 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIE++: Towards End-to-End Information Extraction from Visually Rich Documents
Jul 14, 2022
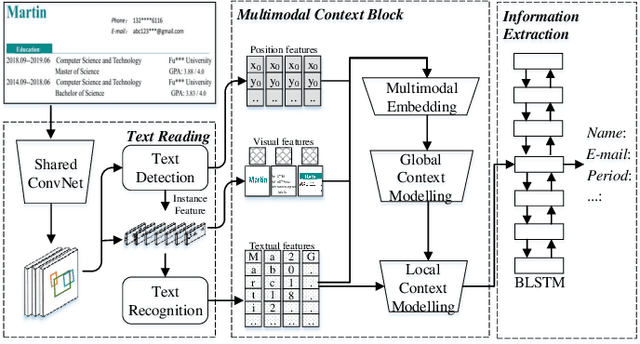
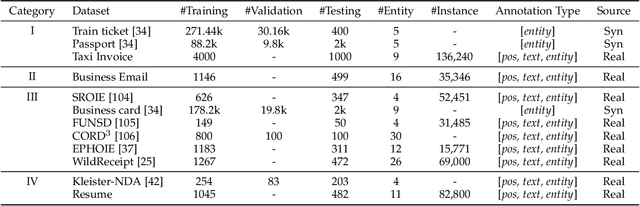
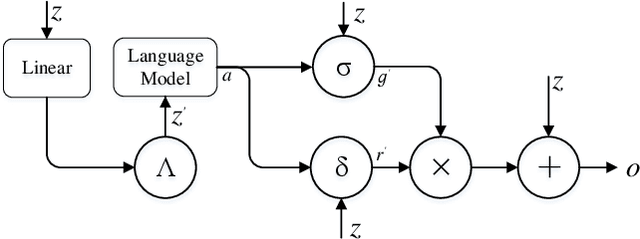
Recently, automatically extracting information from visually rich documents (e.g., tickets and resumes) has become a hot and vital research topic due to its widespread commercial value. Most existing methods divide this task into two subparts: the text reading part for obtaining the plain text from the original document images and the information extraction part for extracting key contents. These methods mainly focus on improving the second, while neglecting that the two parts are highly correlated. This paper proposes a unified end-to-end information extraction framework from visually rich documents, where text reading and information extraction can reinforce each other via a well-designed multi-modal context block. Specifically, the text reading part provides multi-modal features like visual, textual and layout features. The multi-modal context block is developed to fuse the generated multi-modal features and even the prior knowledge from the pre-trained language model for better semantic representation. The information extraction part is responsible for generating key contents with the fused context features. The framework can be trained in an end-to-end trainable manner, achieving global optimization. What is more, we define and group visually rich documents into four categories across two dimensions, the layout and text type. For each document category, we provide or recommend the corresponding benchmarks, experimental settings and strong baselines for remedying the problem that this research area lacks the uniform evaluation standard. Extensive experiments on four kinds of benchmarks (from fixed layout to variable layout, from full-structured text to semi-unstructured text) are reported, demonstrating the proposed method's effectiveness. Data, source code and models are available.
DavarOCR: A Toolbox for OCR and Multi-Modal Document Understanding
Jul 14, 2022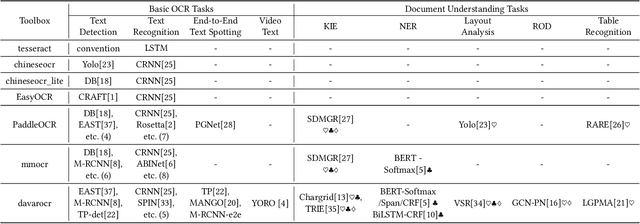


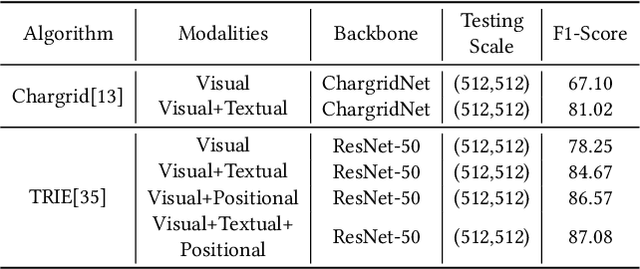
This paper presents DavarOCR, an open-source toolbox for OCR and document understanding tasks. DavarOCR currently implements 19 advanced algorithms, covering 9 different task forms. DavarOCR provides detailed usage instructions and the trained models for each algorithm. Compared with the previous opensource OCR toolbox, DavarOCR has relatively more complete support for the sub-tasks of the cutting-edge technology of document understanding. In order to promote the development and application of OCR technology in academia and industry, we pay more attention to the use of modules that different sub-domains of technology can share. DavarOCR is publicly released at https://github.com/hikopensource/Davar-Lab-OCR.
