 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning via Learned Loss
Jun 12, 2019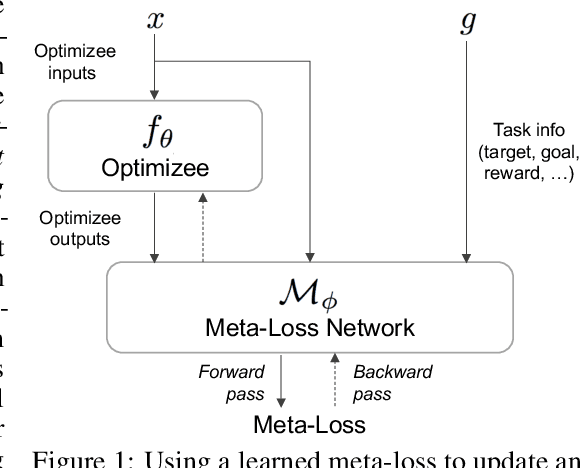
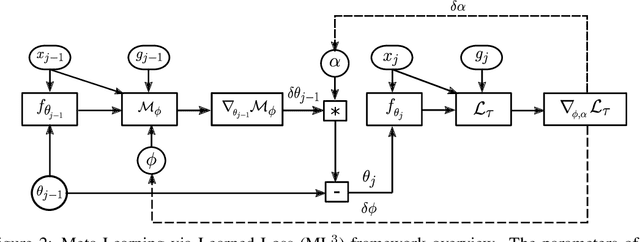
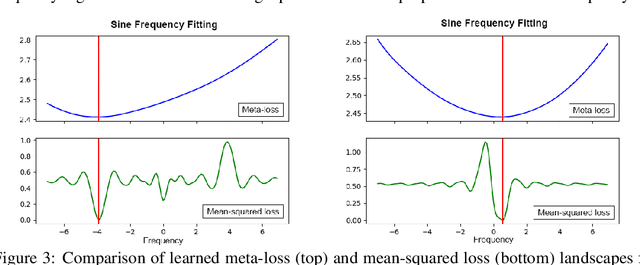
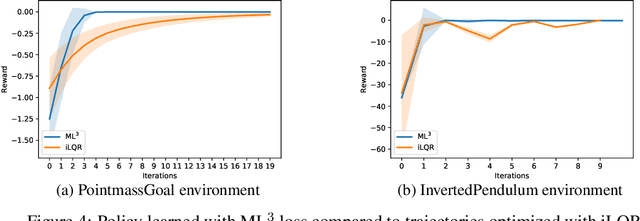
We present a meta-learning approach based on learning an adaptive, high-dimensional loss function that can generalize across multiple tasks and different model architectures. We develop a fully differentiable pipeline for learning a loss function targeted at maximizing the performance of an optimizee trained using this loss function. We observe that the loss landscape produced by our learned loss significantly improves upon the original task-specific loss. We evaluate our method on supervised and reinforcement learning tasks. Furthermore, we show that our pipeline is able to operate in sparse reward and self-supervised reinforcement learning scenarios.
