 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing Deep Spiking Neural Networks from Artificial Neural Networks with Knowledge Distillation
Apr 17, 2023



Spiking neural networks (SNNs) are well known as the brain-inspired models with high computing efficiency, due to a key component that they utilize spikes as information units, close to the biological neural systems. Although spiking based models are energy efficient by taking advantage of discrete spike signals, their performance is limited by current network structures and their training methods. As discrete signals, typical SNNs cannot apply the gradient descent rules directly into parameters adjustment as artificial neural networks (ANNs). Aiming at this limitation, here we propose a novel method of constructing deep SNN models with knowledge distillation (KD) that uses ANN as teacher model and SNN as student model. Through ANN-SNN joint training algorithm, the student SNN model can learn rich feature information from the teacher ANN model through the KD method, yet it avoids training SNN from scratch when communicating with non-differentiable spikes. Our method can not only build a more efficient deep spiking structure feasibly and reasonably, but use few time steps to train whole model compared to direct training or ANN to SNN methods. More importantly, it has a superb ability of noise immunity for various types of artificial noises and natural signals. The proposed novel method provides efficient ways to improve the performance of SNN through constructing deeper structures in a high-throughput fashion, with potential usage for light and efficient brain-inspired computing of practical scenarios.
3D reconstruction of spherical images: A review of techniques, applications, and prospects
Feb 09, 2023



3D reconstruction plays an increasingly important role in modern photogrammetric systems. Conventional satellite or aerial-based remote sensing (RS) platforms can provide the necessary data sources for the 3D reconstruction of large-scale landforms and cities. Even with low-altitude UAVs (Unmanned Aerial Vehicles), 3D reconstruction in complicated situations, such as urban canyons and indoor scenes, is challenging due to frequent tracking failures between camera frames and high data collection costs. Recently, spherical images have been extensively used due to the capability of recording surrounding environments from one camera exposure. In contrast to perspective images with limited FOV (Field of View), spherical images can cover the whole scene with full horizontal and vertical FOV and facilitate camera tracking and data acquisition in these complex scenes. With the rapid evolution and extensive use of professional and consumer-grade spherical cameras, spherical images show great potential for the 3D modeling of urban and indoor scenes. Classical 3D reconstruction pipelines, however, cannot be directly used for spherical images. Besides, there exist few software packages that are designed for the 3D reconstruction of spherical images. As a result, this research provides a thorough survey of the state-of-the-art for 3D reconstruction of spherical images in terms of data acquisition, feature detection and matching, image orientation, and dense matching as well as presenting promising applications and discussing potential prospects. We anticipate that this study offers insightful clues to direct future research.
Enhancing Adversarial Training with Feature Separability
May 02, 2022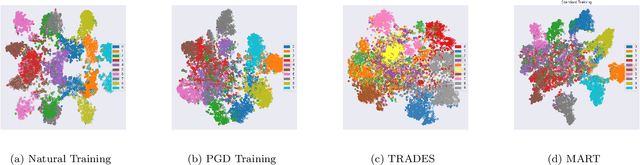
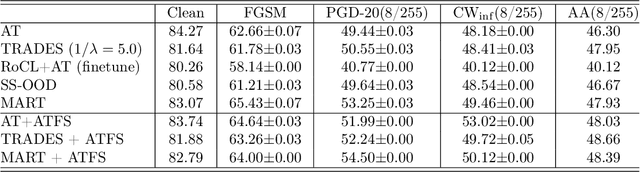
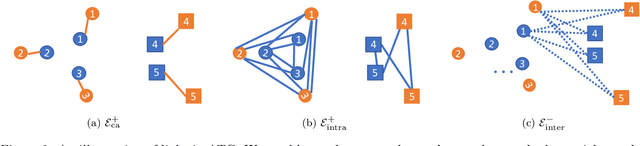
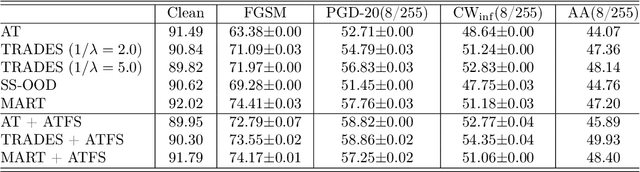
Deep Neural Network (DNN) are vulnerable to adversarial attacks. As a countermeasure, adversarial training aims to achieve robustness based on the min-max optimization problem and it has shown to be one of the most effective defense strategies. However, in this work, we found that compared with natural training, adversarial training fails to learn better feature representations for either clean or adversarial samples, which can be one reason why adversarial training tends to have severe overfitting issues and less satisfied generalize performance. Specifically, we observe two major shortcomings of the features learned by existing adversarial training methods:(1) low intra-class feature similarity; and (2) conservative inter-classes feature variance. To overcome these shortcomings, we introduce a new concept of adversarial training graph (ATG) with which the proposed adversarial training with feature separability (ATFS) enables to coherently boost the intra-class feature similarity and increase inter-class feature variance. Through comprehensive experiments, we demonstrate that the proposed ATFS framework significantly improves both clean and robust performance.
