 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiarisation using location tracking with agglomerative clustering
Sep 24, 2021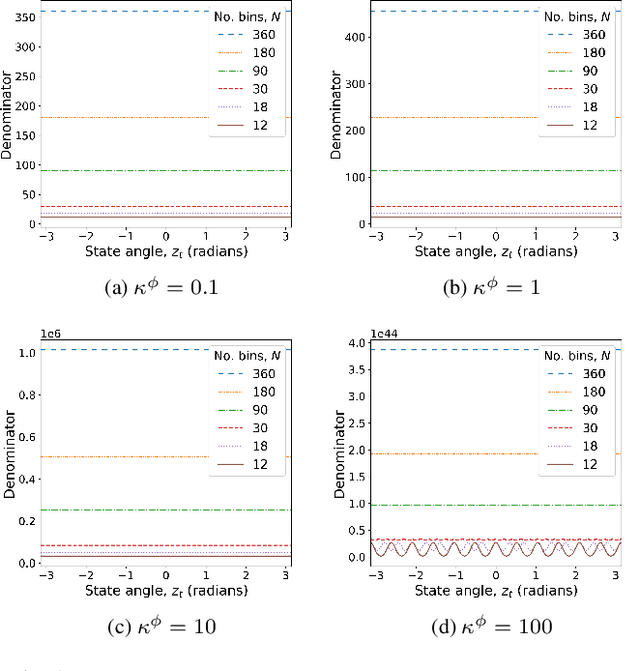
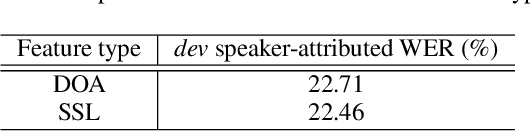
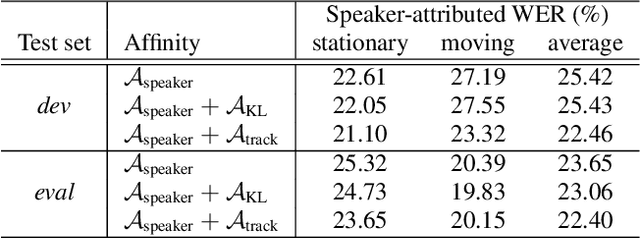
Previous works have shown that spatial location information can be complementary to speaker embeddings for a speaker diarisation task. However, the models used often assume that speakers are fairly stationary throughout a meeting. This paper proposes to relax this assumption, by explicitly modelling the movements of speakers within an Agglomerative Hierarchical Clustering (AHC) diarisation framework. Kalman filters, which track the locations of speakers, are used to compute log-likelihood ratios that contribute to the cluster affinity computations for the AHC merging and stopping decisions. Experiments show that the proposed approach is able to yield improvements on a Microsoft rich meeting transcription task, compared to methods that do not use location information or that make stationarity assumptions.
Joint speaker diarisation and tracking in switching state-space model
Sep 23, 2021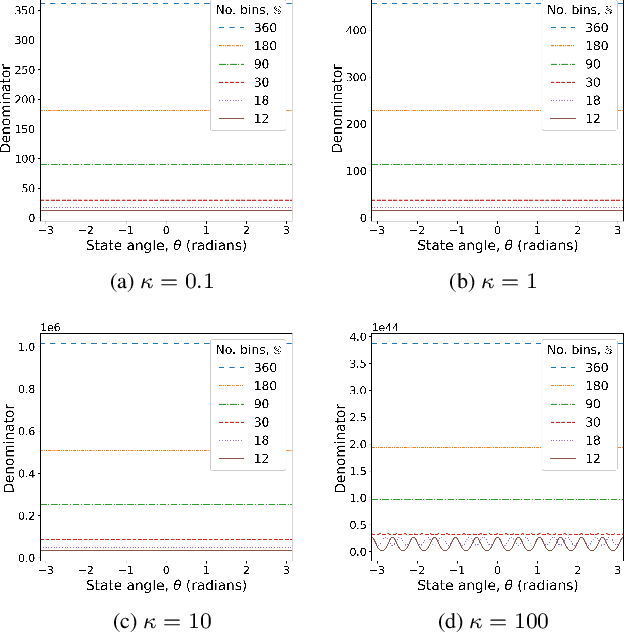

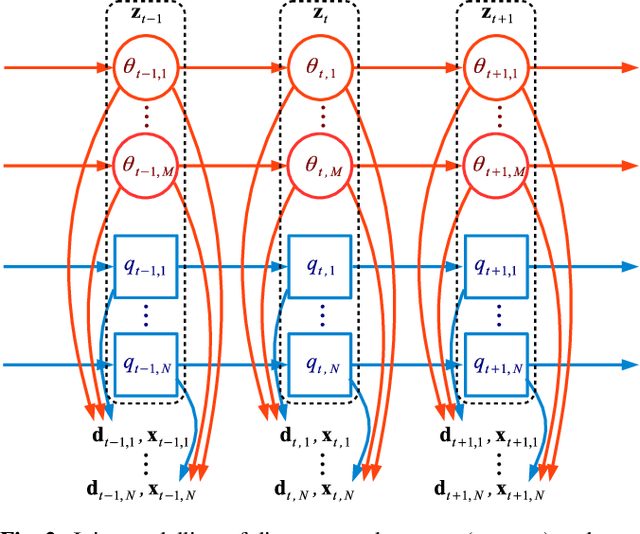
Speakers may move around while diarisation is being performed. When a microphone array is used, the instantaneous locations of where the sounds originated from can be estimated, and previous investigations have shown that such information can be complementary to speaker embeddings in the diarisation task. However, these approaches often assume that speakers are fairly stationary throughout a meeting. This paper relaxes this assumption, by proposing to explicitly track the movements of speakers while jointly performing diarisation within a unified model. A state-space model is proposed, where