 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDWTSumm: Discrete Wavelet Transform for Document Summarization
Apr 22, 2026Summarizing long, domain-specific documents with large language models (LLMs) remains challenging due to context limitations, information loss, and hallucinations, particularly in clinical and legal settings. We propose a Discrete Wavelet Transform (DWT)-based multi-resolution framework that treats text as a semantic signal and decomposes it into global (approximation) and local (detail) components. Applied to sentence- or word-level embeddings, DWT yields compact representations that preserve overall structure and critical domain-specific details, which are used directly as summaries or to guide LLM generation. Experiments on clinical and legal benchmarks demonstrate comparable ROUGE-L scores. Compared to a GPT-4o baseline, the DWT based summarization consistently improve semantic similarity and grounding, achieving gains of over 2% in BERTScore, more than 4\% in Semantic Fidelity, factual consistency in legal tasks, and large METEOR improvements indicative of preserved domain-specific semantics. Across multiple embedding models, Fidelity reaches up to 97%, suggesting that DWT acts as a semantic denoising mechanism that reduces hallucinations and strengthens factual grounding. Overall, DWT provides a lightweight, generalizable method for reliable long-document and domain-specific summarization with LLMs.
Semantic Compression for Word and Sentence Embeddings using Discrete Wavelet Transform
Jul 31, 2025Wavelet transforms, a powerful mathematical tool, have been widely used in different domains, including Signal and Image processing, to unravel intricate patterns, enhance data representation, and extract meaningful features from data. Tangible results from their application suggest that Wavelet transforms can be applied to NLP capturing a variety of linguistic and semantic properties. In this paper, we empirically leverage the application of Discrete Wavelet Transforms (DWT) to word and sentence embeddings. We aim to showcase the capabilities of DWT in analyzing embedding representations at different levels of resolution and compressing them while maintaining their overall quality. We assess the effectiveness of DWT embeddings on semantic similarity tasks to show how DWT can be used to consolidate important semantic information in an embedding vector. We show the efficacy of the proposed paradigm using different embedding models, including large language models, on downstream tasks. Our results show that DWT can reduce the dimensionality of embeddings by 50-93% with almost no change in performance for semantic similarity tasks, while achieving superior accuracy in most downstream tasks. Our findings pave the way for applying DWT to improve NLP applications.
A general-purpose method for applying Explainable AI for Anomaly Detection
Jul 23, 2022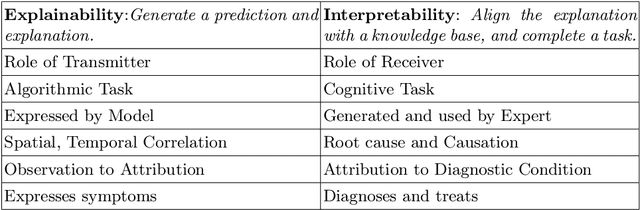
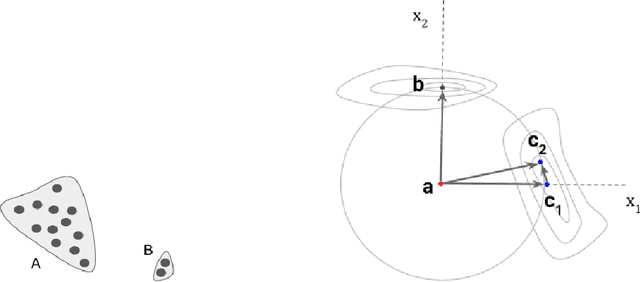

The need for explainable AI (XAI) is well established but relatively little has been published outside of the supervised learning paradigm. This paper focuses on a principled approach to applying explainability and interpretability to the task of unsupervised anomaly detection. We argue that explainability is principally an algorithmic task and interpretability is principally a cognitive task, and draw on insights from the cognitive sciences to propose a general-purpose method for practical diagnosis using explained anomalies. We define Attribution Error, and demonstrate, using real-world labeled datasets, that our method based on Integrated Gradients (IG) yields significantly lower attribution errors than alternative methods.
