 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliability-Adaptive Consistency Regularization for Weakly-Supervised Point Cloud Segmentation
Mar 09, 2023



Weakly-supervised point cloud segmentation with extremely limited labels is highly desirable to alleviate the expensive costs of collecting densely annotated 3D points. This paper explores to apply the consistency regularization that is commonly used in weakly-supervised learning, for its point cloud counterpart with multiple data-specific augmentations, which has not been well studied. We observe that the straightforward way of applying consistency constraints to weakly-supervised point cloud segmentation has two major limitations: noisy pseudo labels due to the conventional confidence-based selection and insufficient consistency constraints due to discarding unreliable pseudo labels. Therefore, we propose a novel Reliability-Adaptive Consistency Network (RAC-Net) to use both prediction confidence and model uncertainty to measure the reliability of pseudo labels and apply consistency training on all unlabeled points while with different consistency constraints for different points based on the reliability of corresponding pseudo labels. Experimental results on the S3DIS and ScanNet-v2 benchmark datasets show that our model achieves superior performance in weakly-supervised point cloud segmentation. The code will be released.
Privacy-Preserving Visual Localization with Event Cameras
Dec 08, 2022



We present a robust, privacy-preserving visual localization algorithm using event cameras. While event cameras can potentially make robust localization due to high dynamic range and small motion blur, the sensors exhibit large domain gaps making it difficult to directly apply conventional image-based localization algorithms. To mitigate the gap, we propose applying event-to-image conversion prior to localization which leads to stable localization. In the privacy perspective, event cameras capture only a fraction of visual information compared to normal cameras, and thus can naturally hide sensitive visual details. To further enhance the privacy protection in our event-based pipeline, we introduce privacy protection at two levels, namely sensor and network level. Sensor level protection aims at hiding facial details with lightweight filtering while network level protection targets hiding the entire user's view in private scene applications using a novel neural network inference pipeline. Both levels of protection involve light-weight computation and incur only a small performance loss. We thus project our method to serve as a building block for practical location-based services using event cameras. The code and dataset will be made public through the following link: https://github.com/82magnolia/event_localization.
Seeing Far in the Dark with Patterned Flash
Jul 25, 2022
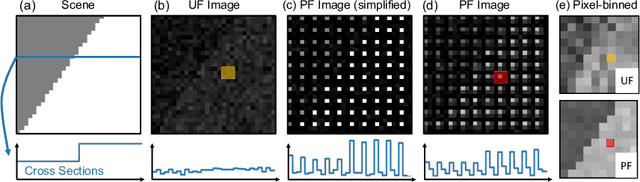
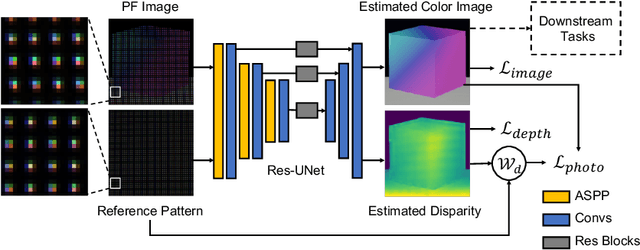
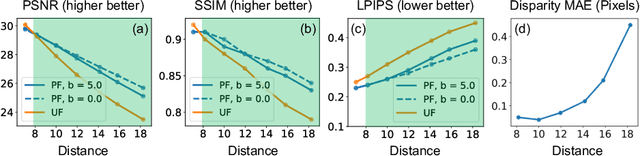
Flash illumination is widely used in imaging under low-light environments. However, illumination intensity falls off with propagation distance quadratically, which poses significant challenges for flash imaging at a long distance. We propose a new flash technique, named ``patterned flash'', for flash imaging at a long distance. Patterned flash concentrates optical power into a dot array. Compared with the conventional uniform flash where the signal is overwhelmed by the noise everywhere, patterned flash provides stronger signals at sparsely distributed points across the field of view to ensure the signals at those points stand out from the sensor noise. This enables post-processing to resolve important objects and details. Additionally, the patterned flash projects texture onto the scene, which can be treated as a structured light system for depth perception. Given the novel system, we develop a joint image reconstruction and depth estimation algorithm with a convolutional neural network. We build a hardware prototype and test the proposed flash technique on various scenes. The experimental results demonstrate that our patterned flash has significantly better performance at long distances in low-light environments.
