 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNMS Threshold matters for Ego4D Moment Queries -- 2nd place solution to the Ego4D Moment Queries Challenge 2023
Jul 05, 2023



This report describes our submission to the Ego4D Moment Queries Challenge 2023. Our submission extends ActionFormer, a latest method for temporal action localization. Our extension combines an improved ground-truth assignment strategy during training and a refined version of SoftNMS at inference time. Our solution is ranked 2nd on the public leaderboard with 26.62% average mAP and 45.69% Recall@1x at tIoU=0.5 on the test set, significantly outperforming the strong baseline from 2023 challenge. Our code is available at https://github.com/happyharrycn/actionformer_release.
Beyond-Voice: Towards Continuous 3D Hand Pose Tracking on Commercial Home Assistant Devices
Jun 30, 2023Increasingly popular home assistants are widely utilized as the central controller for smart home devices. However, current designs heavily rely on voice interfaces with accessibility and usability issues; some latest ones are equipped with additional cameras and displays, which are costly and raise privacy concerns. These concerns jointly motivate Beyond-Voice, a novel deep-learning-driven acoustic sensing system that allows commodity home assistant devices to track and reconstruct hand poses continuously. It transforms the home assistant into an active sonar system using its existing onboard microphones and speakers. We feed a high-resolution range profile to the deep learning model that can analyze the motions of multiple body parts and predict the 3D positions of 21 finger joints, bringing the granularity for acoustic hand tracking to the next level. It operates across different environments and users without the need for personalized training data. A user study with 11 participants in 3 different environments shows that Beyond-Voice can track joints with an average mean absolute error of 16.47mm without any training data provided by the testing subject.
SimHaze: game engine simulated data for real-world dehazing
May 25, 2023Deep models have demonstrated recent success in single-image dehazing. Most prior methods consider fully supervised training and learn from paired clean and hazy images, where a hazy image is synthesized based on a clean image and its estimated depth map. This paradigm, however, can produce low-quality hazy images due to inaccurate depth estimation, resulting in poor generalization of the trained models. In this paper, we explore an alternative approach for generating paired clean-hazy images by leveraging computer graphics. Using a modern game engine, our approach renders crisp clean images and their precise depth maps, based on which high-quality hazy images can be synthesized for training dehazing models. To this end, we present SimHaze: a new synthetic haze dataset. More importantly, we show that training with SimHaze alone allows the latest dehazing models to achieve significantly better performance in comparison to previous dehazing datasets. Our dataset and code will be made publicly available.
Learning Procedure-aware Video Representation from Instructional Videos and Their Narrations
Mar 31, 2023The abundance of instructional videos and their narrations over the Internet offers an exciting avenue for understanding procedural activities. In this work, we propose to learn video representation that encodes both action steps and their temporal ordering, based on a large-scale dataset of web instructional videos and their narrations, without using human annotations. Our method jointly learns a video representation to encode individual step concepts, and a deep probabilistic model to capture both temporal dependencies and immense individual variations in the step ordering. We empirically demonstrate that learning temporal ordering not only enables new capabilities for procedure reasoning, but also reinforces the recognition of individual steps. Our model significantly advances the state-of-the-art results on step classification (+2.8% / +3.3% on COIN / EPIC-Kitchens) and step forecasting (+7.4% on COIN). Moreover, our model attains promising results in zero-shot inference for step classification and forecasting, as well as in predicting diverse and plausible steps for incomplete procedures. Our code is available at https://github.com/facebookresearch/ProcedureVRL.
InPL: Pseudo-labeling the Inliers First for Imbalanced Semi-supervised Learning
Mar 13, 2023



Recent state-of-the-art methods in imbalanced semi-supervised learning (SSL) rely on confidence-based pseudo-labeling with consistency regularization. To obtain high-quality pseudo-labels, a high confidence threshold is typically adopted. However, it has been shown that softmax-based confidence scores in deep networks can be arbitrarily high for samples far from the training data, and thus, the pseudo-labels for even high-confidence unlabeled samples may still be unreliable. In this work, we present a new perspective of pseudo-labeling for imbalanced SSL. Without relying on model confidence, we propose to measure whether an unlabeled sample is likely to be ``in-distribution''; i.e., close to the current training data. To decide whether an unlabeled sample is ``in-distribution'' or ``out-of-distribution'', we adopt the energy score from out-of-distribution detection literature. As training progresses and more unlabeled samples become in-distribution and contribute to training, the combined labeled and pseudo-labeled data can better approximate the true class distribution to improve the model. Experiments demonstrate that our energy-based pseudo-labeling method, \textbf{InPL}, albeit conceptually simple, significantly outperforms confidence-based methods on imbalanced SSL benchmarks. For example, it produces around 3\% absolute accuracy improvement on CIFAR10-LT. When combined with state-of-the-art long-tailed SSL methods, further improvements are attained. In particular, in one of the most challenging scenarios, InPL achieves a 6.9\% accuracy improvement over the best competitor.
Where a Strong Backbone Meets Strong Features -- ActionFormer for Ego4D Moment Queries Challenge
Nov 16, 2022