the hidden state expresses the identity of the current active speaker and the predicted locations of all speakers. The model is implemented as a particle filter. Experiments on a Microsoft rich meeting transcription task show that the proposed joint location tracking and diarisation approach is able to perform comparably with other methods that use location information.
Achieving on-Mobile Real-Time Super-Resolution with Neural Architecture and Pruning Search
Aug 18, 2021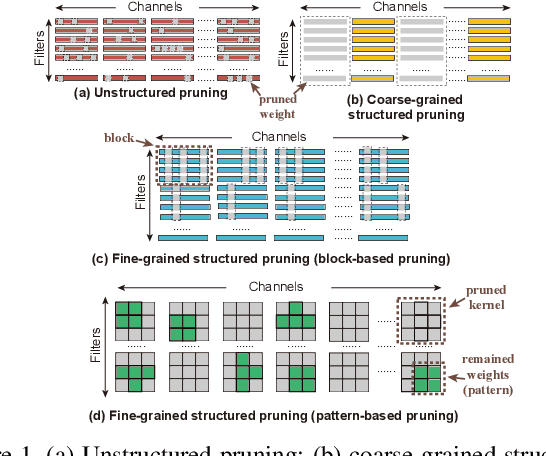
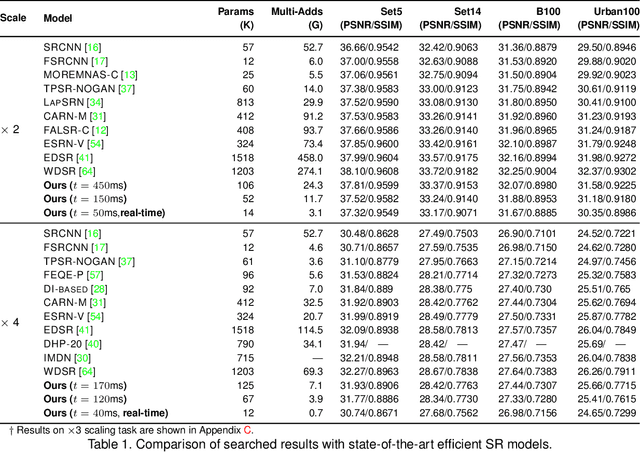
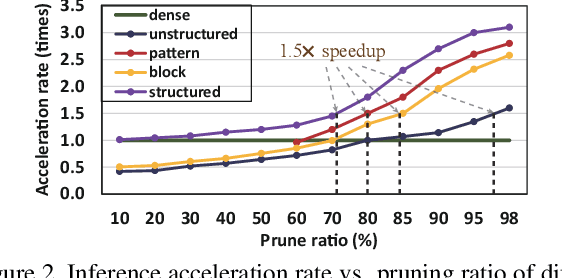
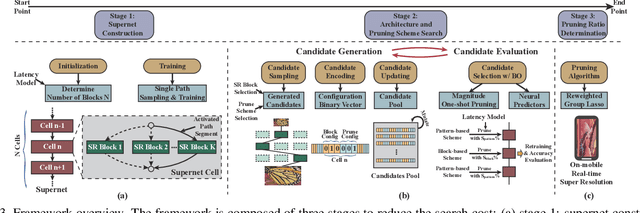
Though recent years have witnessed remarkable progress in single image super-resolution (SISR) tasks with the prosperous development of deep neural networks (DNNs), the deep learning methods are confronted with the computation and memory consumption issues in practice, especially for resource-limited platforms such as mobile devices. To overcome the challenge and facilitate the real-time deployment of SISR tasks on mobile, we combine neural architecture search with pruning search and propose an automatic search framework that derives sparse super-resolution (SR) models with high image quality while satisfying the real-time inference requirement. To decrease the search cost, we leverage the weight sharing strategy by introducing a supernet and decouple the search problem into three stages, including supernet construction, compiler-aware architecture and pruning search, and compiler-aware pruning ratio search. With the proposed framework, we are the first to achieve real-time SR inference (with only tens of milliseconds per frame) for implementing 720p resolution with competitive image quality (in terms of PSNR and SSIM) on mobile platforms (Samsung Galaxy S20).
