 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGeo: Unifying Geometric Guidance for Camera-Controllable Image Editing via Video Models
Apr 19, 2026Camera-controllable image editing aims to synthesize novel views of a given scene under varying camera poses while strictly preserving cross-view geometric consistency. However, existing methods typically rely on fragmented geometric guidance, such as only injecting point clouds at the representation level despite models containing multiple levels, and are mainly based on image diffusion models that operate on discrete view mappings. These two limitations jointly lead to geometric drift and structural degradation under continuous camera motion. We observe that while leveraging video models provides continuous viewpoint priors for camera-controllable image editing, they still struggle to form stable geometric understanding if geometric guidance remains fragmented. To systematically address this, we inject unified geometric guidance across three levels that jointly determine the generative output: representation, architecture, and loss function. To this end, we propose UniGeo, a novel camera-controllable editing framework. Specifically, at the representation level, UniGeo incorporates a frame-decoupled geometric reference injection mechanism to provide robust cross-view geometry context. At the architecture level, it introduces geometric anchor attention to align multi-view features. At the loss function level, it proposes a trajectory-endpoint geometric supervision strategy to explicitly reinforce the structural fidelity of target views. Comprehensive experiments across multiple public benchmarks, encompassing both extensive and limited camera motion settings, demonstrate that UniGeo significantly outperforms existing methods in both visual quality and geometric consistency.
ODIN-Based CPU-GPU Architecture with Replay-Driven Simulation and Emulation
Mar 17, 2026Integration of CPU and GPU technologies is a key enabler for modern AI and graphics workloads, combining control-oriented processing with massive parallel compute capability. As systems evolve toward chiplet-based architectures, pre-silicon validation of tightly coupled CPU-GPU subsystems becomes increasingly challenging due to complex validation framework setup, large design scale, high concurrency, non-deterministic execution, and intricate protocol interactions at chiplet boundaries, often resulting in long integration cycles. This paper presents a replay-driven validation methodology developed during the integration of a CPU subsystem, multiple Xe GPU cores, and a configurable Network-on-Chip (NoC) within a foundational SoC building block targeting the ODIN integrated chiplet architecture. By leveraging deterministic waveform capture and replay across both simulation and emulation using a single design database, complex GPU workloads and protocol sequences can be reproduced reliably at the system level. This approach significantly accelerates debug, improves integration confidence, and enables end-to-end system boot and workload execution within a single quarter, demonstrating the effectiveness of replay-based validation as a scalable methodology for chiplet-based systems.
Insert Anything: Image Insertion via In-Context Editing in DiT
Apr 21, 2025



This work presents Insert Anything, a unified framework for reference-based image insertion that seamlessly integrates objects from reference images into target scenes under flexible, user-specified control guidance. Instead of training separate models for individual tasks, our approach is trained once on our new AnyInsertion dataset--comprising 120K prompt-image pairs covering diverse tasks such as person, object, and garment insertion--and effortlessly generalizes to a wide range of insertion scenarios. Such a challenging setting requires capturing both identity features and fine-grained details, while allowing versatile local adaptations in style, color, and texture. To this end, we propose to leverage the multimodal attention of the Diffusion Transformer (DiT) to support both mask- and text-guided editing. Furthermore, we introduce an in-context editing mechanism that treats the reference image as contextual information, employing two prompting strategies to harmonize the inserted elements with the target scene while faithfully preserving their distinctive features. Extensive experiments on AnyInsertion, DreamBooth, and VTON-HD benchmarks demonstrate that our method consistently outperforms existing alternatives, underscoring its great potential in real-world applications such as creative content generation, virtual try-on, and scene composition.
ElaLoRA: Elastic & Learnable Low-Rank Adaptation for Efficient Model Fine-Tuning
Mar 31, 2025Low-Rank Adaptation (LoRA) has become a widely adopted technique for fine-tuning large-scale pre-trained models with minimal parameter updates. However, existing methods rely on fixed ranks or focus solely on either rank pruning or expansion, failing to adapt ranks dynamically to match the importance of different layers during training. In this work, we propose ElaLoRA, an adaptive low-rank adaptation framework that dynamically prunes and expands ranks based on gradient-derived importance scores. To the best of our knowledge, ElaLoRA is the first method that enables both rank pruning and expansion during fine-tuning. Experiments across multiple benchmarks demonstrate that ElaLoRA consistently outperforms existing PEFT methods across different parameter budgets. Furthermore, our studies validate that layers receiving higher rank allocations contribute more significantly to model performance, providing theoretical justification for our adaptive strategy. By introducing a principled and adaptive rank allocation mechanism, ElaLoRA offers a scalable and efficient fine-tuning solution, particularly suited for resource-constrained environments.