This report describes our submission to the Ego4D Moment Queries Challenge 2022. Our submission builds on ActionFormer, the state-of-the-art backbone for temporal action localization, and a trio of strong video features from SlowFast, Omnivore and EgoVLP. Our solution is ranked 2nd on the public leaderboard with 21.76% average mAP on the test set, which is nearly three times higher than the official baseline. Further, we obtain 42.54% Recall@1x at tIoU=0.5 on the test set, outperforming the top-ranked solution by a significant margin of 1.41 absolute percentage points. Our code is available at https://github.com/happyharrycn/actionformer_release.
A Simple Transformer-Based Model for Ego4D Natural Language Queries Challenge
Nov 16, 2022This report describes Badgers@UW-Madison, our submission to the Ego4D Natural Language Queries (NLQ) Challenge. Our solution inherits the point-based event representation from our prior work on temporal action localization, and develops a Transformer-based model for video grounding. Further, our solution integrates several strong video features including SlowFast, Omnivore and EgoVLP. Without bells and whistles, our submission based on a single model achieves 12.64% Mean R@1 and is ranked 2nd on the public leaderboard. Meanwhile, our method garners 28.45% (18.03%) R@5 at tIoU=0.3 (0.5), surpassing the top-ranked solution by up to 5.5 absolute percentage points.
3D Scene Inference from Transient Histograms
Nov 09, 2022



Time-resolved image sensors that capture light at pico-to-nanosecond timescales were once limited to niche applications but are now rapidly becoming mainstream in consumer devices. We propose low-cost and low-power imaging modalities that capture scene information from minimal time-resolved image sensors with as few as one pixel. The key idea is to flood illuminate large scene patches (or the entire scene) with a pulsed light source and measure the time-resolved reflected light by integrating over the entire illuminated area. The one-dimensional measured temporal waveform, called \emph{transient}, encodes both distances and albedoes at all visible scene points and as such is an aggregate proxy for the scene's 3D geometry. We explore the viability and limitations of the transient waveforms by themselves for recovering scene information, and also when combined with traditional RGB cameras. We show that plane estimation can be performed from a single transient and that using only a few more it is possible to recover a depth map of the whole scene. We also show two proof-of-concept hardware prototypes that demonstrate the feasibility of our approach for compact, mobile, and budget-limited applications.
mRI: Multi-modal 3D Human Pose Estimation Dataset using mmWave, RGB-D, and Inertial Sensors
Oct 15, 2022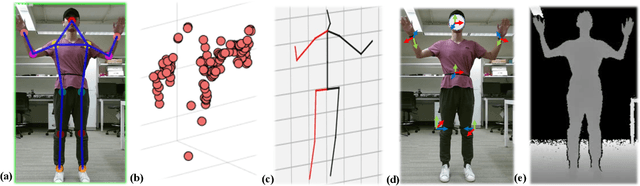
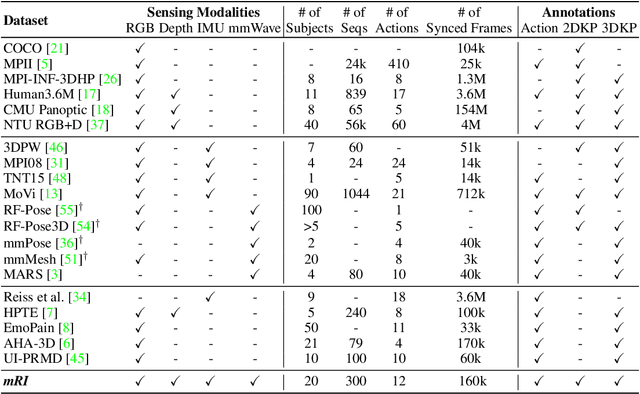