Dual Adaptive Transformations for Weakly Supervised Point Cloud Segmentation
Jul 19, 2022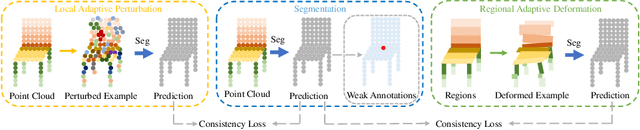
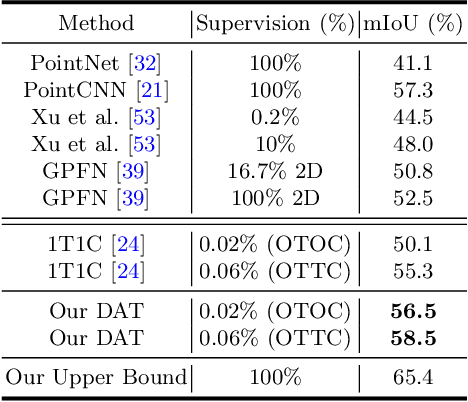
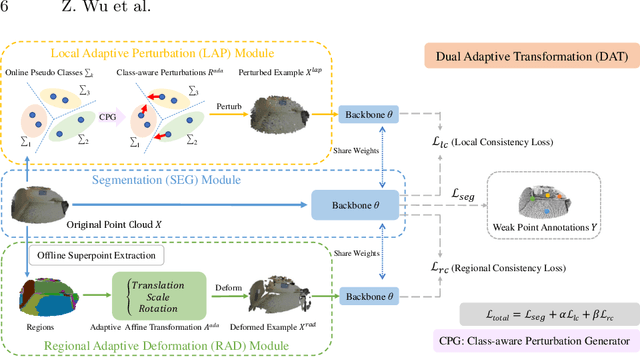

Weakly supervised point cloud segmentation, i.e. semantically segmenting a point cloud with only a few labeled points in the whole 3D scene, is highly desirable due to the heavy burden of collecting abundant dense annotations for the model training. However, existing methods remain challenging to accurately segment 3D point clouds since limited annotated data may lead to insufficient guidance for label propagation to unlabeled data. Considering the smoothness-based methods have achieved promising progress, in this paper, we advocate applying the consistency constraint under various perturbations to effectively regularize unlabeled 3D points. Specifically, we propose a novel DAT (\textbf{D}ual \textbf{A}daptive \textbf{T}ransformations) model for weakly supervised point cloud segmentation, where the dual adaptive transformations are performed via an adversarial strategy at both point-level and region-level, aiming at enforcing the local and structural smoothness constraints on 3D point clouds. We evaluate our proposed DAT model with two popular backbones on the large-scale S3DIS and ScanNet-V2 datasets. Extensive experiments demonstrate that our model can effectively leverage the unlabeled 3D points and achieve significant performance gains on both datasets, setting new state-of-the-art performance for weakly supervised point cloud segmentation.
Structured Light with Redundancy Codes
Jun 18, 2022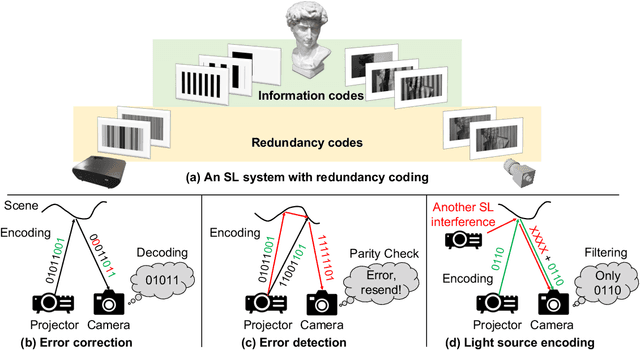
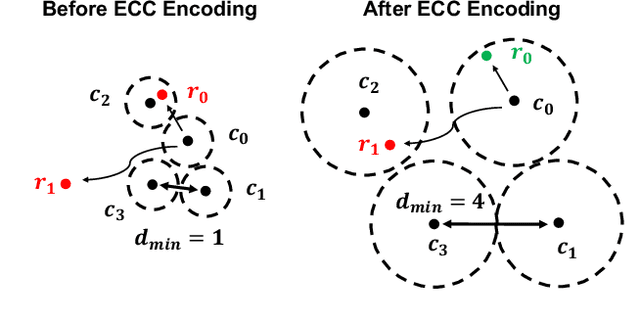
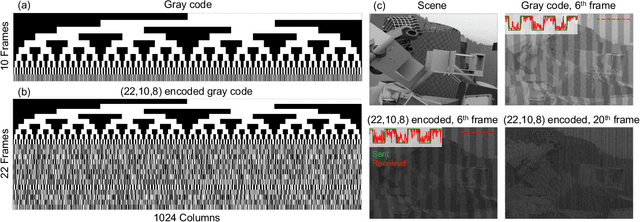
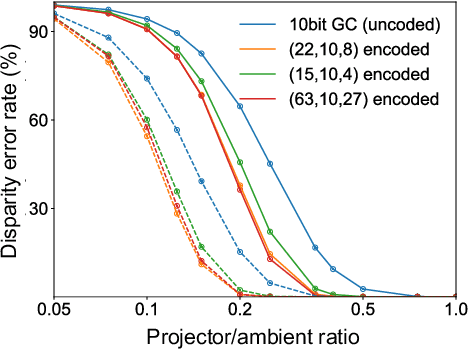
Structured light (SL) systems acquire high-fidelity 3D geometry with active illumination projection. Conventional systems exhibit challenges when working in environments with strong ambient illumination, global illumination and cross-device interference. This paper proposes a general-purposed technique to improve the robustness of SL by projecting redundant optical signals in addition to the native SL patterns. In this way, projected signals become more distinguishable from errors. Thus the geometry information