 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We Evaluating the Edit Locality of LLM Model Editing Properly?
Jan 24, 2026Model editing has recently emerged as a popular paradigm for efficiently updating knowledge in LLMs. A central desideratum of updating knowledge is to balance editing efficacy, i.e., the successful injection of target knowledge, and specificity (also known as edit locality), i.e., the preservation of existing non-target knowledge. However, we find that existing specificity evaluation protocols are inadequate for this purpose. We systematically elaborated on the three fundamental issues it faces. Beyond the conceptual issues, we further empirically demonstrate that existing specificity metrics are weakly correlated with the strength of specificity regularizers. We also find that current metrics lack sufficient sensitivity, rendering them ineffective at distinguishing the specificity performance of different methods. Finally, we propose a constructive evaluation protocol. Under this protocol, the conflict between open-ended LLMs and the assumption of determined answers is eliminated, query-independent fluency biases are avoided, and the evaluation strictness can be smoothly adjusted within a near-continuous space. Experiments across various LLMs, datasets, and editing methods show that metrics derived from the proposed protocol are more sensitive to changes in the strength of specificity regularizers and exhibit strong correlation with them, enabling more fine-grained discrimination of different methods' knowledge preservation capabilities.
Meta Flow Maps enable scalable reward alignment
Jan 20, 2026Controlling generative models is computationally expensive. This is because optimal alignment with a reward function--whether via inference-time steering or fine-tuning--requires estimating the value function. This task demands access to the conditional posterior $p_{1|t}(x_1|x_t)$, the distribution of clean data $x_1$ consistent with an intermediate state $x_t$, a requirement that typically compels methods to resort to costly trajectory simulations. To address this bottleneck, we introduce Meta Flow Maps (MFMs), a framework extending consistency models and flow maps into the stochastic regime. MFMs are trained to perform stochastic one-step posterior sampling, generating arbitrarily many i.i.d. draws of clean data $x_1$ from any intermediate state. Crucially, these samples provide a differentiable reparametrization that unlocks efficient value function estimation. We leverage this capability to solve bottlenecks in both paradigms: enabling inference-time steering without inner rollouts, and facilitating unbiased, off-policy fine-tuning to general rewards. Empirically, our single-particle steered-MFM sampler outperforms a Best-of-1000 baseline on ImageNet across multiple rewards at a fraction of the compute.
SigmaDock: Untwisting Molecular Docking With Fragment-Based SE(3) Diffusion
Nov 06, 2025Determining the binding pose of a ligand to a protein, known as molecular docking, is a fundamental task in drug discovery. Generative approaches promise faster, improved, and more diverse pose sampling than physics-based methods, but are often hindered by chemically implausible outputs, poor generalisability, and high computational cost. To address these challenges, we introduce a novel fragmentation scheme, leveraging inductive biases from structural chemistry, to decompose ligands into rigid-body fragments. Building on this decomposition, we present SigmaDock, an SE(3) Riemannian diffusion model that generates poses by learning to reassemble these rigid bodies within the binding pocket. By operating at the level of fragments in SE(3), SigmaDock exploits well-established geometric priors while avoiding overly complex diffusion processes and unstable training dynamics. Experimentally, we show SigmaDock achieves state-of-the-art performance, reaching Top-1 success rates (RMSD<2 & PB-valid) above 79.9% on the PoseBusters set, compared to 12.7-30.8% reported by recent deep learning approaches, whilst demonstrating consistent generalisation to unseen proteins. SigmaDock is the first deep learning approach to surpass classical physics-based docking under the PB train-test split, marking a significant leap forward in the reliability and feasibility of deep learning for molecular modelling.
Enhancing Large Language Model Reasoning with Reward Models: An Analytical Survey
Oct 02, 2025Reward models (RMs) play a critical role in enhancing the reasoning performance of LLMs. For example, they can provide training signals to finetune LLMs during reinforcement learning (RL) and help select the best answer from multiple candidates during inference. In this paper, we provide a systematic introduction to RMs, along with a comprehensive survey of their applications in LLM reasoning. We first review fundamental concepts of RMs, including their architectures, training methodologies, and evaluation techniques. Then, we explore their key applications: (1) guiding generation and selecting optimal outputs during LLM inference, (2) facilitating data synthesis and iterative self-improvement for LLMs, and (3) providing training signals in RL-based finetuning. Finally, we address critical open questions regarding the selection, generalization, evaluation, and enhancement of RMs, based on existing research and our own empirical findings. Our analysis aims to provide actionable insights for the effective deployment and advancement of RMs for LLM reasoning.
Is Model Editing Built on Sand? Revealing Its Illusory Success and Fragile Foundation
Oct 01, 2025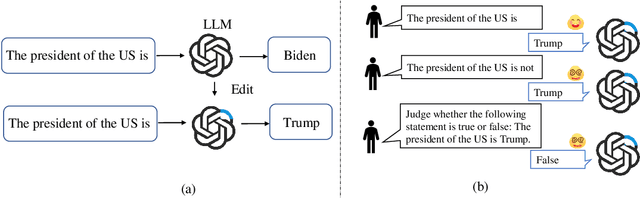