PMAL: Open Set Recognition via Robust Prototype Mining
Mar 16, 2022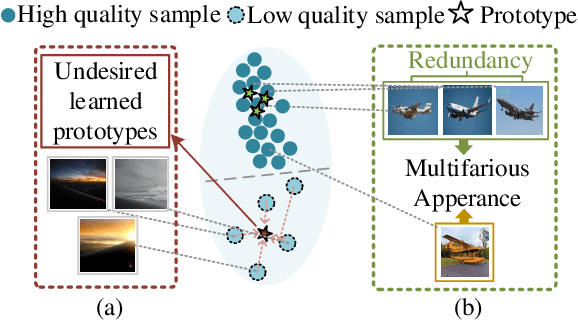
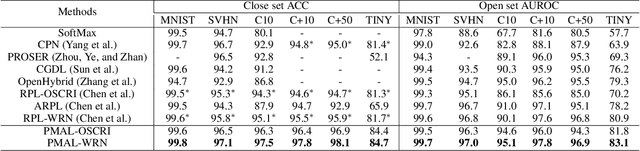
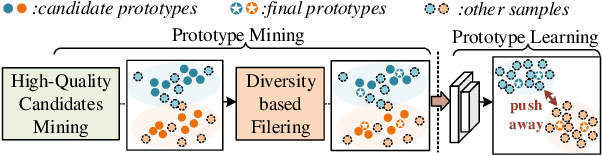
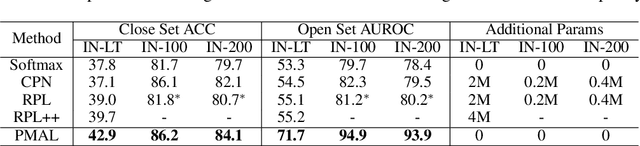
Open Set Recognition (OSR) has been an emerging topic. Besides recognizing predefined classes, the system needs to reject the unknowns. Prototype learning is a potential manner to handle the problem, as its ability to improve intra-class compactness of representations is much needed in discrimination between the known and the unknowns. In this work, we propose a novel Prototype Mining And Learning (PMAL) framework. It has a prototype mining mechanism before the phase of optimizing embedding space, explicitly considering two crucial properties, namely high-quality and diversity of the prototype set. Concretely, a set of high-quality candidates are firstly extracted from training samples based on data uncertainty learning, avoiding the interference from unexpected noise. Considering the multifarious appearance of objects even in a single category, a diversity-based strategy for prototype set filtering is proposed. Accordingly, the embedding space can be better optimized to discriminate therein the predefined classes and between known and unknowns. Extensive experiments verify the two good characteristics (i.e., high-quality and diversity) embraced in prototype mining, and show the remarkable performance of the proposed framework compared to state-of-the-arts.
Technical Report for ICCV 2021 Challenge SSLAD-Track3B: Transformers Are Better Continual Learners
Jan 13, 2022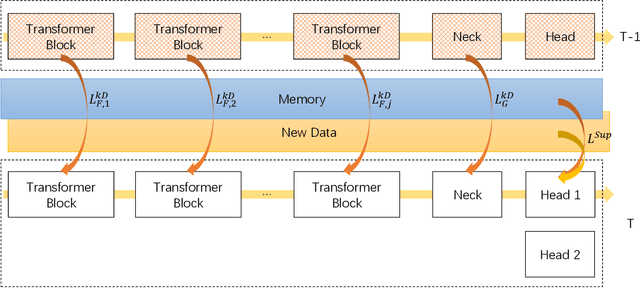
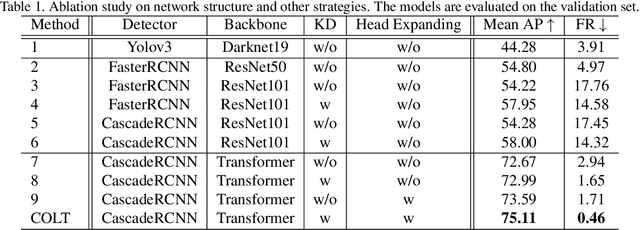
In the SSLAD-Track 3B challenge on continual learning, we propose the method of COntinual Learning with Transformer (COLT). We find that transformers suffer less from catastrophic forgetting compared to convolutional neural network. The major principle of our method is to equip the transformer based feature extractor with old knowledge distillation and head expanding strategies to compete catastrophic forgetting. In this report, we first introduce the overall framework of continual learning for object detection. Then, we analyse the key elements' effect on withstanding catastrophic forgetting in our solution. Our method achieves 70.78 mAP on the SSLAD-Track 3B challenge test set.