can be more easily recovered using simple signal processing and the ``coding gain" in performance is obtained. We propose three applications using our redundancy codes: (1) Self error-correction for SL imaging under strong ambient light, (2) Error detection for adaptive reconstruction under global illumination, and (3) Interference filtering with device-specific projection sequence encoding, especially for event camera-based SL and light curtain devices. We systematically analyze the design rules and signal processing algorithms in these applications. Corresponding hardware prototypes are built for evaluations on real-world complex scenes. Experimental results on the synthetic and real data demonstrate the significant performance improvements in SL systems with our redundancy codes.
Flexible Sampling for Long-tailed Skin Lesion Classification
Apr 07, 2022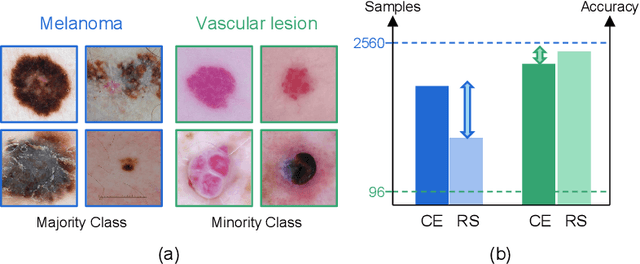
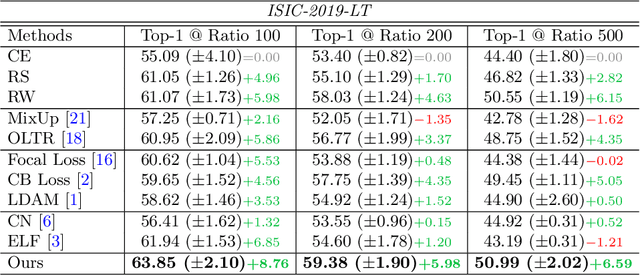
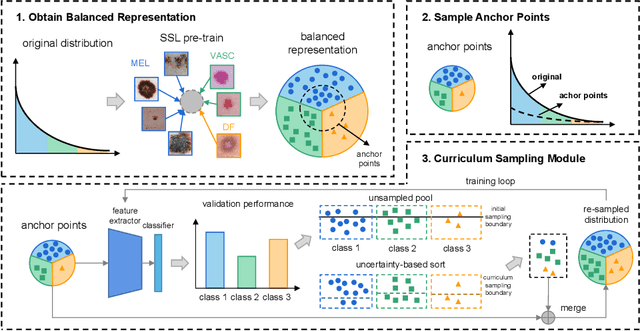
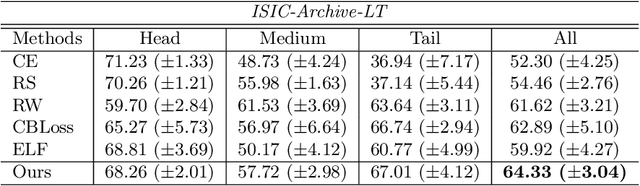
Most of the medical tasks naturally exhibit a long-tailed distribution due to the complex patient-level conditions and the existence of rare diseases. Existing long-tailed learning methods usually treat each class equally to re-balance the long-tailed distribution. However, considering that some challenging classes may present diverse intra-class distributions, re-balancing all classes equally may lead to a significant performance drop. To address this, in this paper, we propose a curriculum learning-based framework called Flexible Sampling for the long-tailed skin lesion classification task. Specifically, we initially sample a subset of training data as anchor points based on the individual class prototypes. Then, these anchor points are used to pre-train an inference model to evaluate the per-class learning difficulty. Finally, we use a curriculum sampling module to dynamically query new samples from the rest training samples with the learning difficulty-aware sampling probability. We evaluated our model against several state-of-the-art methods on the ISIC dataset. The results with two long-tailed settings have demonstrated the superiority of our proposed training strategy, which achieves a new benchmark for long-tailed skin lesion classification.
