 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Entropy Minimization for Semi-supervised Node Classification
May 31, 2023



Node classifiers are required to comprehensively reduce prediction errors, training resources, and inference latency in the industry. However, most graph neural networks (GNN) concentrate only on one or two of them. The compromised aspects thus are the shortest boards on the bucket, hindering their practical deployments for industrial-level tasks. This work proposes a novel semi-supervised learning method termed Graph Entropy Minimization (GEM) to resolve the three issues simultaneously. GEM benefits its one-hop aggregation from massive uncategorized nodes, making its prediction accuracy comparable to GNNs with two or more hops message passing. It can be decomposed to support stochastic training with mini-batches of independent edge samples, achieving extremely fast sampling and space-saving training. While its one-hop aggregation is faster in inference than deep GNNs, GEM can be further accelerated to an extreme by deriving a non-hop classifier via online knowledge distillation. Thus, GEM can be a handy choice for latency-restricted and error-sensitive services running on resource-constraint hardware. Code is available at https://github.com/cf020031308/GEM.
Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models
Apr 23, 2023Large language models (LLMs) can achieve highly effective performance on various reasoning tasks by incorporating step-by-step chain-of-thought (CoT) prompting as demonstrations. However, the reasoning chains of demonstrations generated by LLMs are prone to errors, which can subsequently lead to incorrect reasoning during inference. Furthermore, inappropriate exemplars (overly simplistic or complex), can affect overall performance among varying levels of difficulty. We introduce Iter-CoT (Iterative bootstrapping in Chain-of-Thoughts Prompting), an iterative bootstrapping approach for selecting exemplars and generating reasoning chains. By utilizing iterative bootstrapping, our approach enables LLMs to autonomously rectify errors, resulting in more precise and comprehensive reasoning chains. Simultaneously, our approach selects challenging yet answerable questions accompanied by reasoning chains as exemplars with a moderate level of difficulty, which enhances the LLMs' generalizability across varying levels of difficulty. Experimental results indicate that Iter-CoT exhibits superiority, achieving competitive performance across three distinct reasoning tasks on eleven datasets.
Fast Random Approximation of Multi-channel Room Impulse Response
Apr 17, 2023



Modern neural-network-based speech processing systems are typically required to be robust against reverberation, and the training of such systems thus needs a large amount of reverberant data. During the training of the systems, on-the-fly simulation pipeline is nowadays preferred as it allows the model to train on infinite number of data samples without pre-generating and saving them on harddisk. An RIR simulation method thus needs to not only generate more realistic artificial room impulse response (RIR) filters, but also generate them in a fast way to accelerate the training process. Existing RIR simulation tools have proven effective in a wide range of speech processing tasks and neural network architectures, but their usage in on-the-fly simulation pipeline remains questionable due to their computational complexity or the quality of the generated RIR filters. In this paper, we propose FRAM-RIR, a fast random approximation method of the widely-used image-source method (ISM), to efficiently generate realistic multi-channel RIR filters. FRAM-RIR bypasses the explicit calculation of sound propagation paths in ISM-based algorithms by randomly sampling the location and number of reflections of each virtual sound source based on several heuristic assumptions, while still maintains accurate direction-of-arrival (DOA) information of all sound sources. Visualization of oracle beampatterns and directional features shows that FRAM-RIR can generate more realistic RIR filters than existing widely-used ISM-based tools, and experiment results on multi-channel noisy speech separation and dereverberation tasks with a wide range of neural network architectures show that models trained with FRAM-RIR can also achieve on par or better performance on real RIRs compared to other RIR simulation tools with a significantly accelerated training procedure. A Python implementation of FRAM-RIR is released.