Learning Latent Space Dynamics for Tactile Servoing
Apr 15, 2019
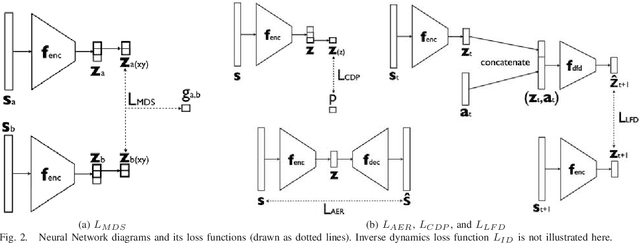

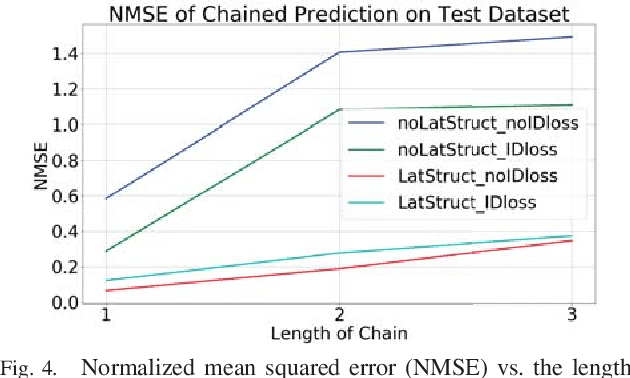
To achieve a dexterous robotic manipulation, we need to endow our robot with tactile feedback capability, i.e. the ability to drive action based on tactile sensing. In this paper, we specifically address the challenge of tactile servoing, i.e. given the current tactile sensing and a target/goal tactile sensing --memorized from a successful task execution in the past-- what is the action that will bring the current tactile sensing to move closer towards the target tactile sensing at the next time step. We develop a data-driven approach to acquire a dynamics model for tactile servoing by learning from demonstration. Moreover, our method represents the tactile sensing information as to lie on a surface --or a 2D manifold-- and perform a manifold learning, making it applicable to any tactile skin geometry. We evaluate our method on a contact point tracking task using a robot equipped with a tactile finger. A video demonstrating our approach can be seen in https://youtu.be/0QK0-Vx7WkI
Closing the Sim-to-Real Loop: Adapting Simulation Randomization with Real World Experience
Mar 05, 2019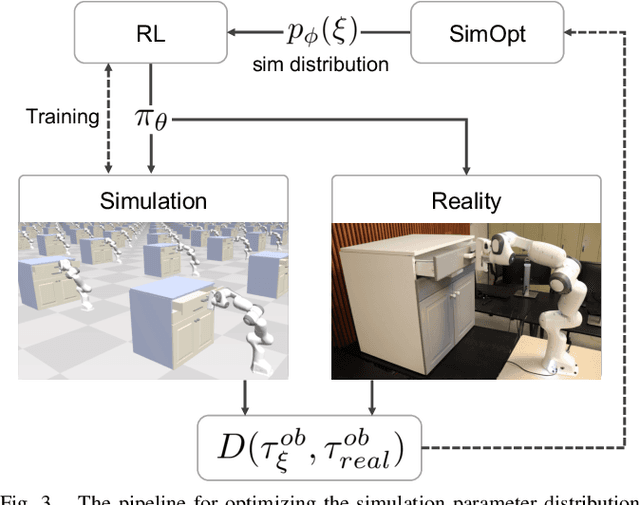

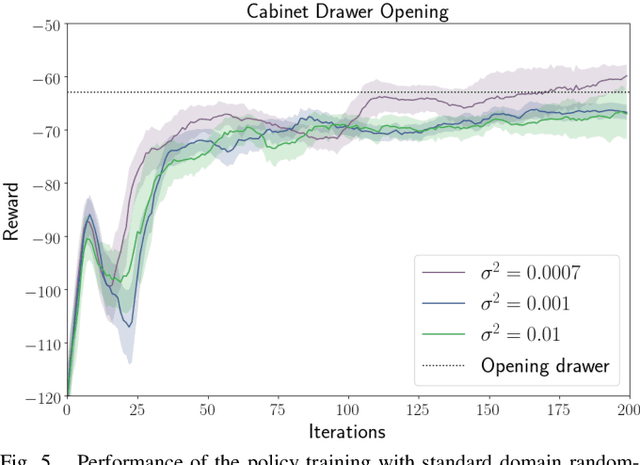
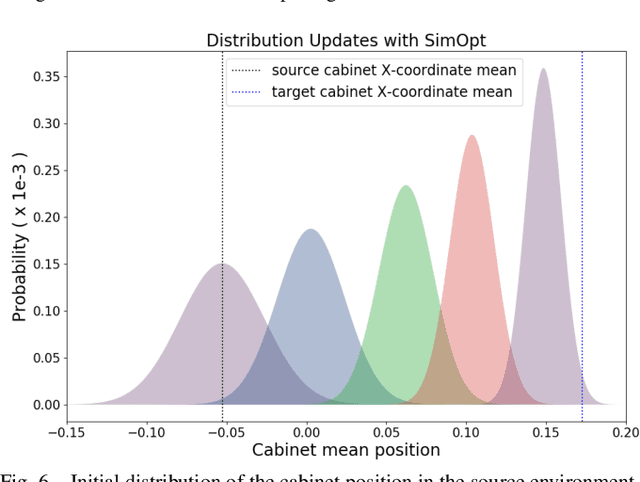
We consider the problem of transferring policies to the real world by training on a distribution of simulated scenarios. Rather than manually tuning the randomization of simulations, we adapt the simulation parameter distribution using a few real world roll-outs interleaved with policy training. In doing so, we are able to change the distribution of simulations to improve the policy transfer by matching the policy behavior in simulation and the real world. We show that policies trained with our method are able to reliably transfer to different robots in two real world tasks: swing-peg-in-hole and opening a cabinet drawer. The video of our experiments can be found at https://sites.google.com/view/simopt
Path Integral Guided Policy Search
Oct 11, 2018
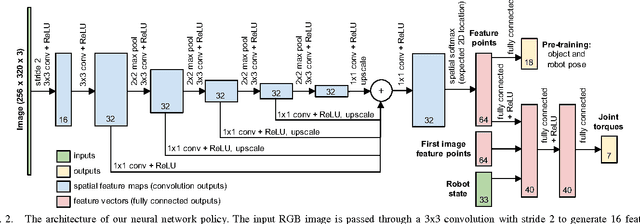

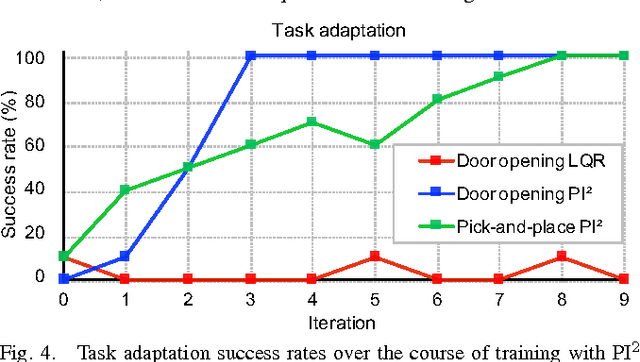