Minimum Word Error Rate Training with Language Model Fusion for End-to-End Speech Recognition
Jun 04, 2021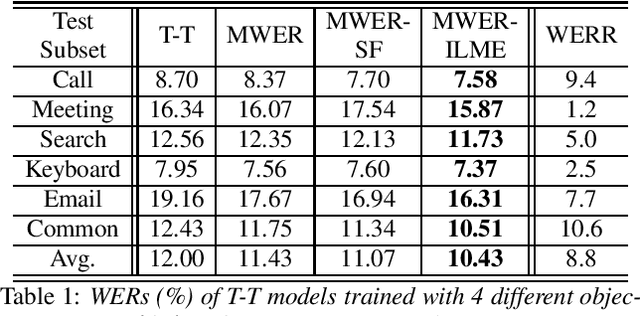
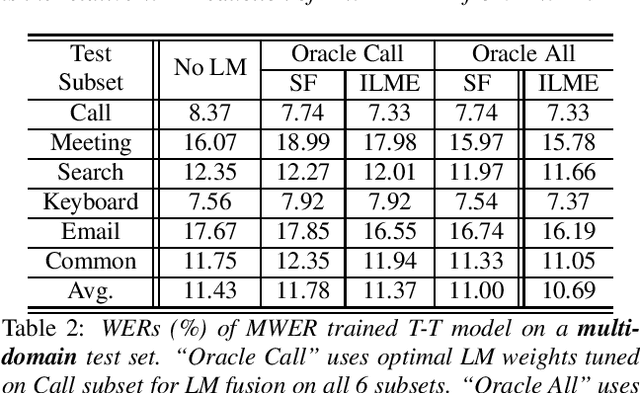
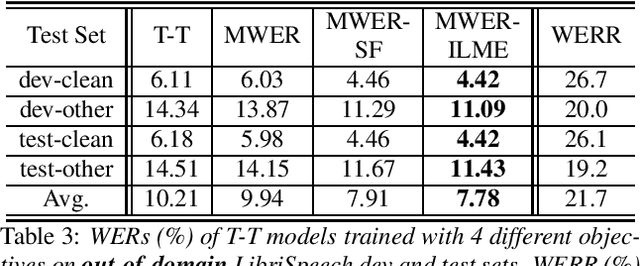
Integrating external language models (LMs) into end-to-end (E2E) models remains a challenging task for domain-adaptive speech recognition. Recently, internal language model estimation (ILME)-based LM fusion has shown significant word error rate (WER) reduction from Shallow Fusion by subtracting a weighted internal LM score from an interpolation of E2E model and external LM scores during beam search. However, on different test sets, the optimal LM interpolation weights vary over a wide range and have to be tuned extensively on well-matched validation sets. In this work, we perform LM fusion in the minimum WER (MWER) training of an E2E model to obviate the need for LM weights tuning during inference. Besides MWER training with Shallow Fusion (MWER-SF), we propose a novel MWER training with ILME (MWER-ILME) where the ILME-based fusion is conducted to generate N-best hypotheses and their posteriors. Additional gradient is induced when internal LM is engaged in MWER-ILME loss computation. During inference, LM weights pre-determined in MWER training enable robust LM integrations on test sets from different domains. Experimented with 30K-hour trained transformer transducers, MWER-ILME achieves on average 8.8% and 5.8% relative WER reductions from MWER and MWER-SF training, respectively, on 6 different test sets
* 5 pages, Interspeech 2021
On Addressing Practical Challenges for RNN-Transducer
May 04, 2021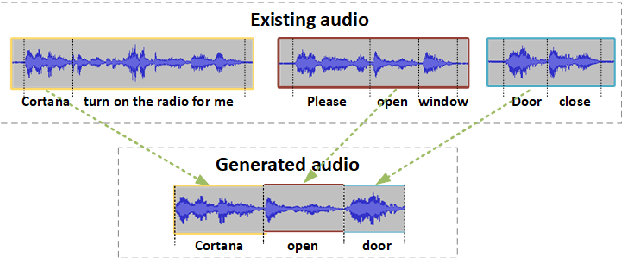