Exploring Smoothness and Class-Separation for Semi-supervised Medical Image Segmentation
Mar 02, 2022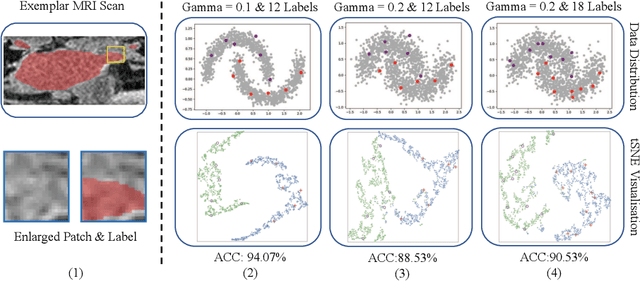
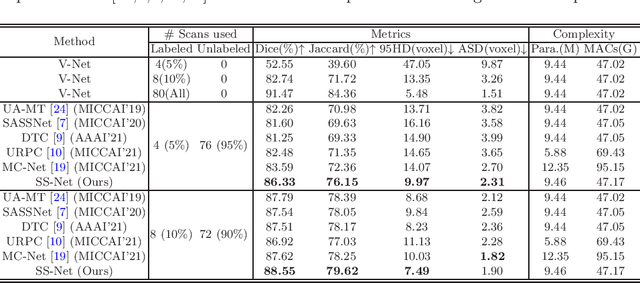
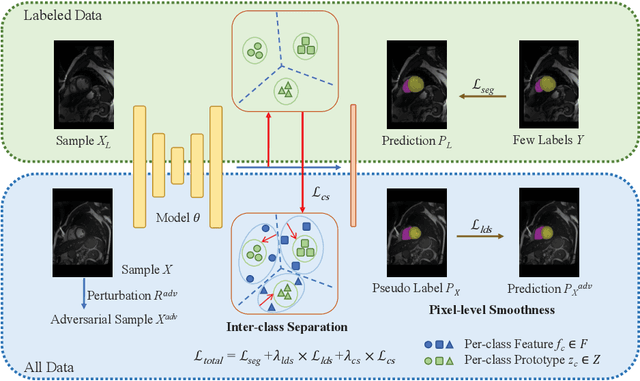
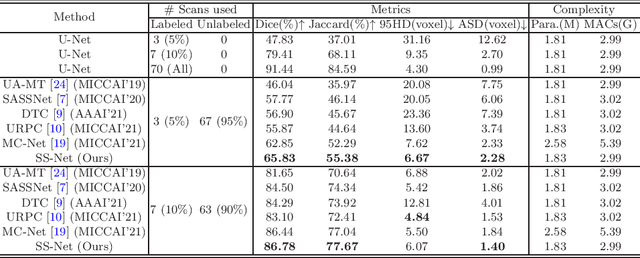
Semi-supervised segmentation remains challenging in medical imaging since the amount of annotated medical data is often limited and there are many blurred pixels near the adhesive edges or low-contrast regions. To address the issues, we advocate to firstly constrain the consistency of samples with and without strong perturbations to apply sufficient smoothness regularization and further encourage the class-level separation to exploit the unlabeled ambiguous pixels for the model training. Particularly, in this paper, we propose the SS-Net for semi-supervised medical image segmentation tasks, via exploring the pixel-level Smoothness and inter-class Separation at the same time. The pixel-level smoothness forces the model to generate invariant results under adversarial perturbations. Meanwhile, the inter-class separation constrains individual class features should approach their corresponding high-quality prototypes, in order to make each class distribution compact and separate different classes. We evaluated our SS-Net against five recent methods on the public LA and ACDC datasets. The experimental results under two semi-supervised settings demonstrate the superiority of our proposed SS-Net, achieving new state-of-the-art (SOTA) performance on both datasets. The codes will be released.