Lipschitz Learning for Signal Recovery
Oct 04, 2019We consider the recovery of signals from their observations, which are samples of a transform of the signals rather than the signals themselves, by using machine learning (ML). We will develop a theoretical framework to characterize the signals that can be robustly recovered from their observations by an ML algorithm, and establish a Lipschitz condition on signals and observations that is both necessary and sufficient for the existence of a robust recovery. We will compare the Lipschitz condition with the well-known restricted isometry property of the sparse recovery of compressive sensing, and show the former is more general and less restrictive. For linear observations, our work also suggests an ML method in which the output space is reduced to the lowest possible dimension.
Block-wise Lensless Compressive Camera
Jan 19, 2017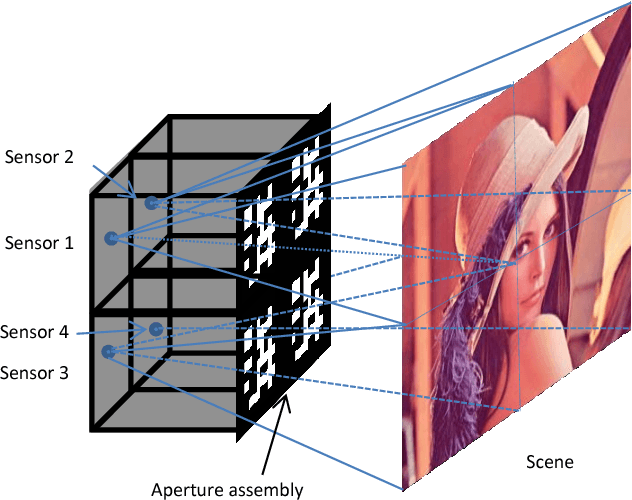
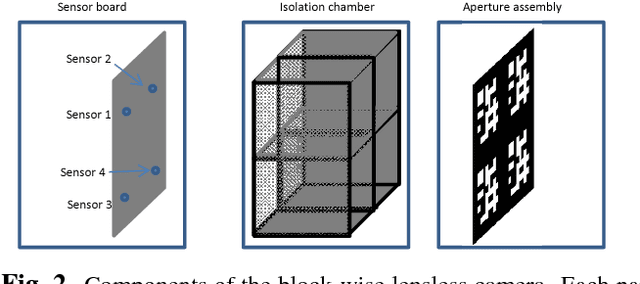
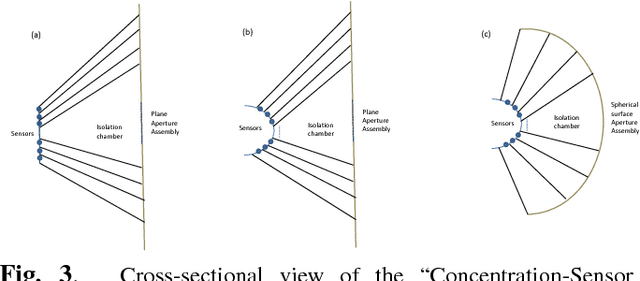
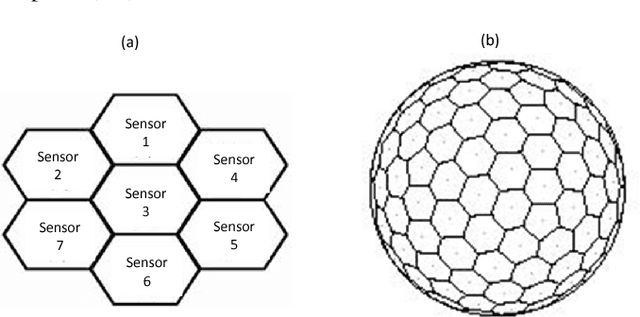
The existing lensless compressive camera ($\text{L}^2\text{C}^2$)~\cite{Huang13ICIP} suffers from low capture rates, resulting in low resolution images when acquired over a short time. In this work, we propose a new regime to mitigate these drawbacks. We replace the global-based compressive sensing used in the existing $\text{L}^2\text{C}^2$ by the local block (patch) based compressive sensing. We use a single sensor for each block, rather than for the entire image, thus forming a multiple but spatially parallel sensor $\text{L}^2\text{C}^2$. This new camera retains the advantages of existing $\text{L}^2\text{C}^2$ while leading to the following additional benefits: 1) Since each block can be very small, {\em e.g.}$~8\times 8$ pixels, we only need to capture $\sim 10$ measurements to achieve reasonable reconstruction. Therefore the capture time can be reduced significantly. 2) The coding patterns used in each block can be the same, therefore the sensing matrix is only of the block size compared to the entire image size in existing $\text{L}^2\text{C}^2$. This saves the memory requirement of the sensing matrix as well as speeds up the reconstruction. 3) Patch based image reconstruction is fast and since real time stitching algorithms exist, we can perform real time reconstruction. 4) These small blocks can be integrated to any desirable number, leading to ultra high resolution images while retaining fast capture rate and fast reconstruction. We develop multiple geometries of this block-wise $\text{L}^2\text{C}^2$ in this paper. We have built prototypes of the proposed block-wise $\text{L}^2\text{C}^2$ and demonstrated excellent results of real data.