Quantitative phase imaging (QPI) through random diffusers using a diffractive optical network
Jan 19, 2023



Quantitative phase imaging (QPI) is a label-free computational imaging technique used in various fields, including biology and medical research. Modern QPI systems typically rely on digital processing using iterative algorithms for phase retrieval and image reconstruction. Here, we report a diffractive optical network trained to convert the phase information of input objects positioned behind random diffusers into intensity variations at the output plane, all-optically performing phase recovery and quantitative imaging of phase objects completely hidden by unknown, random phase diffusers. This QPI diffractive network is composed of successive diffractive layers, axially spanning in total ~70 wavelengths; unlike existing digital image reconstruction and phase retrieval methods, it forms an all-optical processor that does not require external power beyond the illumination beam to complete its QPI reconstruction at the speed of light propagation. This all-optical diffractive processor can provide a low-power, high frame rate and compact alternative for quantitative imaging of phase objects through random, unknown diffusers and can operate at different parts of the electromagnetic spectrum for various applications in biomedical imaging and sensing. The presented QPI diffractive designs can be integrated onto the active area of standard CCD/CMOS-based image sensors to convert an existing optical microscope into a diffractive QPI microscope, performing phase recovery and image reconstruction on a chip through light diffraction within passive structured layers.
High Fidelity Speech Enhancement with Band-split RNN
Dec 01, 2022This report presents the development of our speech enhancement system, which includes the use of a recently proposed music separation model, the band-split recurrent neural network (BSRNN), and a MetricGAN-based training objective to improve non-differentiable quality metrics such as perceptual evaluation of speech quality (PESQ) score. Experiment conducted on Interspeech 2021 DNS challenge shows that our BSRNN system outperforms various top-ranking benchmark systems in previous deep noise suppression (DNS) challenges and achieves state-of-the-art (SOTA) result on the DNS-2020 non-blind test set in both offline and online scenarios.
Unifying Label-inputted Graph Neural Networks with Deep Equilibrium Models
Nov 19, 2022



For node classification, Graph Neural Networks (GNN) assign predefined labels to graph nodes according to node features propagated along the graph structure. Apart from the traditional end-to-end manner inherited from deep learning, many subsequent works input assigned labels into GNNs to improve their classification performance. Such label-inputted GNNs (LGNN) combine the advantages of learnable feature propagation and long-range label propagation, producing state-of-the-art performance on various benchmarks. However, the theoretical foundations of LGNNs are not well-established, and the combination is with seam because the long-range propagation is memory-consuming for optimization. To this end, this work interprets LGNNs with the theory of Implicit GNN (IGNN), which outputs a fixed state point of iterating its network infinite times and optimizes the infinite-range propagation with constant memory consumption. Besides, previous contributions to LGNNs inspire us to overcome the heavy computation in training IGNN by iterating the network only once but starting from historical states, which are randomly masked in forward-pass to implicitly guarantee the existence and uniqueness of the fixed point. Our improvements to IGNNs are network agnostic: for the first time, they are extended with complex networks and applied to large-scale graphs. Experiments on two synthetic and six real-world datasets verify the advantages of our method in terms of long-range dependencies capturing, label transitions modelling, accuracy, scalability, efficiency, and well-posedness.