ProposalCLIP: Unsupervised Open-Category Object Proposal Generation via Exploiting CLIP Cues
Jan 18, 2022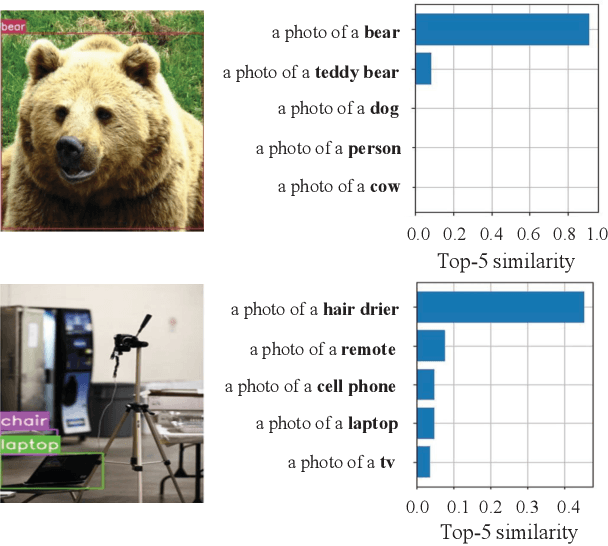
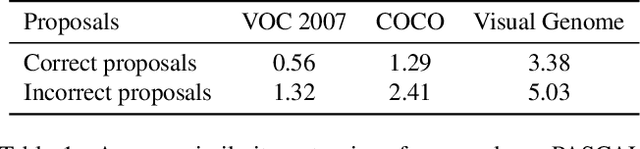

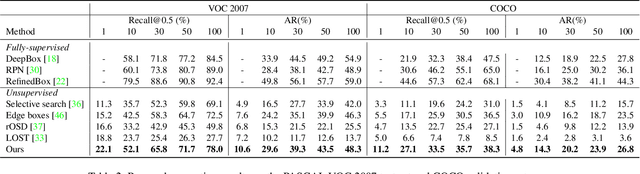
Object proposal generation is an important and fundamental task in computer vision. In this paper, we propose ProposalCLIP, a method towards unsupervised open-category object proposal generation. Unlike previous works which require a large number of bounding box annotations and/or can only generate proposals for limited object categories, our ProposalCLIP is able to predict proposals for a large variety of object categories without annotations, by exploiting CLIP (contrastive language-image pre-training) cues. Firstly, we analyze CLIP for unsupervised open-category proposal generation and design an objectness score based on our empirical analysis on proposal selection. Secondly, a graph-based merging module is proposed to solve the limitations of CLIP cues and merge fragmented proposals. Finally, we present a proposal regression module that extracts pseudo labels based on CLIP cues and trains a lightweight network to further refine proposals. Extensive experiments on PASCAL VOC, COCO and Visual Genome datasets show that our ProposalCLIP can better generate proposals than previous state-of-the-art methods. Our ProposalCLIP also shows benefits for downstream tasks, such as unsupervised object detection.
3D Photo Stylization: Learning to Generate Stylized Novel Views from a Single Image
Dec 04, 2021
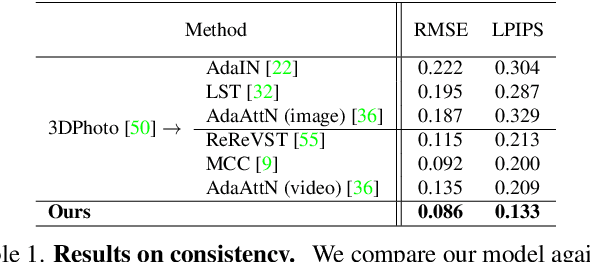

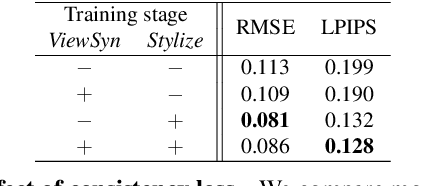
Visual content creation has spurred a soaring interest given its applications in mobile photography and AR / VR. Style transfer and single-image 3D photography as two representative tasks have so far evolved independently. In this paper, we make a connection between the two, and address the challenging task of 3D photo stylization - generating stylized novel views from a single image given an arbitrary style. Our key intuition is that style transfer and view synthesis have to be jointly modeled for this task. To this end, we propose a deep model that learns geometry-aware content features for stylization from a point cloud representation of the scene, resulting in high-quality stylized images that are consistent across views. Further, we introduce a novel training protocol to enable the learning using only 2D images. We demonstrate the superiority of our method via extensive qualitative and quantitative studies, and showcase key applications of our method in light of the growing demand for 3D content creation from 2D image assets.