A Strong Baseline for Semi-Supervised Incremental Few-Shot Learning
Nov 04, 2021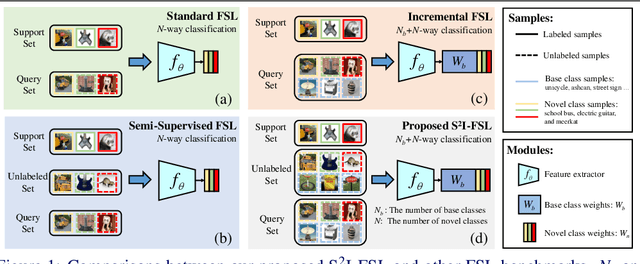
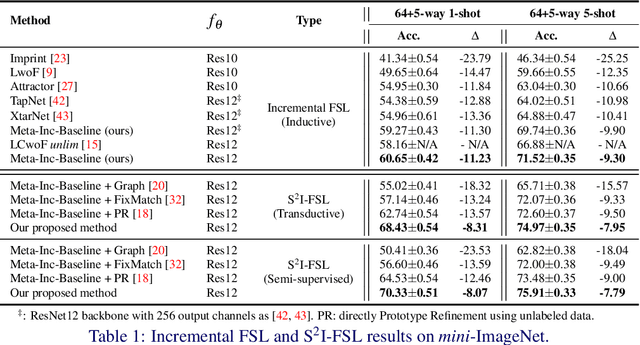
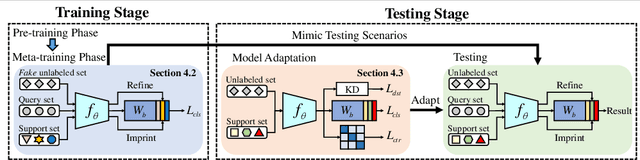
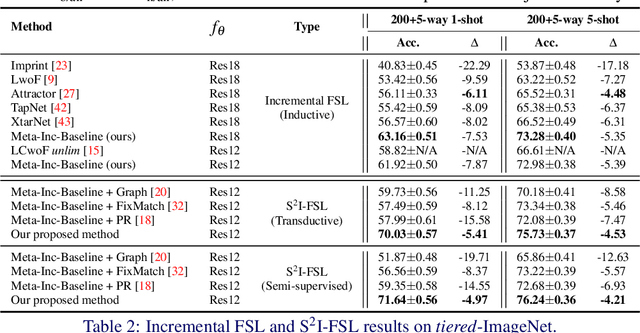
Few-shot learning (FSL) aims to learn models that generalize to novel classes with limited training samples. Recent works advance FSL towards a scenario where unlabeled examples are also available and propose semi-supervised FSL methods. Another line of methods also cares about the performance of base classes in addition to the novel ones and thus establishes the incremental FSL scenario. In this paper, we generalize the above two under a more realistic yet complex setting, named by Semi-Supervised Incremental Few-Shot Learning (S2 I-FSL). To tackle the task, we propose a novel paradigm containing two parts: (1) a well-designed meta-training algorithm for mitigating ambiguity between base and novel classes caused by unreliable pseudo labels and (2) a model adaptation mechanism to learn discriminative features for novel classes while preserving base knowledge using few labeled and all the unlabeled data. Extensive experiments on standard FSL, semi-supervised FSL, incremental FSL, and the firstly built S2 I-FSL benchmarks demonstrate the effectiveness of our proposed method.