3D Matting: A Benchmark Study on Soft Segmentation Method for Pulmonary Nodules Applied in Computed Tomography
Oct 11, 2022
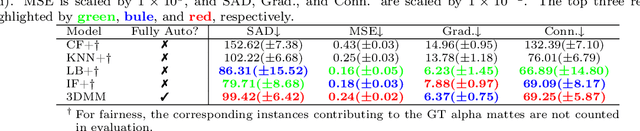
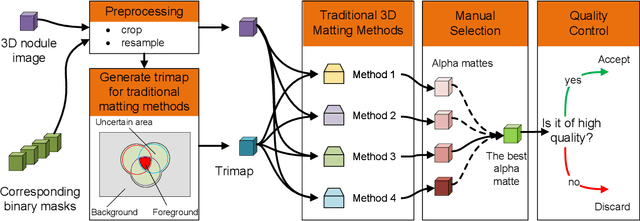
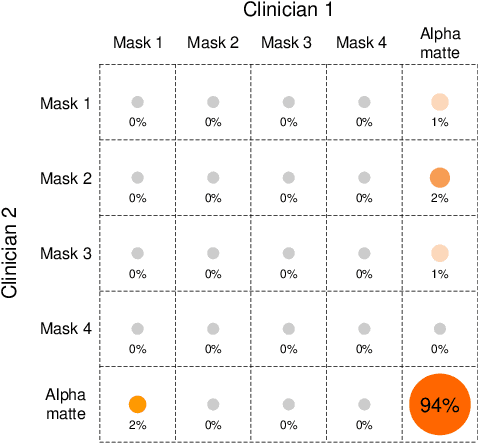
Usually, lesions are not isolated but are associated with the surrounding tissues. For example, the growth of a tumour can depend on or infiltrate into the surrounding tissues. Due to the pathological nature of the lesions, it is challenging to distinguish their boundaries in medical imaging. However, these uncertain regions may contain diagnostic information. Therefore, the simple binarization of lesions by traditional binary segmentation can result in the loss of diagnostic information. In this work, we introduce the image matting into the 3D scenes and use the alpha matte, i.e., a soft mask, to describe lesions in a 3D medical image. The traditional soft mask acted as a training trick to compensate for the easily mislabelled or under-labelled ambiguous regions. In contrast, 3D matting uses soft segmentation to characterize the uncertain regions more finely, which means that it retains more structural information for subsequent diagnosis and treatment. The current study of image matting methods in 3D is limited. To address this issue, we conduct a comprehensive study of 3D matting, including both traditional and deep-learning-based methods. We adapt four state-of-the-art 2D image matting algorithms to 3D scenes and further customize the methods for CT images to calibrate the alpha matte with the radiodensity. Moreover, we propose the first end-to-end deep 3D matting network and implement a solid 3D medical image matting benchmark. Its efficient counterparts are also proposed to achieve a good performance-computation balance. Furthermore, there is no high-quality annotated dataset related to 3D matting, slowing down the development of data-driven deep-learning-based methods. To address this issue, we construct the first 3D medical matting dataset. The validity of the dataset was verified through clinicians' assessments and downstream experiments.
Music Source Separation with Band-split RNN
Sep 30, 2022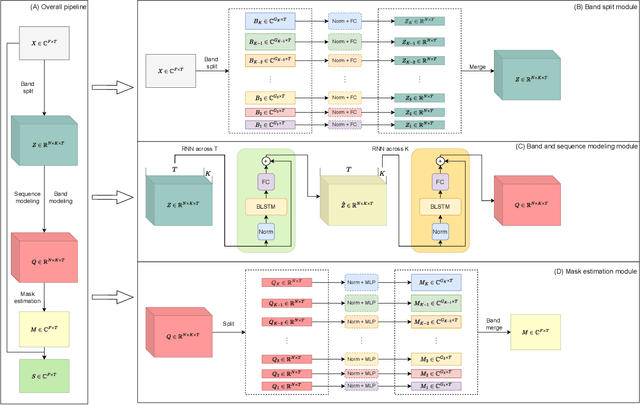
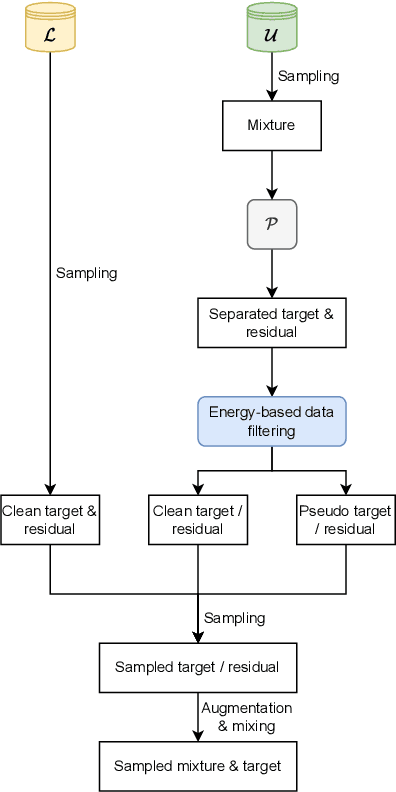

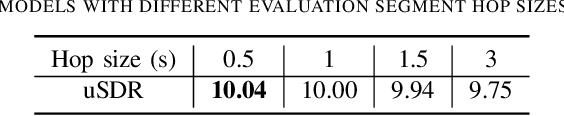