Multi-resolution Compressive Sensing Reconstruction
Feb 18, 2016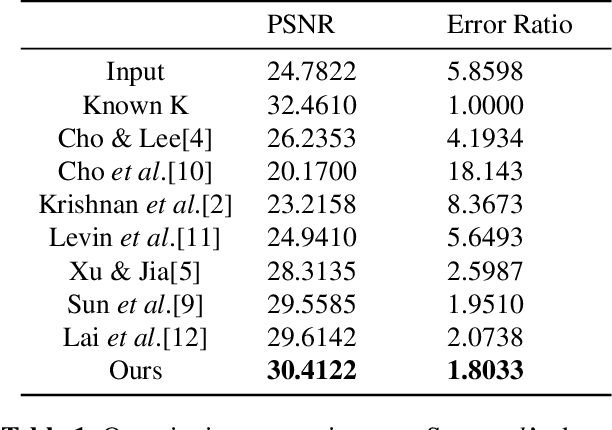
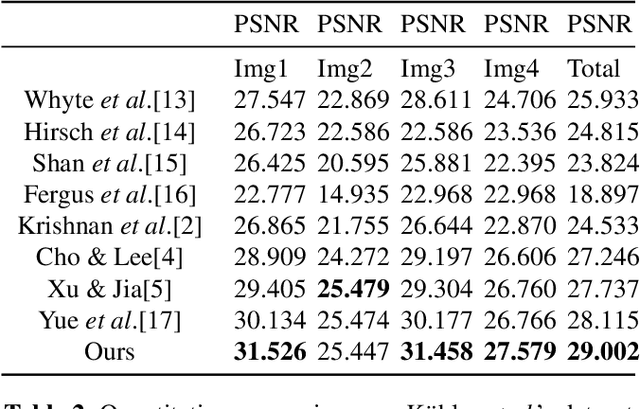
We consider the problem of reconstructing an image from compressive measurements using a multi-resolution grid. In this context, the reconstructed image is divided into multiple regions, each one with a different resolution. This problem arises in situations where the image to reconstruct contains a certain region of interest (RoI) that is more important than the rest. Through a theoretical analysis and simulation experiments we show that the multi-resolution reconstruction provides a higher quality of the RoI compared to the traditional single-resolution approach.
Compressive Sensing via Low-Rank Gaussian Mixture Models
Aug 27, 2015

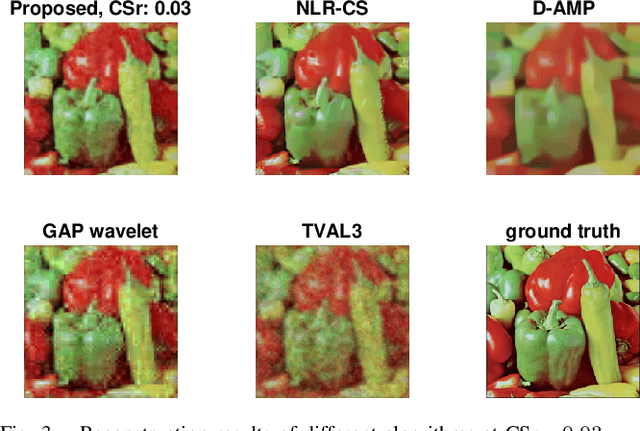

We develop a new compressive sensing (CS) inversion algorithm by utilizing the Gaussian mixture model (GMM). While the compressive sensing is performed globally on the entire image as implemented in our lensless camera, a low-rank GMM is imposed on the local image patches. This low-rank GMM is derived via eigenvalue thresholding of the GMM trained on the projection of the measurement data, thus learned {\em in situ}. The GMM and the projection of the measurement data are updated iteratively during the reconstruction. Our GMM algorithm degrades to the piecewise linear estimator (PLE) if each patch is represented by a single Gaussian model. Inspired by this, a low-rank PLE algorithm is also developed for CS inversion, constituting an additional contribution of this paper. Extensive results on both simulation data and real data captured by the lensless camera demonstrate the efficacy of the proposed algorithm. Furthermore, we compare the CS reconstruction results using our algorithm with the JPEG compression. Simulation results demonstrate that when limited bandwidth is available (a small number of measurements), our algorithm can achieve comparable results as JPEG.
