 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer
Apr 29, 2025Instruction-based image editing enables robust image modification via natural language prompts, yet current methods face a precision-efficiency tradeoff. Fine-tuning methods demand significant computational resources and large datasets, while training-free techniques struggle with instruction comprehension and edit quality. We resolve this dilemma by leveraging large-scale Diffusion Transformer (DiT)' enhanced generation capacity and native contextual awareness. Our solution introduces three contributions: (1) an in-context editing framework for zero-shot instruction compliance using in-context prompting, avoiding structural changes; (2) a LoRA-MoE hybrid tuning strategy that enhances flexibility with efficient adaptation and dynamic expert routing, without extensive retraining; and (3) an early filter inference-time scaling method using vision-language models (VLMs) to select better initial noise early, improving edit quality. Extensive evaluations demonstrate our method's superiority: it outperforms state-of-the-art approaches while requiring only 0.5% training data and 1% trainable parameters compared to conventional baselines. This work establishes a new paradigm that enables high-precision yet efficient instruction-guided editing. Codes and demos can be found in https://river-zhang.github.io/ICEdit-gh-pages/.
Insert Anything: Image Insertion via In-Context Editing in DiT
Apr 21, 2025



This work presents Insert Anything, a unified framework for reference-based image insertion that seamlessly integrates objects from reference images into target scenes under flexible, user-specified control guidance. Instead of training separate models for individual tasks, our approach is trained once on our new AnyInsertion dataset--comprising 120K prompt-image pairs covering diverse tasks such as person, object, and garment insertion--and effortlessly generalizes to a wide range of insertion scenarios. Such a challenging setting requires capturing both identity features and fine-grained details, while allowing versatile local adaptations in style, color, and texture. To this end, we propose to leverage the multimodal attention of the Diffusion Transformer (DiT) to support both mask- and text-guided editing. Furthermore, we introduce an in-context editing mechanism that treats the reference image as contextual information, employing two prompting strategies to harmonize the inserted elements with the target scene while faithfully preserving their distinctive features. Extensive experiments on AnyInsertion, DreamBooth, and VTON-HD benchmarks demonstrate that our method consistently outperforms existing alternatives, underscoring its great potential in real-world applications such as creative content generation, virtual try-on, and scene composition.
TSGS: Improving Gaussian Splatting for Transparent Surface Reconstruction via Normal and De-lighting Priors
Apr 17, 2025Reconstructing transparent surfaces is essential for tasks such as robotic manipulation in labs, yet it poses a significant challenge for 3D reconstruction techniques like 3D Gaussian Splatting (3DGS). These methods often encounter a transparency-depth dilemma, where the pursuit of photorealistic rendering through standard $\alpha$-blending undermines geometric precision, resulting in considerable depth estimation errors for transparent materials. To address this issue, we introduce Transparent Surface Gaussian Splatting (TSGS), a new framework that separates geometry learning from appearance refinement. In the geometry learning stage, TSGS focuses on geometry by using specular-suppressed inputs to accurately represent surfaces. In the second stage, TSGS improves visual fidelity through anisotropic specular modeling, crucially maintaining the established opacity to ensure geometric accuracy. To enhance depth inference, TSGS employs a first-surface depth extraction method. This technique uses a sliding window over $\alpha$-blending weights to pinpoint the most likely surface location and calculates a robust weighted average depth. To evaluate the transparent surface reconstruction task under realistic conditions, we collect a TransLab dataset that includes complex transparent laboratory glassware. Extensive experiments on TransLab show that TSGS achieves accurate geometric reconstruction and realistic rendering of transparent objects simultaneously within the efficient 3DGS framework. Specifically, TSGS significantly surpasses current leading methods, achieving a 37.3% reduction in chamfer distance and an 8.0% improvement in F1 score compared to the top baseline. The code and dataset will be released at https://longxiang-ai.github.io/TSGS/.