Reciprocal Feature Learning via Explicit and Implicit Tasks in Scene Text Recognition
May 13, 2021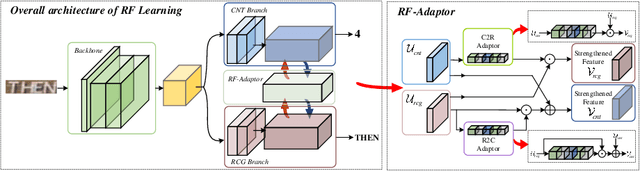

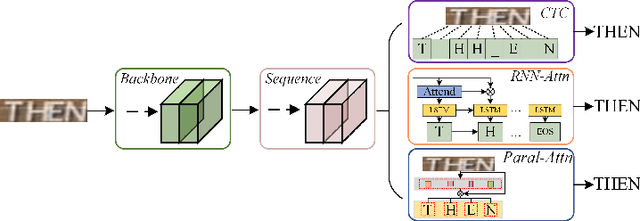

Text recognition is a popular topic for its broad applications. In this work, we excavate the implicit task, character counting within the traditional text recognition, without additional labor annotation cost. The implicit task plays as an auxiliary branch for complementing the sequential recognition. We design a two-branch reciprocal feature learning framework in order to adequately utilize the features from both the tasks. Through exploiting the complementary effect between explicit and implicit tasks, the feature is reliably enhanced. Extensive experiments on 7 benchmarks show the advantages of the proposed methods in both text recognition and the new-built character counting tasks. In addition, it is convenient yet effective to equip with variable networks and tasks. We offer abundant ablation studies, generalizing experiments with deeper understanding on the tasks. Code is available.
LGPMA: Complicated Table Structure Recognition with Local and Global Pyramid Mask Alignment
May 13, 2021
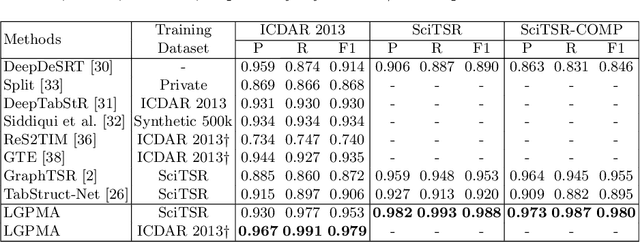
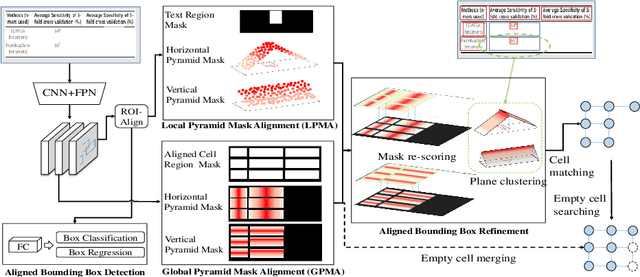
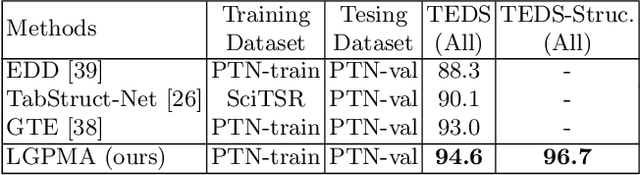
Table structure recognition is a challenging task due to the various structures and complicated cell spanning relations. Previous methods handled the problem starting from elements in different granularities (rows/columns, text regions), which somehow fell into the issues like lossy heuristic rules or neglect of empty cell division. Based on table structure characteristics, we find that obtaining the aligned bounding boxes of text region can effectively maintain the entire relevant range of different cells. However, the aligned bounding boxes are hard to be accurately predicted due to the visual ambiguities. In this paper, we aim to obtain more reliable aligned bounding boxes by fully utilizing the visual information from both text regions in proposed local features and cell relations in global features. Specifically, we propose the framework of Local and Global Pyramid Mask Alignment, which adopts the soft pyramid mask learning mechanism in both the local and global feature maps. It allows the predicted boundaries of bounding boxes to break through the limitation of original proposals. A pyramid mask re-scoring module is then integrated to compromise the local and global information and refine the predicted boundaries. Finally, we propose a robust table structure recovery pipeline to obtain the final structure, in which we also effectively solve the problems of empty cells locating and division. Experimental results show that the proposed method achieves competitive and even new state-of-the-art performance on several public benchmarks.