We present a policy search method for learning complex feedback control policies that map from high-dimensional sensory inputs to motor torques, for manipulation tasks with discontinuous contact dynamics. We build on a prior technique called guided policy search (GPS), which iteratively optimizes a set of local policies for specific instances of a task, and uses these to train a complex, high-dimensional global policy that generalizes across task instances. We extend GPS in the following ways: (1) we propose the use of a model-free local optimizer based on path integral stochastic optimal control (PI2), which enables us to learn local policies for tasks with highly discontinuous contact dynamics; and (2) we enable GPS to train on a new set of task instances in every iteration by using on-policy sampling: this increases the diversity of the instances that the policy is trained on, and is crucial for achieving good generalization. We show that these contributions enable us to learn deep neural network policies that can directly perform torque control from visual input. We validate the method on a challenging door opening task and a pick-and-place task, and we demonstrate that our approach substantially outperforms the prior LQR-based local policy optimizer on these tasks. Furthermore, we show that on-policy sampling significantly increases the generalization ability of these policies.
Time-Contrastive Networks: Self-Supervised Learning from Video
Mar 20, 2018

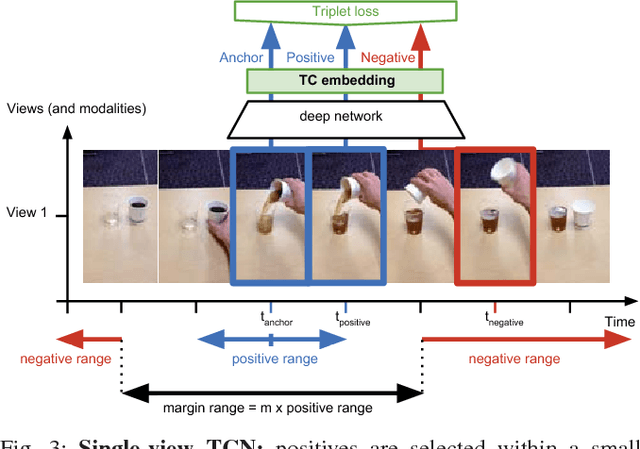
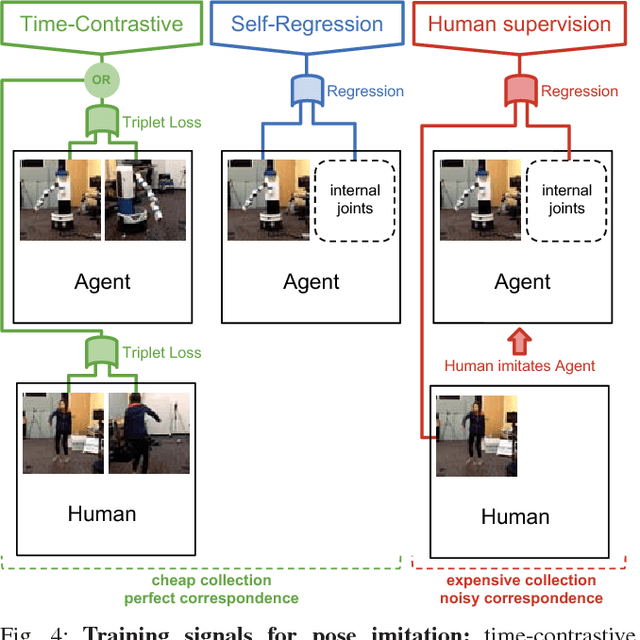
We propose a self-supervised approach for learning representations and robotic behaviors entirely from unlabeled videos recorded from multiple viewpoints, and study how this representation can be used in two robotic imitation settings: imitating object interactions from videos of humans, and imitating human poses. Imitation of human behavior requires a viewpoint-invariant representation that captures the relationships between end-effectors (hands or robot grippers) and the environment, object attributes, and body pose. We train our representations using a metric learning loss, where multiple simultaneous viewpoints of the same observation are attracted in the embedding space, while being repelled from temporal neighbors which are often visually similar