Semantic Preserving Bijective Mappings of Mathematical Formulae between Document Preparation Systems and Computer Algebra Systems
Sep 17, 2021
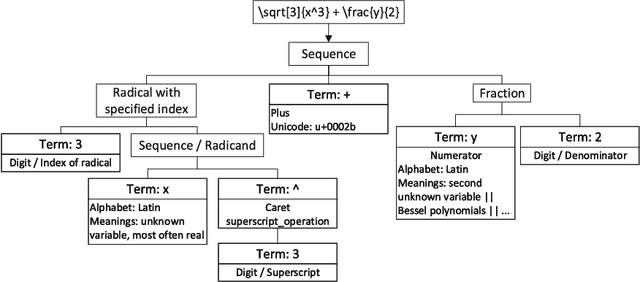
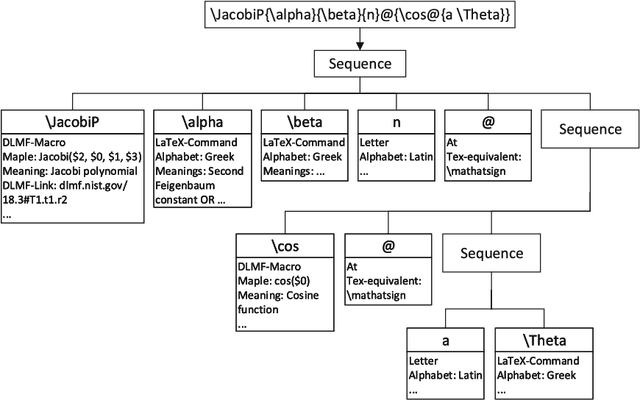
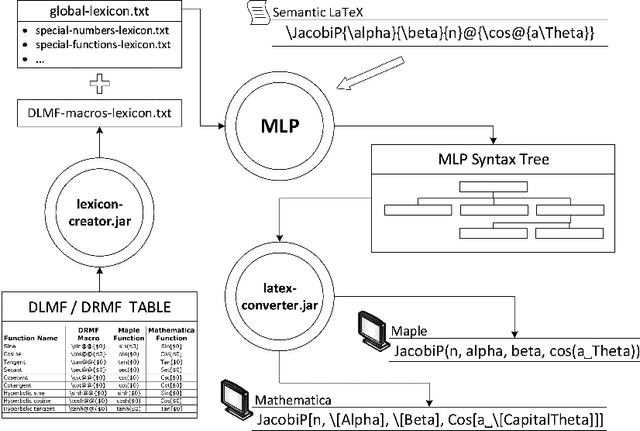
Document preparation systems like LaTeX offer the ability to render mathematical expressions as one would write these on paper. Using LaTeX, LaTeXML, and tools generated for use in the National Institute of Standards (NIST) Digital Library of Mathematical Functions, semantically enhanced mathematical LaTeX markup (semantic LaTeX) is achieved by using a semantic macro set. Computer algebra systems (CAS) such as Maple and Mathematica use alternative markup to represent mathematical expressions. By taking advantage of Youssef's Part-of-Math tagger and CAS internal representations, we develop algorithms to translate mathematical expressions represented in semantic LaTeX to corresponding CAS representations and vice versa. We have also developed tools for translating the entire Wolfram Encoding Continued Fraction Knowledge and University of Antwerp Continued Fractions for Special Functions datasets, for use in the NIST Digital Repository of Mathematical Formulae. The overall goal of these efforts is to provide semantically enriched standard conforming MathML representations to the public for formulae in digital mathematics libraries. These representations include presentation MathML, content MathML, generic LaTeX, semantic LaTeX, and now CAS representations as well.
Classification and Clustering of arXiv Documents, Sections, and Abstracts, Comparing Encodings of Natural and Mathematical Language
May 22, 2020
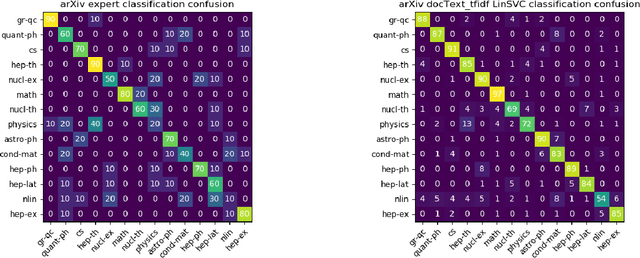

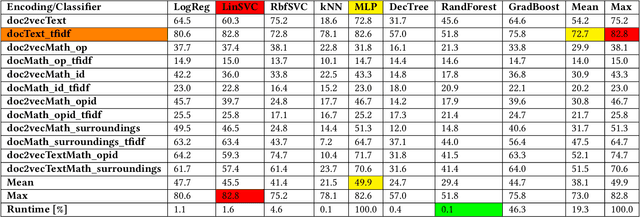
In this paper, we show how selecting and combining encodings of natural and mathematical language affect classification and clustering of documents with mathematical content. We demonstrate this by using sets of documents, sections, and abstracts from the arXiv preprint server that are labeled by their subject class (mathematics, computer science, physics, etc.) to compare different encodings of text and formulae and evaluate the performance and runtimes of selected classification and clustering algorithms. Our encodings achieve classification accuracies up to $82.8\%$ and cluster purities up to $69.4\%$ (number of clusters equals number of classes), and $99.9\%$ (unspecified number of clusters) respectively. We observe a relatively low correlation between text and math similarity, which indicates the independence of text and formulae and motivates treating them as separate features of a document. The classification and clustering can be employed, e.g., for document search and recommendation. Furthermore, we show that the computer outperforms a human expert when classifying documents. Finally, we evaluate and discuss multi-label classification and formula semantification.