Trustworthy AI: A Computational Perspective
Aug 02, 2021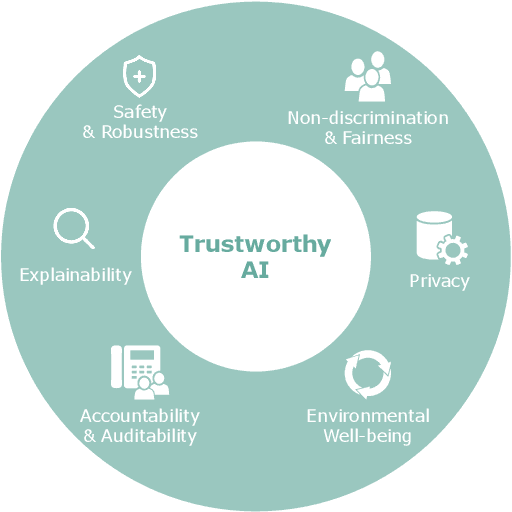
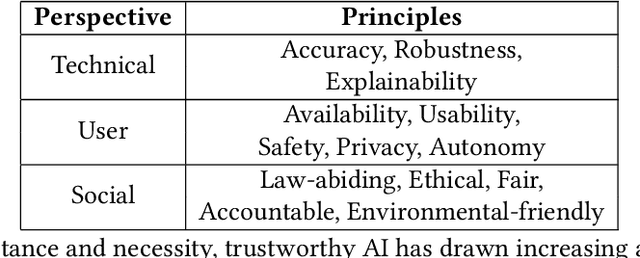
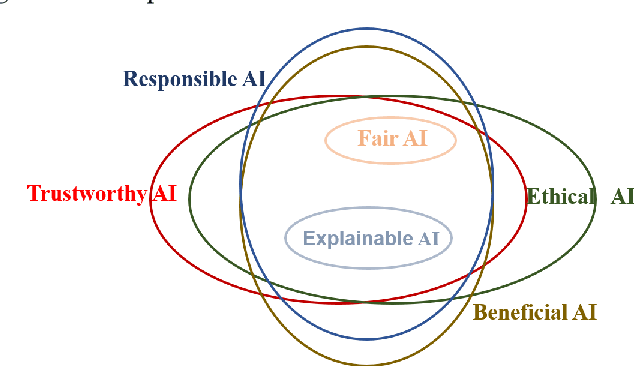
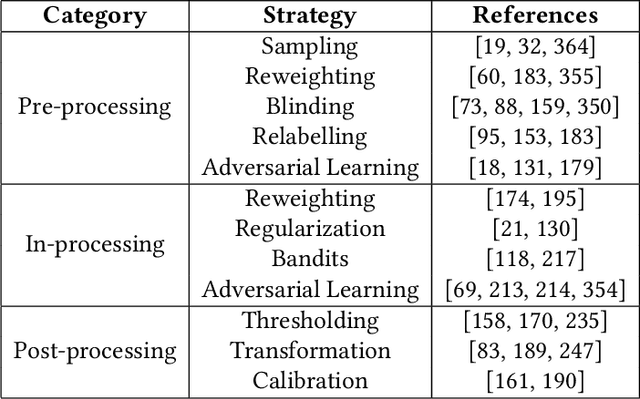
In the past few decades, artificial intelligence (AI) technology has experienced swift developments, changing everyone's daily life and profoundly altering the course of human society. The intention of developing AI is to benefit humans, by reducing human labor, bringing everyday convenience to human lives, and promoting social good. However, recent research and AI applications show that AI can cause unintentional harm to humans, such as making unreliable decisions in safety-critical scenarios or undermining fairness by inadvertently discriminating against one group. Thus, trustworthy AI has attracted immense attention recently, which requires careful consideration to avoid the adverse effects that AI may bring to humans, so that humans can fully trust and live in harmony with AI technologies. Recent years have witnessed a tremendous amount of research on trustworthy AI. In this survey, we present a comprehensive survey of trustworthy AI from a computational perspective, to help readers understand the latest technologies for achieving trustworthy AI. Trustworthy AI is a large and complex area, involving various dimensions. In this work, we focus on six of the most crucial dimensions in achieving trustworthy AI: (i) Safety & Robustness, (ii) Non-discrimination & Fairness, (iii) Explainability, (iv) Privacy, (v) Accountability & Auditability, and (vi) Environmental Well-Being. For each dimension, we review the recent related technologies according to a taxonomy and summarize their applications in real-world systems. We also discuss the accordant and conflicting interactions among different dimensions and discuss potential aspects for trustworthy AI to investigate in the future.