C-MTCSD: A Chinese Multi-Turn Conversational Stance Detection Dataset
Apr 14, 2025Stance detection has become an essential tool for analyzing public discussions on social media. Current methods face significant challenges, particularly in Chinese language processing and multi-turn conversational analysis. To address these limitations, we introduce C-MTCSD, the largest Chinese multi-turn conversational stance detection dataset, comprising 24,264 carefully annotated instances from Sina Weibo, which is 4.2 times larger than the only prior Chinese conversational stance detection dataset. Our comprehensive evaluation using both traditional approaches and large language models reveals the complexity of C-MTCSD: even state-of-the-art models achieve only 64.07% F1 score in the challenging zero-shot setting, while performance consistently degrades with increasing conversation depth. Traditional models particularly struggle with implicit stance detection, achieving below 50% F1 score. This work establishes a challenging new benchmark for Chinese stance detection research, highlighting significant opportunities for future improvements.
Learning from Reference Answers: Versatile Language Model Alignment without Binary Human Preference Data
Apr 14, 2025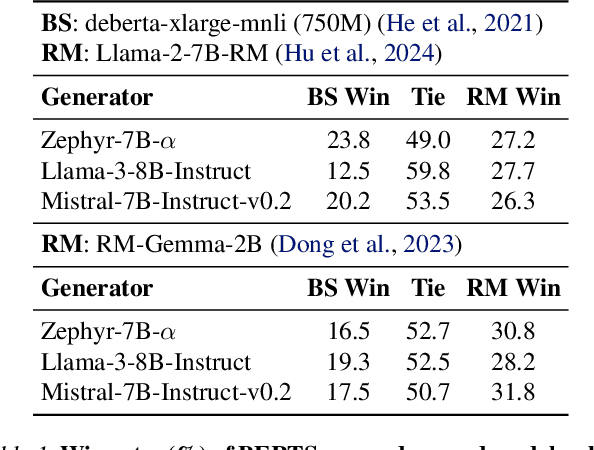

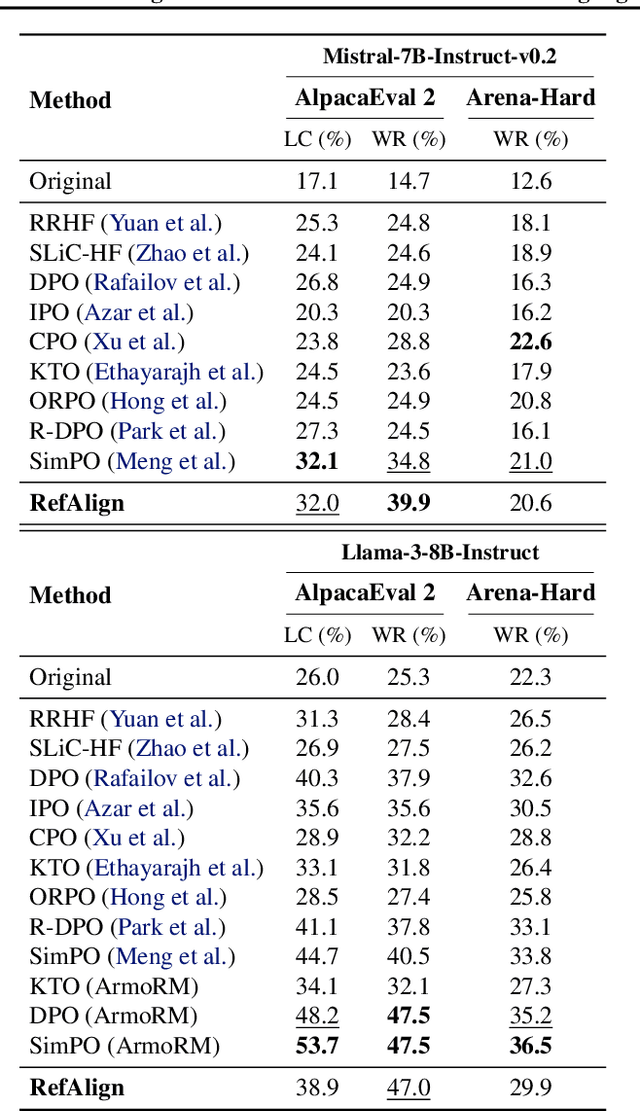
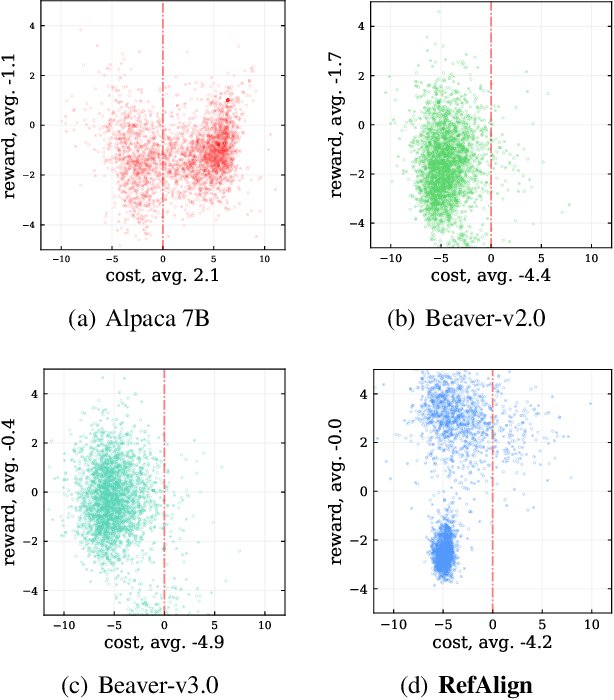
Large language models~(LLMs) are expected to be helpful, harmless, and honest. In various alignment scenarios, such as general human preference, safety, and confidence alignment, binary preference data collection and reward modeling are resource-intensive but necessary for human preference transferring. In this work, we explore using the similarity between sampled generations and high-quality reference answers as an alternative reward function