Query Expansion for Patent Searching using Word Embedding and Professional Crowdsourcing
Nov 14, 2019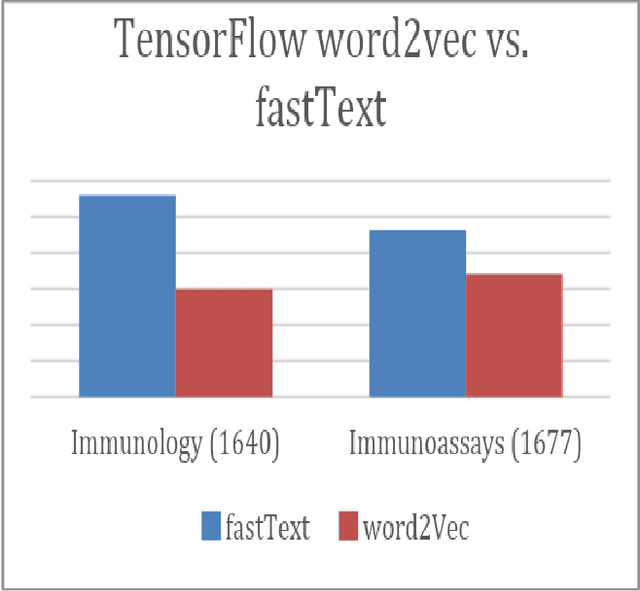
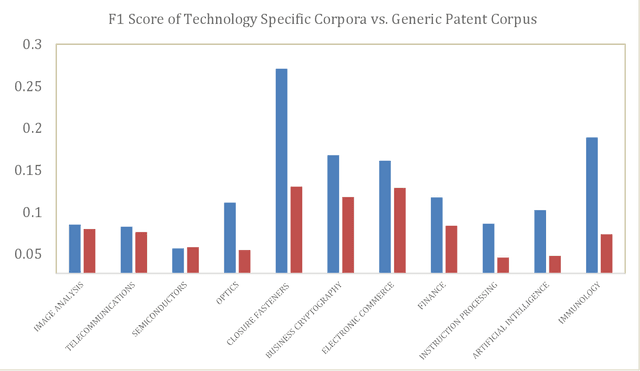
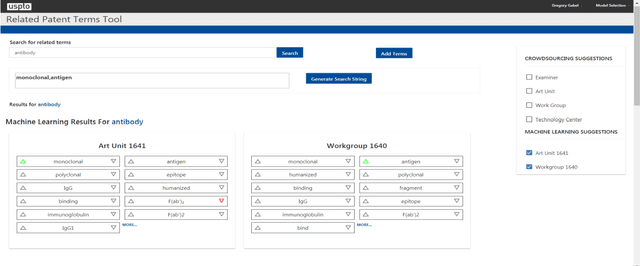
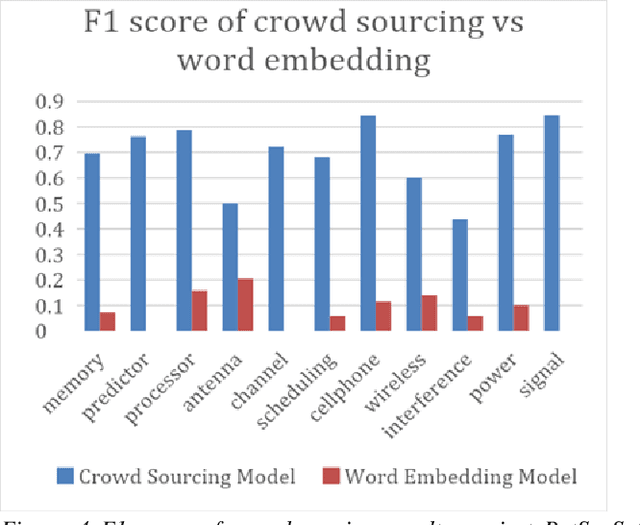
The patent examination process includes a search of previous work to verify that a patent application describes a novel invention. Patent examiners primarily use keyword-based searches to uncover prior art. A critical part of keyword searching is query expansion, which is the process of including alternate terms such as synonyms and other related words, since the same concepts are often described differently in the literature. Patent terminology is often domain specific. By curating technology-specific corpora and training word embedding models based on these corpora, we are able to automatically identify the most relevant expansions of a given word or phrase. We compare the performance of several automated query expansion techniques against expert specified expansions. Furthermore, we explore a novel mechanism to extract related terms not just based on one input term but several terms in conjunction by computing their centroid and identifying the nearest neighbors to this centroid. Highly skilled patent examiners are often the best and most reliable source of identifying related terms. By designing a user interface that allows examiners to interact with the word embedding suggestions, we are able to use these interactions to power crowdsourced modes of related terms. Learning from users allows us to overcome several challenges such as identifying words that are bleeding edge and have not been published in the corpus yet. This paper studies the effectiveness of word embedding and crowdsourced models across 11 disparate technical areas.