The performance of music source separation (MSS) models has been greatly improved in recent years thanks to the development of novel neural network architectures and training pipelines. However, recent model designs for MSS were mainly motivated by other audio processing tasks or other research fields, while the intrinsic characteristics and patterns of the music signals were not fully discovered. In this paper, we propose band-split RNN (BSRNN), a frequency-domain model that explictly splits the spectrogram of the mixture into subbands and perform interleaved band-level and sequence-level modeling. The choices of the bandwidths of the subbands can be determined by a priori knowledge or expert knowledge on the characteristics of the target source in order to optimize the performance on a certain type of target musical instrument. To better make use of unlabeled data, we also describe a semi-supervised model finetuning pipeline that can further improve the performance of the model. Experiment results show that BSRNN trained only on MUSDB18-HQ dataset significantly outperforms several top-ranking models in Music Demixing (MDX) Challenge 2021, and the semi-supervised finetuning stage further improves the performance on all four instrument tracks.
Improving Choral Music Separation through Expressive Synthesized Data from Sampled Instruments
Sep 07, 2022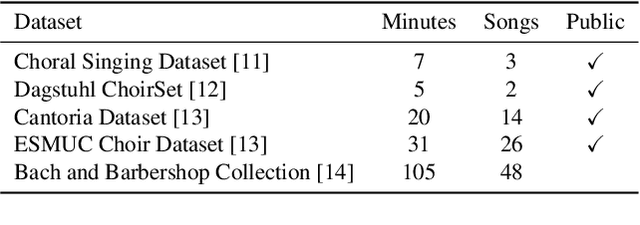
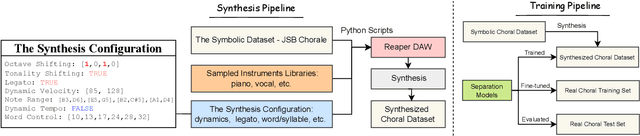
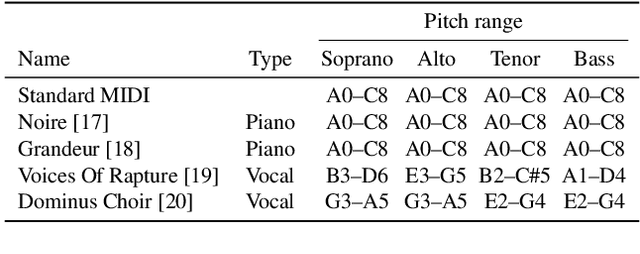

Choral music separation refers to the task of extracting tracks of voice parts (e.g., soprano, alto, tenor, and bass) from mixed audio. The lack of datasets has impeded research on this topic as previous work has only been able to train and evaluate models on a few minutes of choral music data due to copyright issues and dataset collection difficulties. In this paper, we investigate the use of synthesized training data for the source separation task on real choral music. We make three contributions: first, we provide an automated pipeline for synthesizing choral music data from sampled instrument plugins within controllable options for instrument expressiveness. This produces an 8.2-hour-long choral music dataset from the JSB Chorales Dataset and one can easily synthesize additional data. Second, we conduct an experiment to evaluate multiple separation models on available choral music separation datasets from previous work. To the best of our knowledge, this is the first experiment to comprehensively evaluate choral music separation. Third, experiments demonstrate that the synthesized choral data is of sufficient quality to improve the model's performance on real choral music datasets. This provides additional experimental statistics and data support for the choral music separation study.