In this paper, several works are proposed to address practical challenges for deploying RNN Transducer (RNN-T) based speech recognition system. These challenges are adapting a well-trained RNN-T model to a new domain without collecting the audio data, obtaining time stamps and confidence scores at word level. The first challenge is solved with a splicing data method which concatenates the speech segments extracted from the source domain data. To get the time stamp, a phone prediction branch is added to the RNN-T model by sharing the encoder for the purpose of force alignment. Finally, we obtain word-level confidence scores by utilizing several types of features calculated during decoding and from confusion network. Evaluated with Microsoft production data, the splicing data adaptation method improves the baseline and adaption with the text to speech method by 58.03% and 15.25% relative word error rate reduction, respectively. The proposed time stamping method can get less than 50ms word timing difference on average while maintaining the recognition accuracy of the RNN-T model. We also obtain high confidence annotation performance with limited computation cost.
Streaming Multi-talker Speech Recognition with Joint Speaker Identification
Apr 05, 2021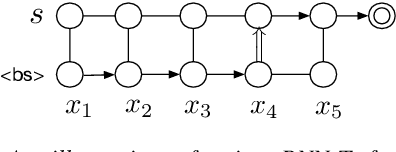
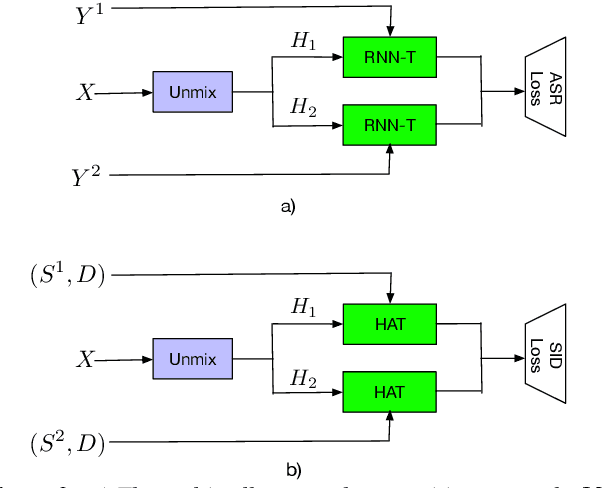
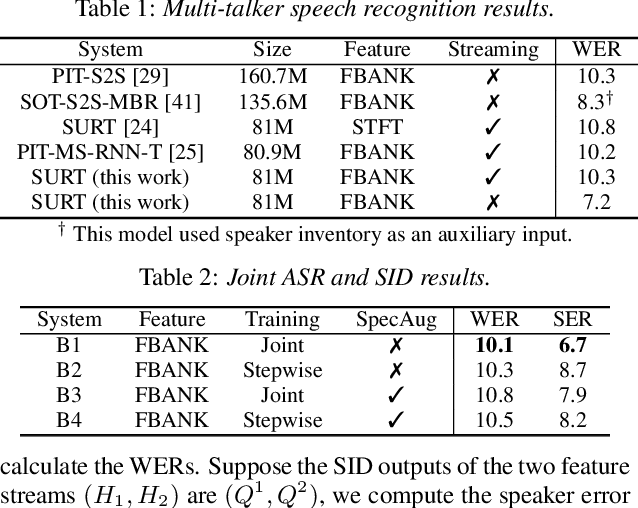
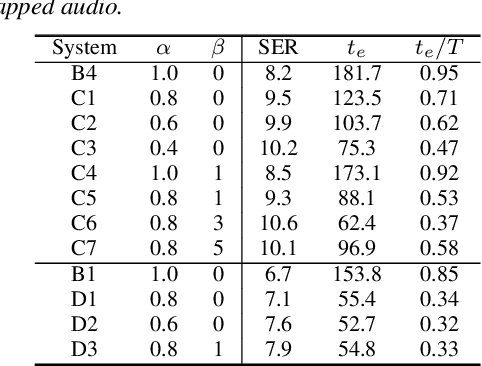
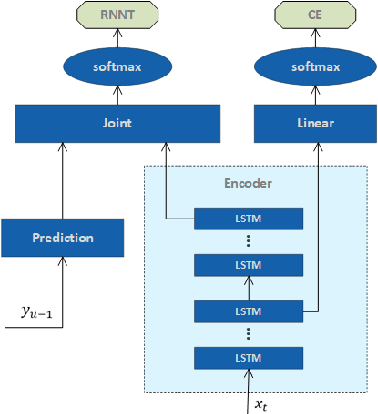
In multi-talker scenarios such as meetings and conversations, speech processing systems are usually required to transcribe the audio as well as identify the speakers for downstream applications. Since overlapped speech is common in this case, conventional approaches usually address this problem in a cascaded fashion that involves speech separation, speech recognition and speaker identification that are trained independently. In this paper, we propose Streaming Unmixing, Recognition and Identification Transducer (SURIT) -- a new framework that deals with this problem in an end-to-end streaming fashion. SURIT employs the recurrent neural network transducer (RNN-T) as the backbone for both speech recognition and speaker identification. We validate our idea on the LibrispeechMix dataset -- a multi-talker dataset derived from Librispeech, and present encouraging results.
Internal Language Model Training for Domain-Adaptive End-to-End Speech Recognition
Feb 02, 2021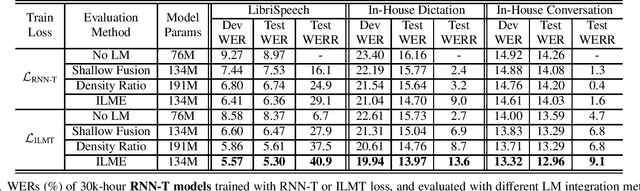
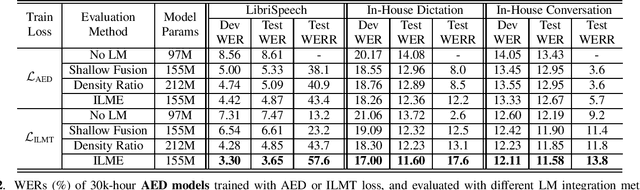
The efficacy of external language model (LM) integration with existing end-to-end (E2E) automatic speech recognition (ASR) systems can be improved significantly using the internal language model estimation (ILME) method. In this method, the internal LM score is subtracted from the score obtained by interpolating the E2E score with the external LM score, during inference. To improve the ILME-based inference, we propose an internal LM training (ILMT) method to minimize an additional internal LM loss by updating only the E2E model components that affect the internal LM estimation. ILMT encourages the E2E model to form a standalone LM inside its existing components, without sacrificing ASR accuracy. After ILMT, the more modular E2E model with matched training and inference criteria enables a more thorough elimination of the source-domain internal LM, and therefore leads to a more effective integration of the target-domain external LM. Experimented with 30K-hour trained recurrent neural network transducer and attention-based encoder-decoder models, ILMT with ILME-based inference achieves up to 31.5% and 11.4% relative word error rate reductions from standard E2E training with Shallow Fusion on out-of-domain LibriSpeech and in-domain Microsoft production test sets, respectively.