Lensless Compressive Imaging
Aug 14, 2015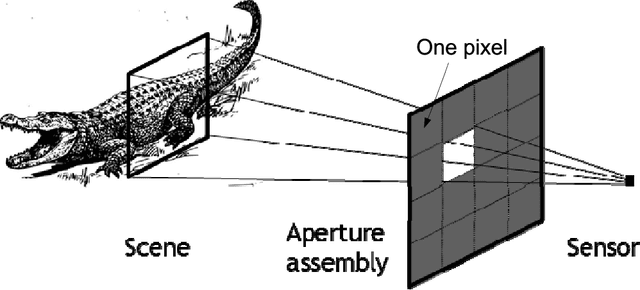



We develop a lensless compressive imaging architecture, which consists of an aperture assembly and a single sensor, without using any lens. An anytime algorithm is proposed to reconstruct images from the compressive measurements; the algorithm produces a sequence of solutions that monotonically converge to the true signal (thus, anytime). The algorithm is developed based on the sparsity of local overlapping patches (in the transformation domain) and state-of-the-art results have been obtained. Experiments on real data demonstrate that encouraging results are obtained by measuring about 10% (of the image pixels) compressive measurements. The reconstruction results of the proposed algorithm are compared with the JPEG compression (based on file sizes) and the reconstructed image quality is close to the JPEG compression, in particular at a high compression rate.
Noise Analysis for Lensless Compressive Imaging
Feb 12, 2014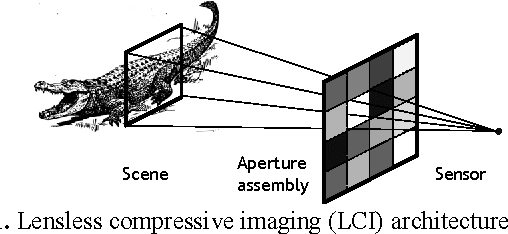
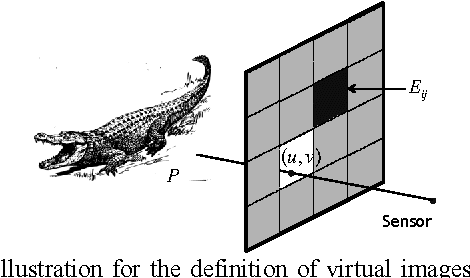
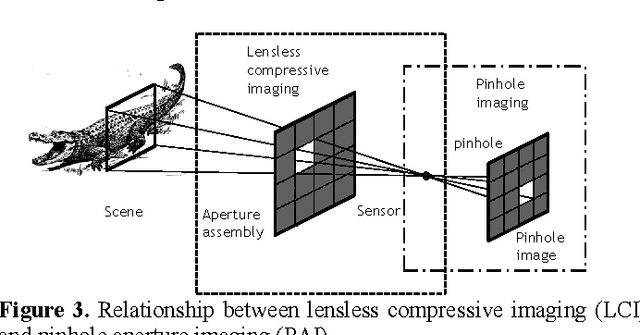
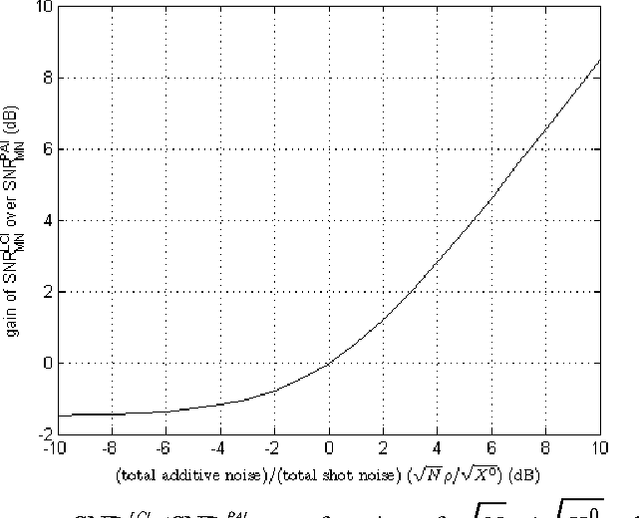
We analyze the signal to noise ratio (SNR) in a recently proposed lensless compressive imaging architecture. The architecture consists of a sensor of a single detector element and an aperture assembly of an array of aperture elements, each of which has a programmable transmittance. This lensless compressive imaging architecture can be used in conjunction with compressive sensing to capture images in a compressed form of compressive measurements. In this paper, we perform noise analysis of this lensless compressive imaging architecture and compare it with pinhole aperture imaging and lens aperture imaging. We will show that the SNR in the lensless compressive imaging is independent of the image resolution, while that in either pinhole aperture imaging or lens aperture imaging decreases as the image resolution increases. Consequently, the SNR in the lensless compressive imaging can be much higher if the image resolution is large enough.