but functionally different. In other words, the model simultaneously learns to recognize what is common between different-looking images, and what is different between similar-looking images. This signal causes our model to discover attributes that do not change across viewpoint, but do change across time, while ignoring nuisance variables such as occlusions, motion blur, lighting and background. We demonstrate that this representation can be used by a robot to directly mimic human poses without an explicit correspondence, and that it can be used as a reward function within a reinforcement learning algorithm. While representations are learned from an unlabeled collection of task-related videos, robot behaviors such as pouring are learned by watching a single 3rd-person demonstration by a human. Reward functions obtained by following the human demonstrations under the learned representation enable efficient reinforcement learning that is practical for real-world robotic systems. Video results, open-source code and dataset are available at https://sermanet.github.io/imitate
Multi-Modal Imitation Learning from Unstructured Demonstrations using Generative Adversarial Nets
Nov 23, 2017


Imitation learning has traditionally been applied to learn a single task from demonstrations thereof. The requirement of structured and isolated demonstrations limits the scalability of imitation learning approaches as they are difficult to apply to real-world scenarios, where robots have to be able to execute a multitude of tasks. In this paper, we propose a multi-modal imitation learning framework that is able to segment and imitate skills from unlabelled and unstructured demonstrations by learning skill segmentation and imitation learning jointly. The extensive simulation results indicate that our method can efficiently separate the demonstrations into individual skills and learn to imitate them using a single multi-modal policy. The video of our experiments is available at http://sites.google.com/view/nips17intentiongan
Combining Model-Based and Model-Free Updates for Trajectory-Centric Reinforcement Learning
Jun 18, 2017
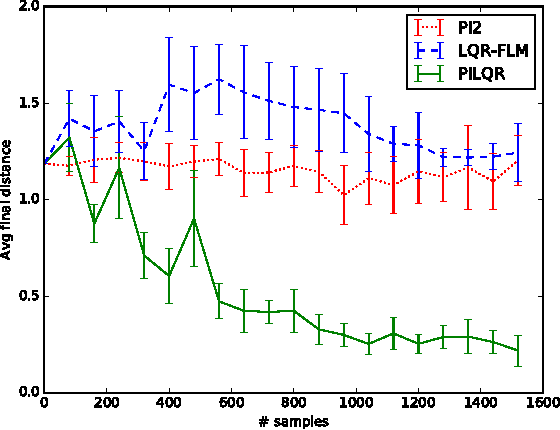
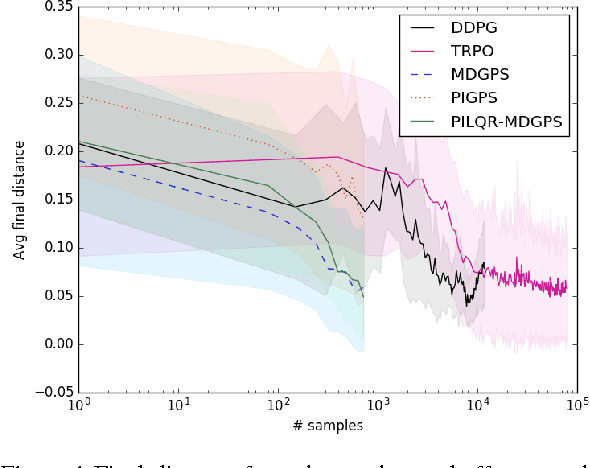