* Camera Ready for Proceedings of the 23rd International Society for Music Information Retrieval Conference, ISMIR 2022
Virtual impactor-based label-free bio-aerosol detection using holography and deep learning
Aug 30, 2022
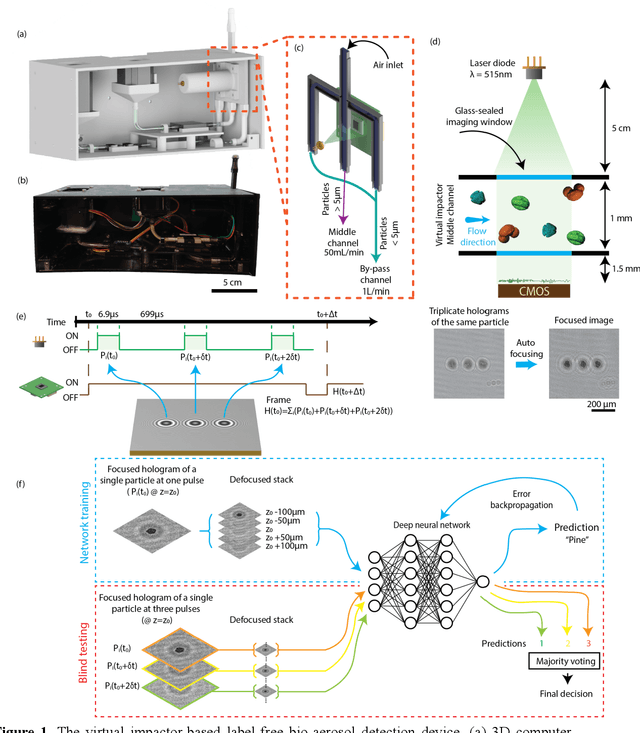
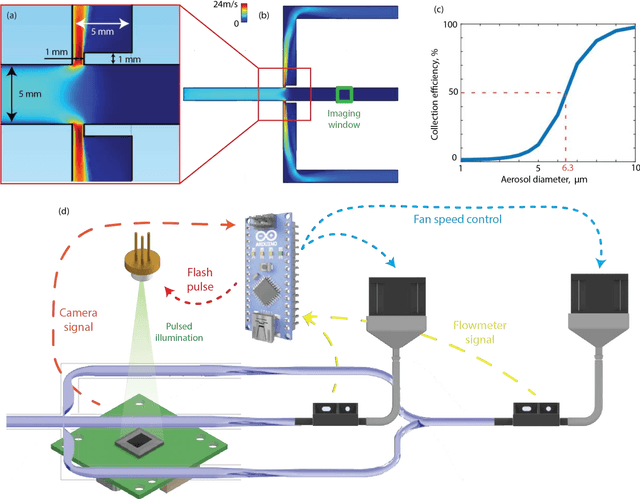

Exposure to bio-aerosols such as mold spores and pollen can lead to adverse health effects. There is a need for a portable and cost-effective device for long-term monitoring and quantification of various bio-aerosols. To address this need, we present a mobile and cost-effective label-free bio-aerosol sensor that takes holographic images of flowing particulate matter concentrated by a virtual impactor, which selectively slows down and guides particles larger than ~6 microns to fly through an imaging window. The flowing particles are illuminated by a pulsed laser diode, casting their inline holograms on a CMOS image sensor in a lens-free mobile imaging device. The illumination contains three short pulses with a negligible shift of the flowing particle within one pulse, and triplicate holograms of the same particle are recorded at a single frame before it exits the imaging field-of-view, revealing different perspectives of each particle. The particles within the virtual impactor are localized through a differential detection scheme, and a deep neural network classifies the aerosol type in a label-free manner, based on the acquired holographic images. We demonstrated the success of this mobile bio-aerosol detector with a virtual impactor using different types of pollen (i.e., bermuda, elm, oak, pine, sycamore, and wheat) and achieved a blind classification accuracy of 92.91%. This mobile and cost-effective device weighs ~700 g and can be used for label-free sensing and quantification of various bio-aerosols over extended periods since it is based on a cartridge-free virtual impactor that does not capture or immobilize particulate matter.