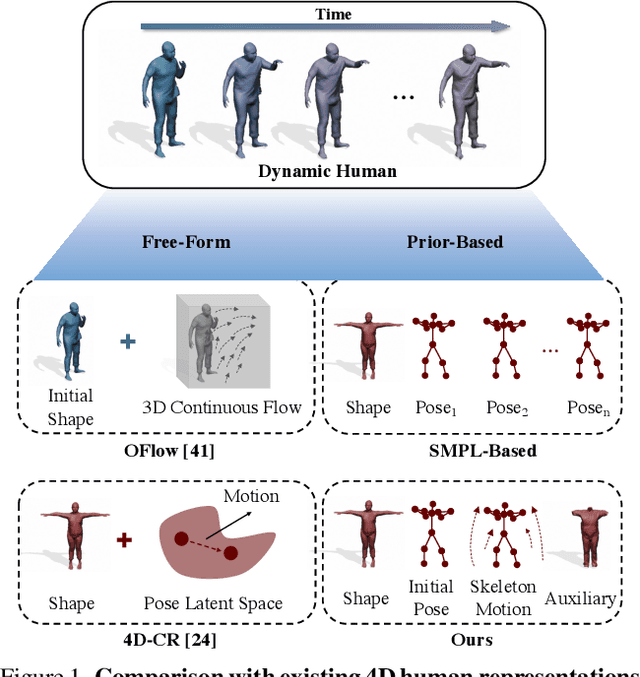
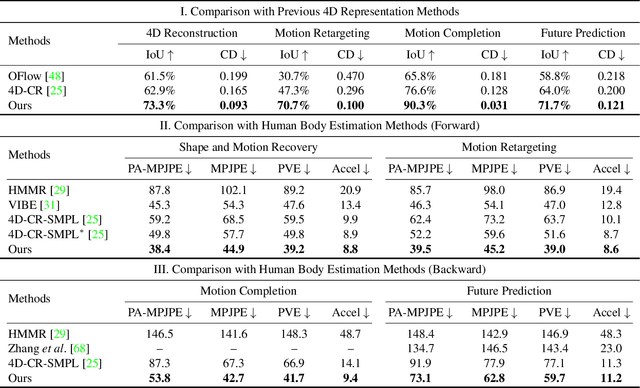
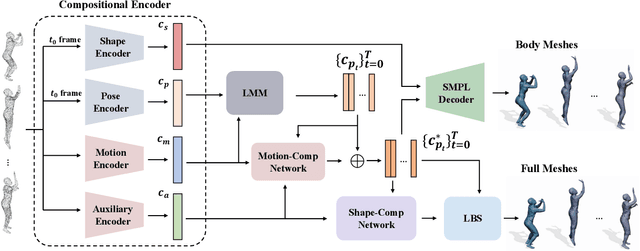
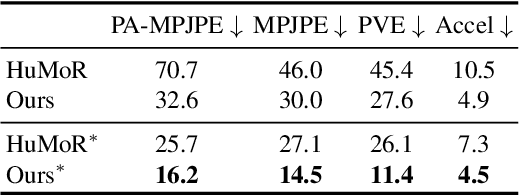
Despite the impressive results achieved by deep learning based 3D reconstruction, the techniques of directly learning to model the 4D human captures with detailed geometry have been less studied. This work presents a novel framework that can effectively learn a compact and compositional representation for dynamic human by exploiting the human body prior from the widely-used SMPL parametric model. Particularly, our representation, named H4D, represents dynamic 3D human over a temporal span into the latent spaces encoding shape, initial pose, motion and auxiliary information. A simple yet effective linear motion model is proposed to provide a rough and regularized motion estimation, followed by per-frame compensation for pose and geometry details with the residual encoded in the auxiliary code. Technically, we introduce novel GRU-based architectures to facilitate learning and improve the representation capability. Extensive experiments demonstrate our method is not only efficacy in recovering dynamic human with accurate motion and detailed geometry, but also amenable to various 4D human related tasks, including motion retargeting, motion completion and future prediction.