Reinforcement learning (RL) algorithms for real-world robotic applications need a data-efficient learning process and the ability to handle complex, unknown dynamical systems. These requirements are handled well by model-based and model-free RL approaches, respectively. In this work, we aim to combine the advantages of these two types of methods in a principled manner. By focusing on time-varying linear-Gaussian policies, we enable a model-based algorithm based on the linear quadratic regulator (LQR) that can be integrated into the model-free framework of path integral policy improvement (PI2). We can further combine our method with guided policy search (GPS) to train arbitrary parameterized policies such as deep neural networks. Our simulation and real-world experiments demonstrate that this method can solve challenging manipulation tasks with comparable or better performance than model-free methods while maintaining the sample efficiency of model-based methods. A video presenting our results is available at https://sites.google.com/site/icml17pilqr
Collective Robot Reinforcement Learning with Distributed Asynchronous Guided Policy Search
Oct 03, 2016
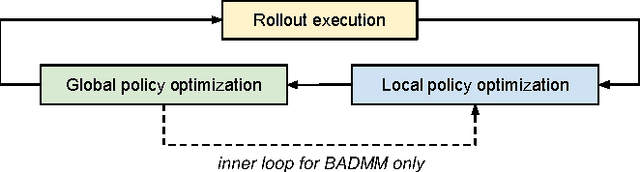
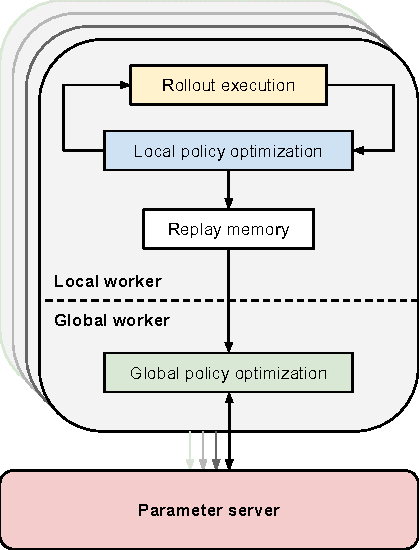
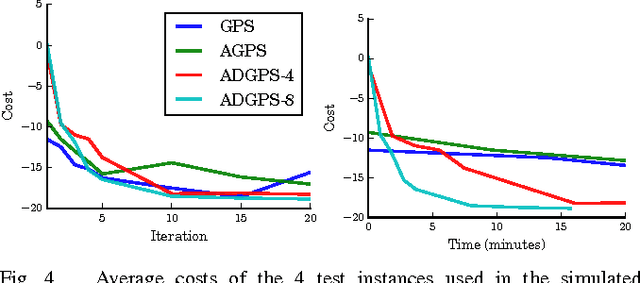
In principle, reinforcement learning and policy search methods can enable robots to learn highly complex and general skills that may allow them to function amid the complexity and diversity of the real world. However, training a policy that generalizes well across a wide range of real-world conditions requires far greater quantity and diversity of experience than is practical to collect with a single robot. Fortunately, it is possible for multiple robots to share their experience with one another, and thereby, learn a policy collectively. In this work, we explore distributed and asynchronous policy learning as a means to achieve generalization and improved training times on challenging, real-world manipulation tasks. We propose a distributed and asynchronous version of Guided Policy Search and use it to demonstrate collective policy learning on a vision-based door opening task using four robots. We show that it achieves better generalization, utilization, and training times than the single robot alternative.