Anomaly Detection in Time Series of Graphs using Fusion of Graph Invariants
Oct 31, 2012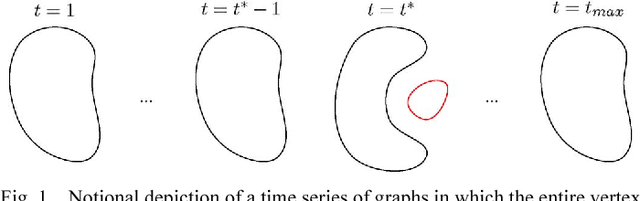
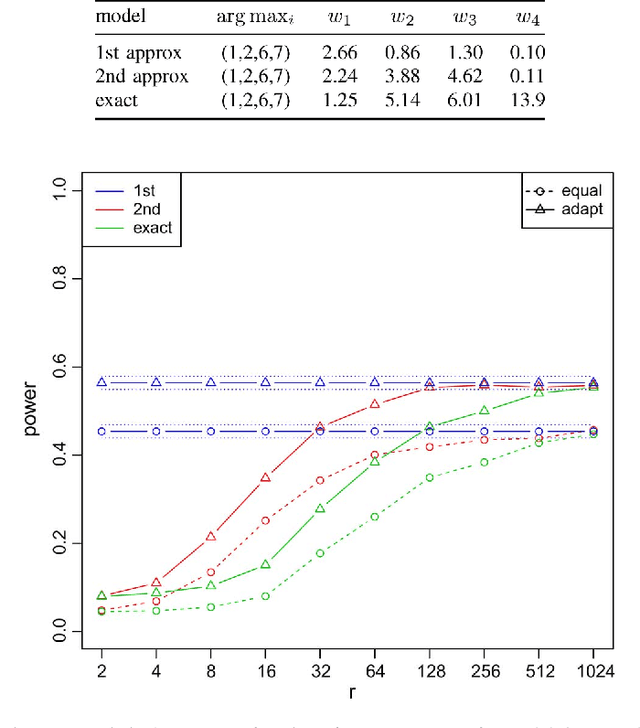
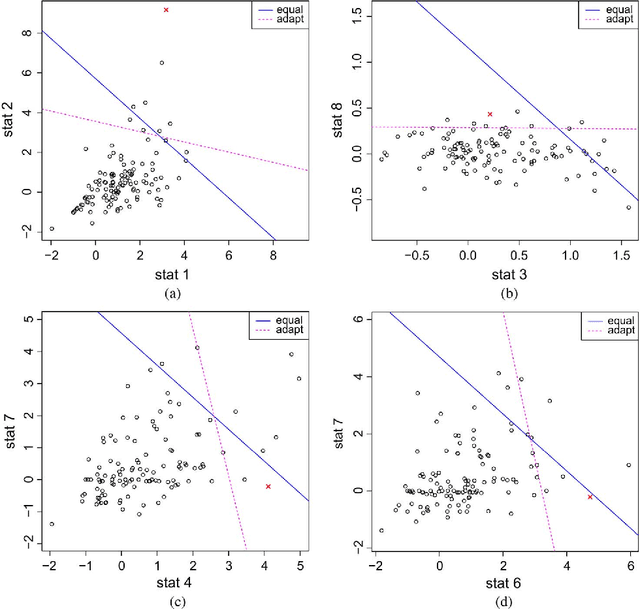
Given a time series of graphs G(t) = (V, E(t)), t = 1, 2, ..., where the fixed vertex set V represents "actors" and an edge between vertex u and vertex v at time t (uv \in E(t)) represents the existence of a communications event between actors u and v during the tth time period, we wish to detect anomalies and/or change points. We consider a collection of graph features, or invariants, and demonstrate that adaptive fusion provides superior inferential efficacy compared to naive equal weighting for a certain class of anomaly detection problems. Simulation results using a latent process model for time series of graphs, as well as illustrative experimental results for a time series of graphs derived from the Enron email data, show that a fusion statistic can provide superior inference compared to individual invariants alone. These results also demonstrate that an adaptive weighting scheme for fusion of invariants performs better than naive equal weighting.