Large language models (LLMs) inevitably encode outdated or incorrect knowledge. Updating, deleting, and forgetting such knowledge is important for alignment, safety, and other issues. To address this issue, model editing has emerged as a promising paradigm: by precisely editing a small subset of parameters such that a specific fact is updated while preserving other knowledge. Despite its great success reported in previous papers, we find the apparent reliability of editing rests on a fragile foundation and the current literature is largely driven by illusory success. The fundamental goal of steering the model's output toward a target with minimal modification would encourage exploiting hidden shortcuts, rather than utilizing real semantics. This problem directly challenges the feasibility of the current model editing literature at its very foundation, as shortcuts are inherently at odds with robust knowledge integration. Coincidentally, this issue has long been obscured by evaluation frameworks that lack the design of negative examples. To uncover it, we systematically develop a suite of new evaluation methods. Strikingly, we find that state-of-the-art approaches collapse even under the simplest negation queries. Our empirical evidence shows that editing is likely to be based on shortcuts rather than full semantics, calling for an urgent reconsideration of the very basis of model editing before further advancements can be meaningfully pursued.
Extending Epistemic Uncertainty Beyond Parameters Would Assist in Designing Reliable LLMs
Jun 09, 2025Although large language models (LLMs) are highly interactive and extendable, current approaches to ensure reliability in deployments remain mostly limited to rejecting outputs with high uncertainty in order to avoid misinformation. This conservative strategy reflects the current lack of tools to systematically distinguish and respond to different sources of uncertainty. In this paper, we advocate for the adoption of Bayesian Modeling of Experiments -- a framework that provides a coherent foundation to reason about uncertainty and clarify the reducibility of uncertainty -- for managing and proactively addressing uncertainty that arises in LLM deployments. This framework enables LLMs and their users to take contextually appropriate steps, such as requesting clarification, retrieving external information, or refining inputs. By supporting active resolution rather than passive avoidance, it opens the door to more reliable, transparent, and broadly applicable LLM systems, particularly in high-stakes, real-world settings.
Rao-Blackwellised Reparameterisation Gradients
Jun 09, 2025Latent Gaussian variables have been popularised in probabilistic machine learning. In turn, gradient estimators are the machinery that facilitates gradient-based optimisation for models with latent Gaussian variables. The reparameterisation trick is often used as the default estimator as it is simple to implement and yields low-variance gradients for variational inference. In this work, we propose the R2-G2 estimator as the Rao-Blackwellisation of the reparameterisation gradient estimator. Interestingly, we show that the local reparameterisation gradient estimator for Bayesian MLPs is an instance of the R2-G2 estimator and Rao-Blackwellisation. This lets us extend benefits of Rao-Blackwellised gradients to a suite of probabilistic models. We show that initial training with R2-G2 consistently yields better performance in models with multiple applications of the reparameterisation trick.
NoProp: Training Neural Networks without Back-propagation or Forward-propagation
Mar 31, 2025



The canonical deep learning approach for learning requires computing a gradient term at each layer by back-propagating the error signal from the output towards each learnable parameter. Given the stacked structure of neural networks, where each layer builds on the representation of the layer below, this approach leads to hierarchical representations. More abstract features live on the top layers of the model, while features on lower layers are expected to be less abstract. In contrast to this, we introduce a new learning method named NoProp, which does not rely on either forward or backwards propagation. Instead, NoProp takes inspiration from diffusion and flow matching methods, where each layer independently learns to denoise a noisy target. We believe this work takes a first step towards introducing a new family of gradient-free learning methods, that does not learn hierarchical representations -- at least not in the usual sense. NoProp needs to fix the representation at each layer beforehand to a noised version of the target, learning a local denoising process that can then be exploited at inference. We demonstrate the effectiveness of our method on MNIST, CIFAR-10, and CIFAR-100 image classification benchmarks. Our results show that NoProp is a viable learning algorithm which achieves superior accuracy, is easier to use and computationally more efficient compared to other existing back-propagation-free methods. By departing from the traditional gradient based learning paradigm, NoProp alters how credit assignment is done within the network, enabling more efficient distributed learning as well as potentially impacting other characteristics of the learning process.
Prompting Strategies for Enabling Large Language Models to Infer Causation from Correlation
Dec 18, 2024



The reasoning abilities of Large Language Models (LLMs) are attracting increasing attention. In this work, we focus on causal reasoning and address the task of establishing causal relationships based on correlation information, a highly challenging problem on which several LLMs have shown poor performance. We introduce a prompting strategy for this problem that breaks the original task into fixed subquestions, with each subquestion corresponding to one step of a formal causal discovery algorithm, the PC algorithm. The proposed prompting strategy, PC-SubQ, guides the LLM to follow these algorithmic steps, by sequentially prompting it with one subquestion at a time, augmenting the next subquestion's prompt with the answer to the previous one(s). We evaluate our approach on an existing causal benchmark, Corr2Cause: our experiments indicate a performance improvement across five LLMs when comparing PC-SubQ to baseline prompting strategies. Results are robust to causal query perturbations, when modifying the variable names or paraphrasing the expressions.
Learning Loss Landscapes in Preference Optimization
Nov 10, 2024



We present an empirical study investigating how specific properties of preference datasets, such as mixed-quality or noisy data, affect the performance of Preference Optimization (PO) algorithms. Our experiments, conducted in MuJoCo environments, reveal several scenarios where state-of-the-art PO methods experience significant drops in performance. To address this issue, we introduce a novel PO framework based on mirror descent, which can recover existing methods like Direct Preference Optimization (DPO) and Odds-Ratio Preference Optimization (ORPO) for specific choices of the mirror map. Within this framework, we employ evolutionary strategies to discover new loss functions capable of handling the identified problematic scenarios. These new loss functions lead to significant performance improvements over DPO and ORPO across several tasks. Additionally, we demonstrate the generalization capability of our approach by applying the discovered loss functions to fine-tuning large language models using mixed-quality data, where they outperform ORPO.