for LLM alignment. Using similarity as a reward circumvents training reward models, and collecting a single reference answer potentially costs less time than constructing binary preference pairs when multiple candidates are available. Specifically, we develop \textit{RefAlign}, a versatile REINFORCE-style alignment algorithm, which is free of reference and reward models. Instead, RefAlign utilizes BERTScore between sampled generations and high-quality reference answers as the surrogate reward. Beyond general human preference optimization, RefAlign can be readily extended to diverse scenarios, such as safety and confidence alignment, by incorporating the similarity reward with task-related objectives. In various scenarios, {RefAlign} demonstrates comparable performance to previous alignment methods while offering high efficiency.
TAPNext: Tracking Any Point (TAP) as Next Token Prediction
Apr 08, 2025Tracking Any Point (TAP) in a video is a challenging computer vision problem with many demonstrated applications in robotics, video editing, and 3D reconstruction. Existing methods for TAP rely heavily on complex tracking-specific inductive biases and heuristics, limiting their generality and potential for scaling. To address these challenges, we present TAPNext, a new approach that casts TAP as sequential masked token decoding. Our model is causal, tracks in a purely online fashion, and removes tracking-specific inductive biases. This enables TAPNext to run with minimal latency, and removes the temporal windowing required by many existing state of art trackers. Despite its simplicity, TAPNext achieves a new state-of-the-art tracking performance among both online and offline trackers. Finally, we present evidence that many widely used tracking heuristics emerge naturally in TAPNext through end-to-end training.