* 5 pages, ICASSP 2021
Streaming end-to-end multi-talker speech recognition
Nov 26, 2020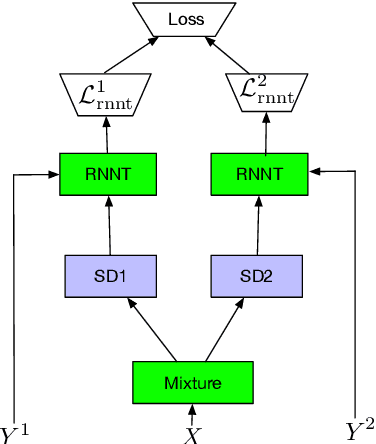

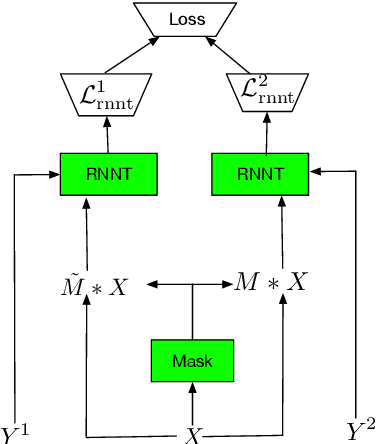

End-to-end multi-talker speech recognition is an emerging research trend in the speech community due to its vast potential in applications such as conversation and meeting transcriptions. To the best of our knowledge, all existing research works are constrained in the offline scenario. In this work, we propose the Streaming Unmixing and Recognition Transducer (SURT) for end-to-end multi-talker speech recognition. Our model employs the Recurrent Neural Network Transducer as the backbone that can meet various latency constraints. We study two different model architectures that are based on a speaker-differentiator encoder and a mask encoder respectively. To train this model, we investigate the widely used Permutation Invariant Training (PIT) approach and the recently introduced Heuristic Error Assignment Training (HEAT) approach. Based on experiments on the publicly available LibriSpeechMix dataset, we show that HEAT can achieve better accuracy compared with PIT, and the SURT model with 120 milliseconds algorithmic latency constraint compares favorably with the offline sequence-to-sequence based baseline model in terms of accuracy.
Internal Language Model Estimation for Domain-Adaptive End-to-End Speech Recognition
Nov 03, 2020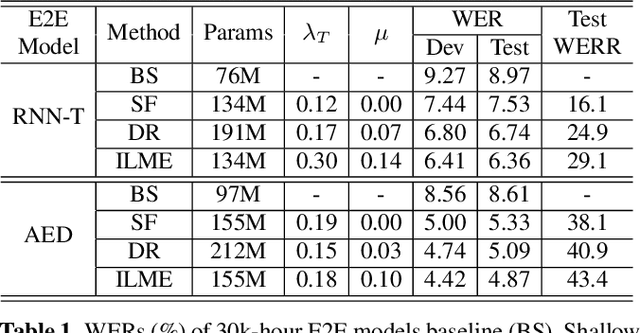
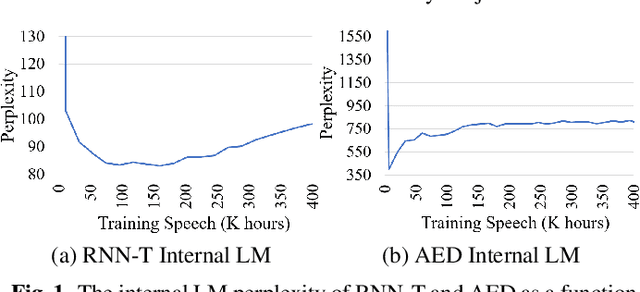
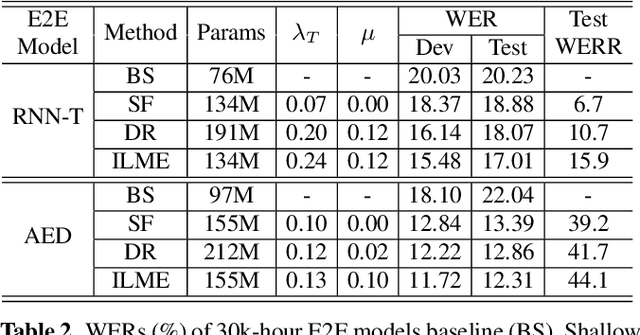
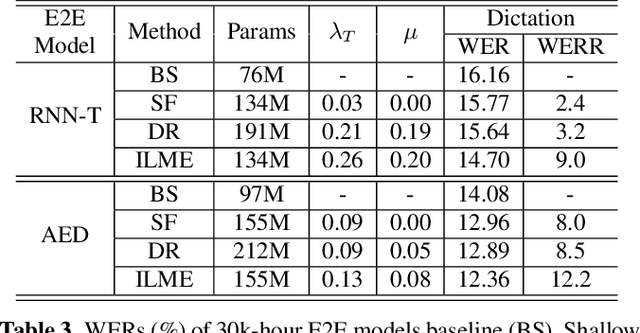
The external language models (LM) integration remains a challenging task for end-to-end (E2E) automatic speech recognition (ASR) which has no clear division between acoustic and language models. In this work, we propose an internal LM estimation (ILME) method to facilitate a more effective integration of the external LM with all pre-existing E2E models with no additional model training, including the most popular recurrent neural network transducer (RNN-T) and attention-based encoder-decoder (AED) models. Trained with audio-transcript pairs, an E2E model implicitly learns an internal LM that characterizes the training data in the source domain. With ILME, the internal LM scores of an E2E model are estimated and subtracted from the log-linear interpolation between the scores of the E2E model and the external LM. The internal LM scores are approximated as the output of an E2E model when eliminating its acoustic components. ILME can alleviate the domain mismatch between training and testing, or improve the multi-domain E2E ASR. Experimented with 30K-hour trained RNN-T and AED models, ILME achieves up to 15.5% and 6.8% relative word error rate reductions from Shallow Fusion on out-of-domain LibriSpeech and in-domain Microsoft production test sets, respectively.