Wood-leaf classification of tree point cloud based on intensity and geometrical information
Aug 02, 2021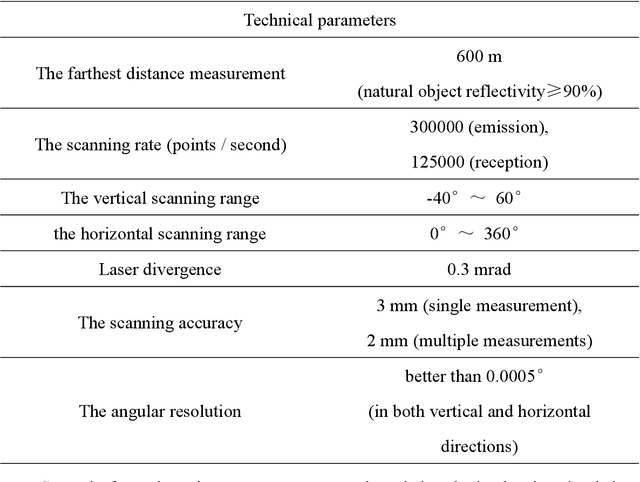

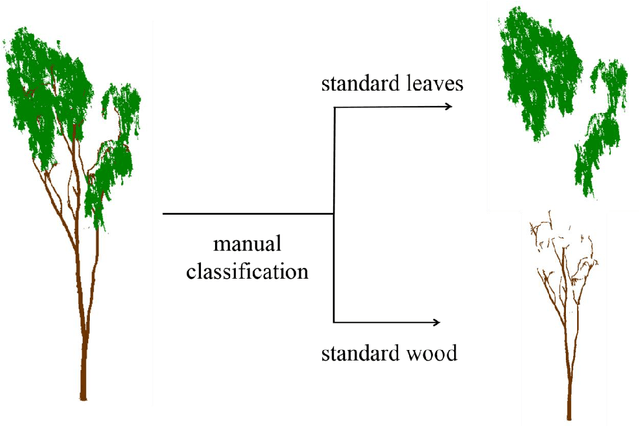
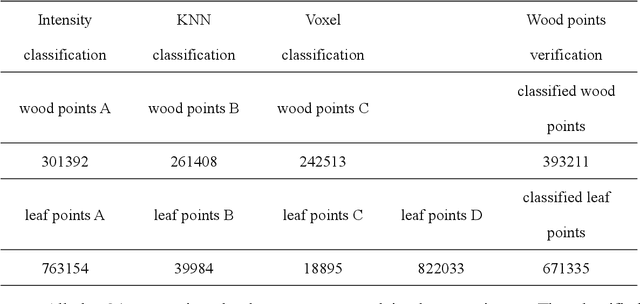
Terrestrial laser scanning (TLS) can obtain tree point cloud with high precision and high density. Efficient classification of wood points and leaf points is essential to study tree structural parameters and ecological characteristics. By using both the intensity and spatial information, a three-step classification and verification method was proposed to achieve automated wood-leaf classification. Tree point cloud was classified into wood points and leaf points by using intensity threshold, neighborhood density and voxelization successively. Experiment was carried in Haidian Park, Beijing, and 24 trees were scanned by using the RIEGL VZ-400 scanner. The tree point clouds were processed by using the proposed method, whose classification results were compared with the manual classification results which were used as standard results. To evaluate the classification accuracy, three indicators were used in the experiment, which are Overall Accuracy (OA), Kappa coefficient (Kappa) and Matthews correlation coefficient (MCC). The ranges of OA, Kappa and MCC of the proposed method are from 0.9167 to 0.9872, from 0.7276 to 0.9191, and from 0.7544 to 0.9211 respectively. The average values of OA, Kappa and MCC are 0.9550, 0.8547 and 0.8627 respectively. Time cost of wood-leaf classification was also recorded to evaluate the algorithm efficiency. The average processing time are 1.4 seconds per million points. The results showed that the proposed method performed well automatically and quickly on wood-leaf classification based on the experimental dataset.