The ability to estimate 3D human body pose and movement, also known as human pose estimation (HPE), enables many applications for home-based health monitoring, such as remote rehabilitation training. Several possible solutions have emerged using sensors ranging from RGB cameras, depth sensors, millimeter-Wave (mmWave) radars, and wearable inertial sensors. Despite previous efforts on datasets and benchmarks for HPE, few dataset exploits multiple modalities and focuses on home-based health monitoring. To bridge the gap, we present mRI, a multi-modal 3D human pose estimation dataset with mmWave, RGB-D, and Inertial Sensors. Our dataset consists of over 160k synchronized frames from 20 subjects performing rehabilitation exercises and supports the benchmarks of HPE and action detection. We perform extensive experiments using our dataset and delineate the strength of each modality. We hope that the release of mRI can catalyze the research in pose estimation, multi-modal learning, and action understanding, and more importantly facilitate the applications of home-based health monitoring.
Particle clustering in turbulence: Prediction of spatial and statistical properties with deep learning
Oct 05, 2022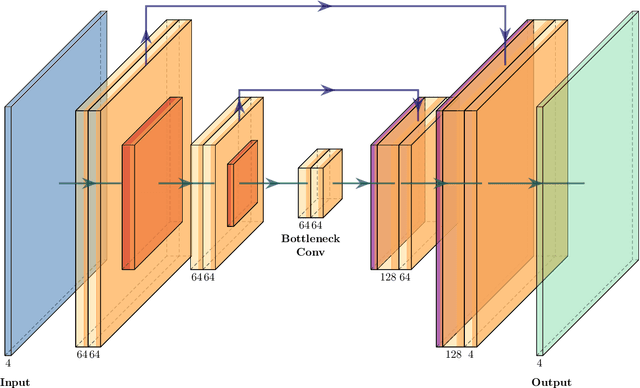
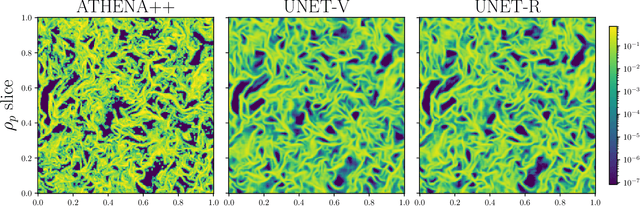
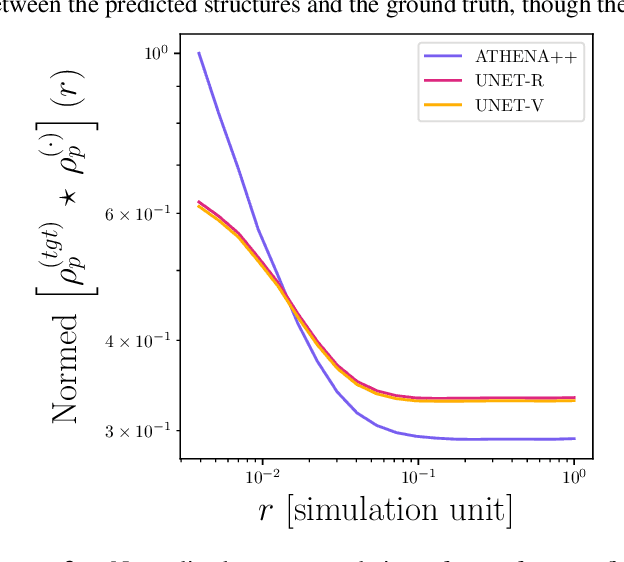
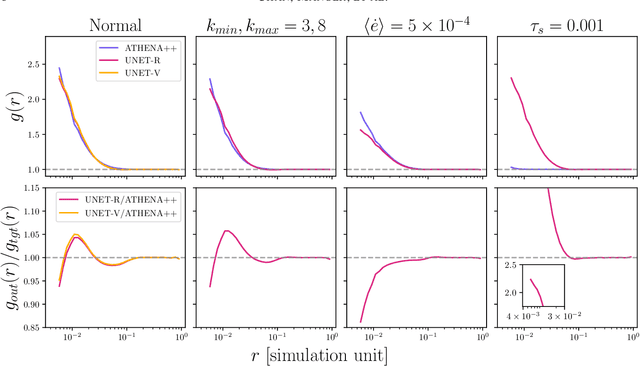
We demonstrate the utility of deep learning for modeling the clustering of particles that are aerodynamically coupled to turbulent fluids. Using a Lagrangian particle module within the ATHENA++ hydrodynamics code, we simulate the dynamics of particles in the Epstein drag regime within a periodic domain of isotropic forced hydrodynamic turbulence. This setup is an idealized model relevant to the collisional growth of micron to mmsized dust particles in early stage planet formation. The simulation data is used to train a U-Net deep learning model to predict gridded three-dimensional representations of the particle density and velocity fields, given as input the corresponding fluid fields. The trained model qualitatively captures the filamentary structure of clustered particles in a highly non-linear regime. We assess model fidelity by calculating metrics of the density structure (the radial distribution function) and of the velocity field (the relative velocity and the relative radial velocity between particles). Although trained only on the spatial fields, the model predicts these statistical quantities with errors that are typically < 10%. Our results suggest that, given appropriately expanded training data, deep learning could be used to accelerate calculations of particle clustering and collision outcomes both in protoplanetary disks, and in related two-fluid turbulence problems that arise in other disciplines.