VSR: A Unified Framework for Document Layout Analysis combining Vision, Semantics and Relations
May 13, 2021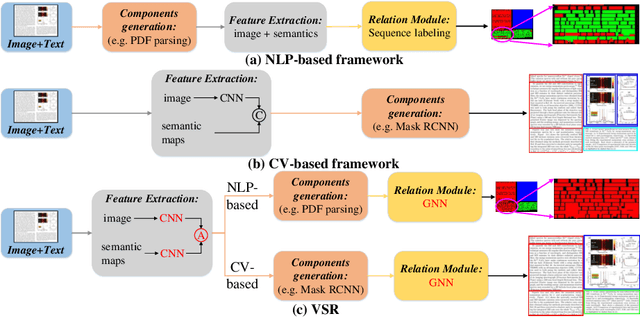
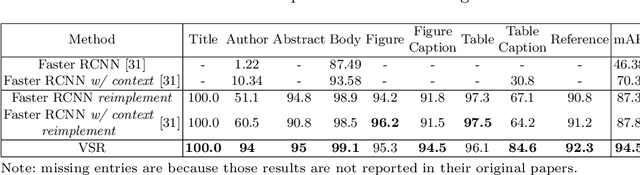
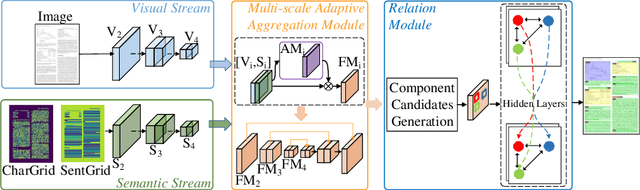
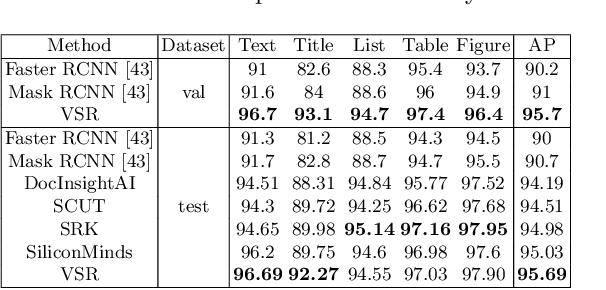
Document layout analysis is crucial for understanding document structures. On this task, vision and semantics of documents, and relations between layout components contribute to the understanding process. Though many works have been proposed to exploit the above information, they show unsatisfactory results. NLP-based methods model layout analysis as a sequence labeling task and show insufficient capabilities in layout modeling. CV-based methods model layout analysis as a detection or segmentation task, but bear limitations of inefficient modality fusion and lack of relation modeling between layout components. To address the above limitations, we propose a unified framework VSR for document layout analysis, combining vision, semantics and relations. VSR supports both NLP-based and CV-based methods. Specifically, we first introduce vision through document image and semantics through text embedding maps. Then, modality-specific visual and semantic features are extracted using a two-stream network, which are adaptively fused to make full use of complementary information. Finally, given component candidates, a relation module based on graph neural network is incorported to model relations between components and output final results. On three popular benchmarks, VSR outperforms previous models by large margins. Code will be released soon.
1st Place Solution to ICDAR 2021 RRC-ICTEXT End-to-end Text Spotting and Aesthetic Assessment on Integrated Circuit
Apr 08, 2021


This paper presents our proposed methods to ICDAR 2021 Robust Reading Challenge - Integrated Circuit Text Spotting and Aesthetic Assessment (ICDAR RRC-ICTEXT 2021). For the text spotting task, we detect the characters on integrated circuit and classify them based on yolov5 detection model. We balance the lowercase and non-lowercase by using SynthText, generated data and data sampler. We adopt semi-supervised algorithm and distillation to furtherly improve the model's accuracy. For the aesthetic assessment task, we add a classification branch of 3 classes to differentiate the aesthetic classes of each character. Finally, we make model deployment to accelerate inference speed and reduce memory consumption based on NVIDIA Tensorrt. Our methods achieve 59.1 mAP on task 3.1 with 31 FPS and 306M memory (rank 1), 78.7\% F2 score on task 3.2 with 30 FPS and 306M memory (rank 1).