* 8 pages, 2 figures, SLT 2021
On Minimum Word Error Rate Training of the Hybrid Autoregressive Transducer
Oct 23, 2020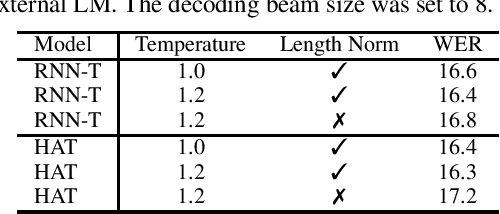
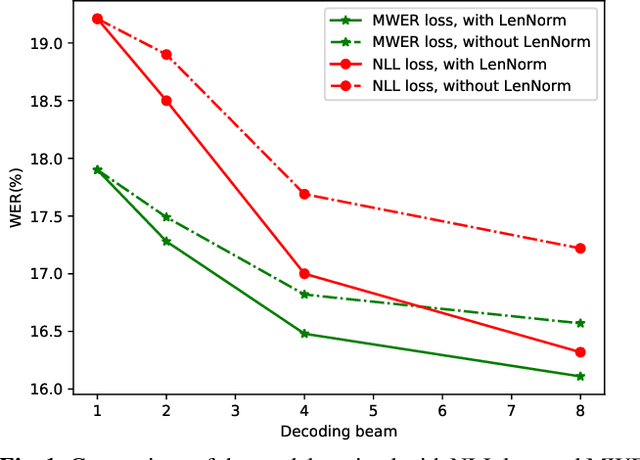
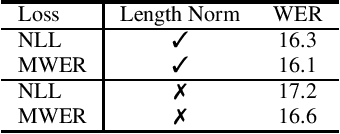
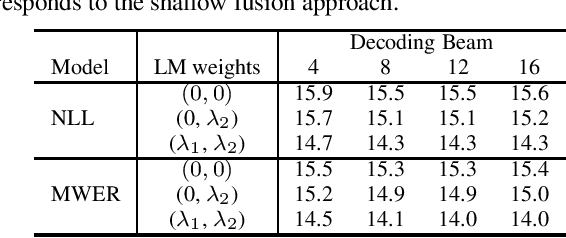
Hybrid Autoregressive Transducer (HAT) is a recently proposed end-to-end acoustic model that extends the standard Recurrent Neural Network Transducer (RNN-T) for the purpose of the external language model (LM) fusion. In HAT, the blank probability and the label probability are estimated using two separate probability distributions, which provides a more accurate solution for internal LM score estimation, and thus works better when combining with an external LM. Previous work mainly focuses on HAT model training with the negative log-likelihood loss, while in this paper, we study the minimum word error rate (MWER) training of HAT -- a criterion that is closer to the evaluation metric for speech recognition, and has been successfully applied to other types of end-to-end models such as sequence-to-sequence (S2S) and RNN-T models. From experiments with around 30,000 hours of training data, we show that MWER training can improve the accuracy of HAT models, while at the same time, improving the robustness of the model against the decoding hyper-parameters such as length normalization and decoding beam during inference.