OmniSyn: Synthesizing 360 Videos with Wide-baseline Panoramas
Feb 22, 2022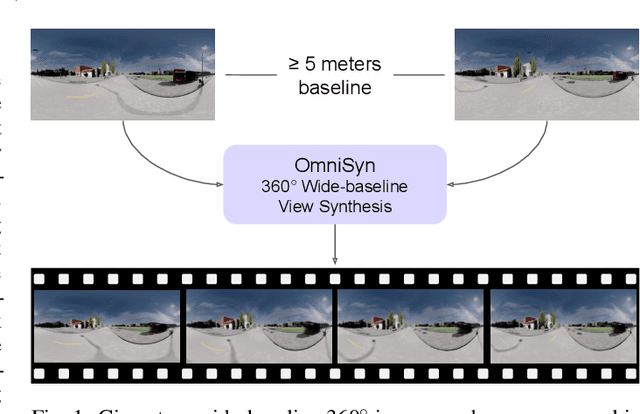


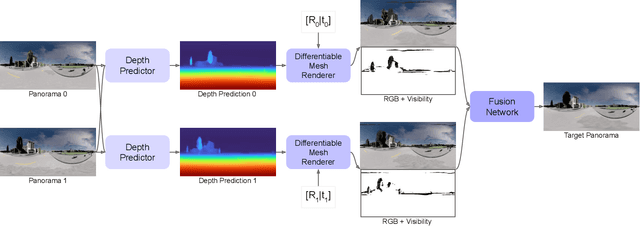
Immersive maps such as Google Street View and Bing Streetside provide true-to-life views with a massive collection of panoramas. However, these panoramas are only available at sparse intervals along the path they are taken, resulting in visual discontinuities during navigation. Prior art in view synthesis is usually built upon a set of perspective images, a pair of stereoscopic images, or a monocular image, but barely examines wide-baseline panoramas, which are widely adopted in commercial platforms to optimize bandwidth and storage usage. In this paper, we leverage the unique characteristics of wide-baseline panoramas and present OmniSyn, a novel pipeline for 360{\deg} view synthesis between wide-baseline panoramas. OmniSyn predicts omnidirectional depth maps using a spherical cost volume and a monocular skip connection, renders meshes in 360{\deg} images, and synthesizes intermediate views with a fusion network. We demonstrate the effectiveness of OmniSyn via comprehensive experimental results including comparison with the state-of-the-art methods on CARLA and Matterport datasets, ablation studies, and generalization studies on street views. We envision our work may inspire future research for this unheeded real-world task and eventually produce a smoother experience for navigating immersive maps.
VoLux-GAN: A Generative Model for 3D Face Synthesis with HDRI Relighting
Jan 13, 2022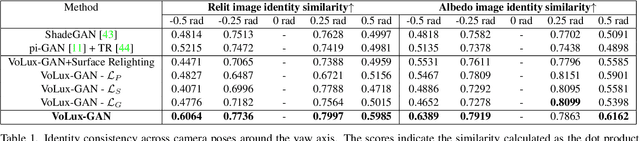
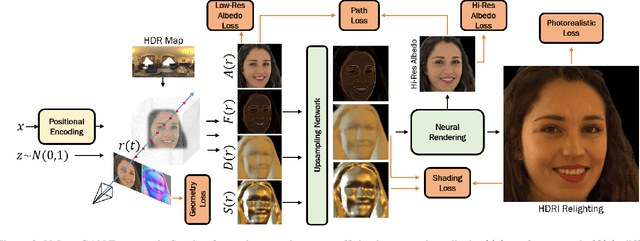
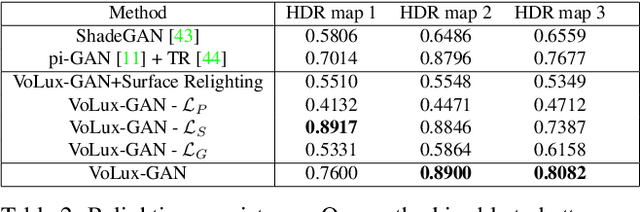

We propose VoLux-GAN, a generative framework to synthesize 3D-aware faces with convincing relighting. Our main contribution is a volumetric HDRI relighting method that can efficiently accumulate albedo, diffuse and specular lighting contributions along each 3D ray for any desired HDR environmental map. Additionally, we show the importance of supervising the image decomposition process using multiple discriminators. In particular, we propose a data augmentation technique that leverages recent advances in single image portrait relighting to enforce consistent geometry, albedo, diffuse and specular components. Multiple experiments and comparisons with other generative frameworks show how our model is a step forward towards photorealistic relightable 3D generative models.