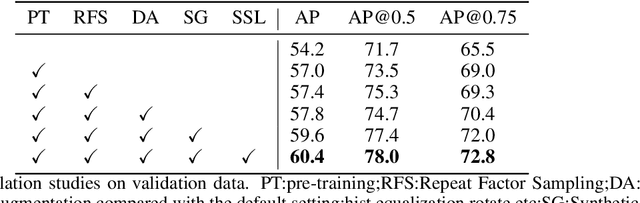
MANGO: A Mask Attention Guided One-Stage Scene Text Spotter
Dec 08, 2020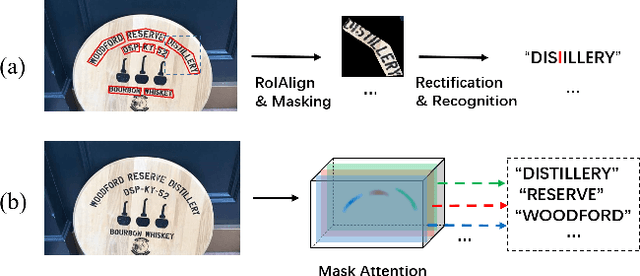
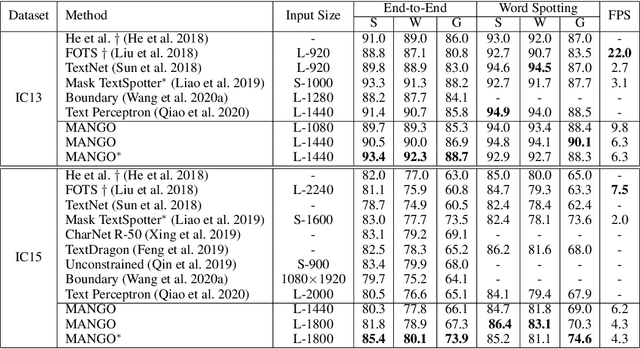
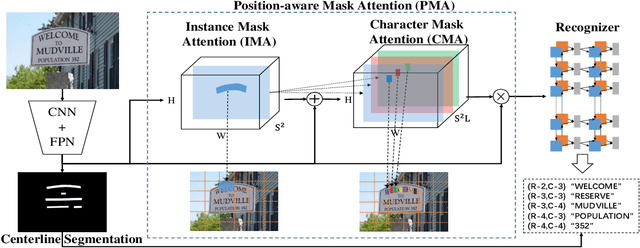
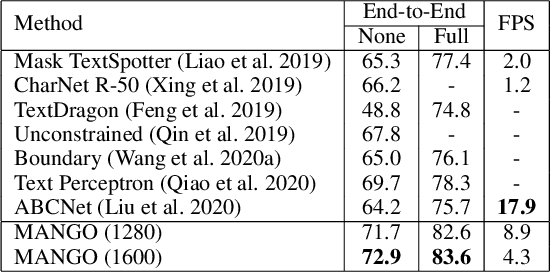
Recently end-to-end scene text spotting has become a popular research topic due to its advantages of global optimization and high maintainability in real applications. Most methods attempt to develop various region of interest (RoI) operations to concatenate the detection part and the sequence recognition part into a two-stage text spotting framework. However, in such framework, the recognition part is highly sensitive to the detected results (\emph{e.g.}, the compactness of text contours). To address this problem, in this paper, we propose a novel Mask AttentioN Guided One-stage text spotting framework named MANGO, in which character sequences can be directly recognized without RoI operation. Concretely, a position-aware mask attention module is developed to generate attention weights on each text instance and its characters. It allows different text instances in an image to be allocated on different feature map channels which are further grouped as a batch of instance features. Finally, a lightweight sequence decoder is applied to generate the character sequences. It is worth noting that MANGO inherently adapts to arbitrary-shaped text spotting and can be trained end-to-end with only coarse position information (\emph{e.g.}, rectangular bounding box) and text annotations. Experimental results show that the proposed method achieves competitive and even new state-of-the-art performance on both regular and irregular text spotting benchmarks, i.e., ICDAR 2013, ICDAR 2015, Total-Text, and SCUT-CTW1500.