EduPlanner: LLM-Based Multi-Agent Systems for Customized and Intelligent Instructional Design
Apr 07, 2025Large Language Models (LLMs) have significantly advanced smart education in the Artificial General Intelligence (AGI) era. A promising application lies in the automatic generalization of instructional design for curriculum and learning activities, focusing on two key aspects: (1) Customized Generation: generating niche-targeted teaching content based on students' varying learning abilities and states, and (2) Intelligent Optimization: iteratively optimizing content based on feedback from learning effectiveness or test scores. Currently, a single large LLM cannot effectively manage the entire process, posing a challenge for designing intelligent teaching plans. To address these issues, we developed EduPlanner, an LLM-based multi-agent system comprising an evaluator agent, an optimizer agent, and a question analyst, working in adversarial collaboration to generate customized and intelligent instructional design for curriculum and learning activities. Taking mathematics lessons as our example, EduPlanner employs a novel Skill-Tree structure to accurately model the background mathematics knowledge of student groups, personalizing instructional design for curriculum and learning activities according to students' knowledge levels and learning abilities. Additionally, we introduce the CIDDP, an LLM-based five-dimensional evaluation module encompassing clarity, Integrity, Depth, Practicality, and Pertinence, to comprehensively assess mathematics lesson plan quality and bootstrap intelligent optimization. Experiments conducted on the GSM8K and Algebra datasets demonstrate that EduPlanner excels in evaluating and optimizing instructional design for curriculum and learning activities. Ablation studies further validate the significance and effectiveness of each component within the framework. Our code is publicly available at https://github.com/Zc0812/Edu_Planner
Achieving binary weight and activation for LLMs using Post-Training Quantization
Apr 07, 2025Quantizing large language models (LLMs) to 1-bit precision significantly reduces computational costs, but existing quantization techniques suffer from noticeable performance degradation when using weight and activation precisions below 4 bits (W4A4). In this paper, we propose a post-training quantization framework with W(1+1)A(1*4) configuration, where weights are quantized to 1 bit with an additional 1 bit for fine-grain grouping and activations are quantized to 1 bit with a 4-fold increase in the number of channels. For weight quantization, we propose utilizing Hessian-aware fine-grained grouping along with an EM-based quantization scheme. For activation quantization, we decompose INT4-quantized activations into a 4 * INT1 format equivalently and simultaneously smooth the scaling factors based on quantization errors, which further reduces the quantization errors in activations. Our method surpasses state-of-the-art (SOTA) LLM quantization baselines on W2A4 across multiple tasks, pushing the boundaries of existing LLM quantization methods toward fully binarized models.
From Trial to Triumph: Advancing Long Video Understanding via Visual Context Sample Scaling and Self-reward Alignment
Mar 26, 2025Multi-modal Large language models (MLLMs) show remarkable ability in video understanding. Nevertheless, understanding long videos remains challenging as the models can only process a finite number of frames in a single inference, potentially omitting crucial visual information. To address the challenge, we propose generating multiple predictions through visual context sampling, followed by a scoring mechanism to select the final prediction. Specifically, we devise a bin-wise sampling strategy that enables MLLMs to generate diverse answers based on various combinations of keyframes, thereby enriching the visual context. To determine the final prediction from the sampled answers, we employ a self-reward by linearly combining three scores: (1) a frequency score indicating the prevalence of each option, (2) a marginal confidence score reflecting the inter-intra sample certainty of MLLM predictions, and (3) a reasoning score for different question types, including clue-guided answering for global questions and temporal self-refocusing for local questions. The frequency score ensures robustness through majority correctness, the confidence-aligned score reflects prediction certainty, and the typed-reasoning score addresses cases with sparse key visual information using tailored strategies. Experiments show that this approach covers the correct answer for a high percentage of long video questions, on seven datasets show that our method improves the performance of three MLLMs.
ChatStitch: Visualizing Through Structures via Surround-View Unsupervised Deep Image Stitching with Collaborative LLM-Agents
Mar 19, 2025



Collaborative perception has garnered significant attention for its ability to enhance the perception capabilities of individual vehicles through the exchange of information with surrounding vehicle-agents. However, existing collaborative perception systems are limited by inefficiencies in user interaction and the challenge of multi-camera photorealistic visualization. To address these challenges, this paper introduces ChatStitch, the first collaborative perception system capable of unveiling obscured blind spot information through natural language commands integrated with external digital assets. To adeptly handle complex or abstract commands, ChatStitch employs a multi-agent collaborative framework based on Large Language Models. For achieving the most intuitive perception for humans, ChatStitch proposes SV-UDIS, the first surround-view unsupervised deep image stitching method under the non-global-overlapping condition. We conducted extensive experiments on the UDIS-D, MCOV-SLAM open datasets, and our real-world dataset. Specifically, our SV-UDIS method achieves state-of-the-art performance on the UDIS-D dataset for 3, 4, and 5 image stitching tasks, with PSNR improvements of 9%, 17%, and 21%, and SSIM improvements of 8%, 18%, and 26%, respectively.