Enforcing Mutual Consistency of Hard Regions for Semi-supervised Medical Image Segmentation
Sep 21, 2021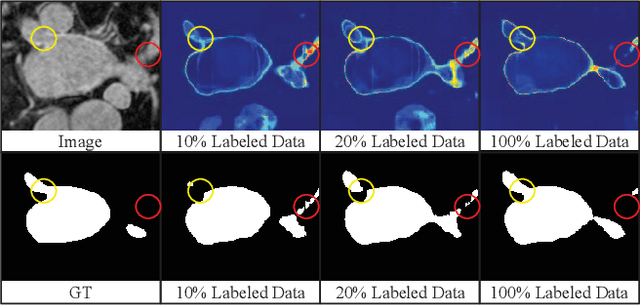
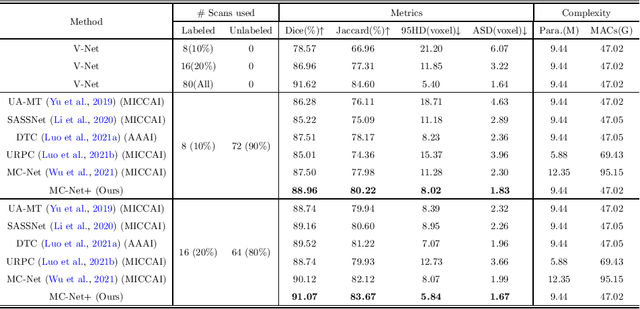
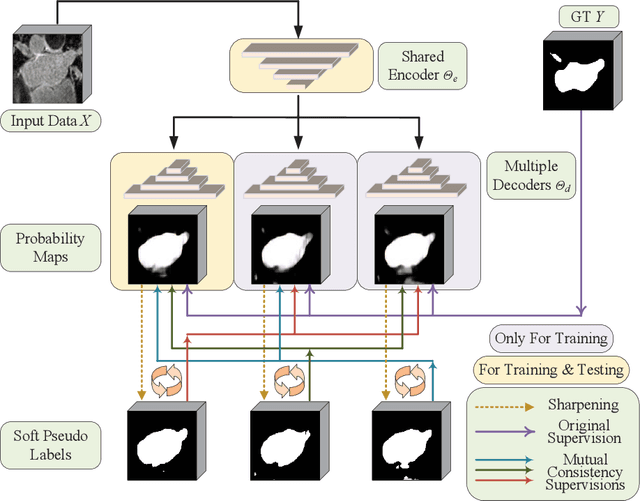
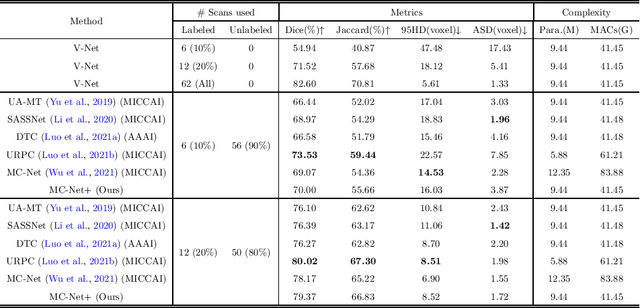
In this paper, we proposed a novel mutual consistency network (MC-Net+) to effectively exploit the unlabeled hard regions for semi-supervised medical image segmentation. The MC-Net+ model is motivated by the observation that deep models trained with limited annotations are prone to output highly uncertain and easily mis-classified predictions in the ambiguous regions (e.g. adhesive edges or thin branches) for the image segmentation task. Leveraging these region-level challenging samples can make the semi-supervised segmentation model training more effective. Therefore, our proposed MC-Net+ model consists of two new designs. First, the model contains one shared encoder and multiple sightly different decoders (i.e. using different up-sampling strategies). The statistical discrepancy of multiple decoders' outputs is computed to denote the model's uncertainty, which indicates the unlabeled hard regions. Second, a new mutual consistency constraint is enforced between one decoder's probability output and other decoders' soft pseudo labels. In this way, we minimize the model's uncertainty during training and force the model to generate invariant and low-entropy results in such challenging areas of unlabeled data, in order to learn a generalized feature representation. We compared the segmentation results of the MC-Net+ with five state-of-the-art semi-supervised approaches on three public medical datasets. Extension experiments with two common semi-supervised settings demonstrate the superior performance of our model over other existing methods, which sets a new state of the art for semi-supervised medical image segmentation.