Imbalanced Adversarial Training with Reweighting
Jul 28, 2021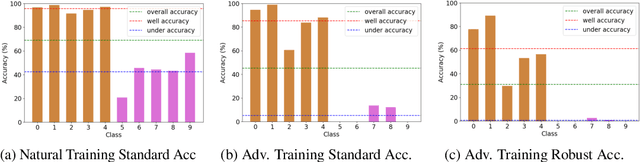
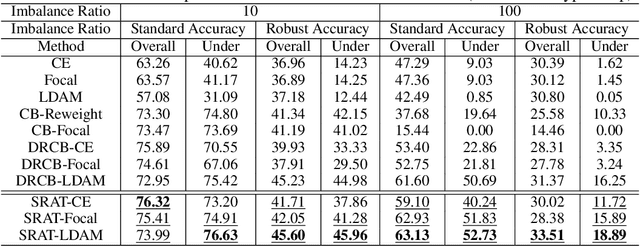
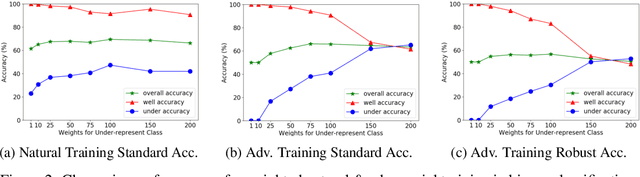
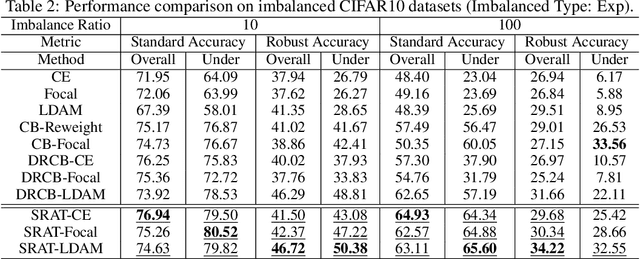
Adversarial training has been empirically proven to be one of the most effective and reliable defense methods against adversarial attacks. However, almost all existing studies about adversarial training are focused on balanced datasets, where each class has an equal amount of training examples. Research on adversarial training with imbalanced training datasets is rather limited. As the initial effort to investigate this problem, we reveal the facts that adversarially trained models present two distinguished behaviors from naturally trained models in imbalanced datasets: (1) Compared to natural training, adversarially trained models can suffer much worse performance on under-represented classes, when the training dataset is extremely imbalanced. (2) Traditional reweighting strategies may lose efficacy to deal with the imbalance issue for adversarial training. For example, upweighting the under-represented classes will drastically hurt the model's performance on well-represented classes, and as a result, finding an optimal reweighting value can be tremendously challenging. In this paper, to further understand our observations, we theoretically show that the poor data separability is one key reason causing this strong tension between under-represented and well-represented classes. Motivated by this finding, we propose Separable Reweighted Adversarial Training (SRAT) to facilitate adversarial training under imbalanced scenarios, by learning more separable features for different classes. Extensive experiments on various datasets verify the effectiveness of the proposed framework.
Elastic Graph Neural Networks
Jul 05, 2021
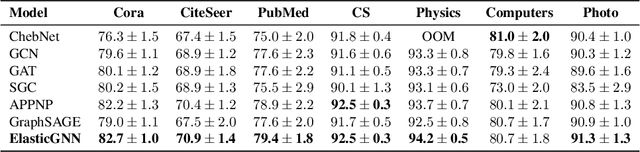
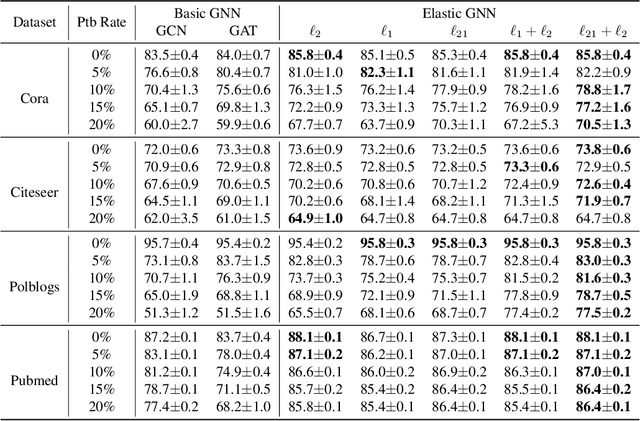
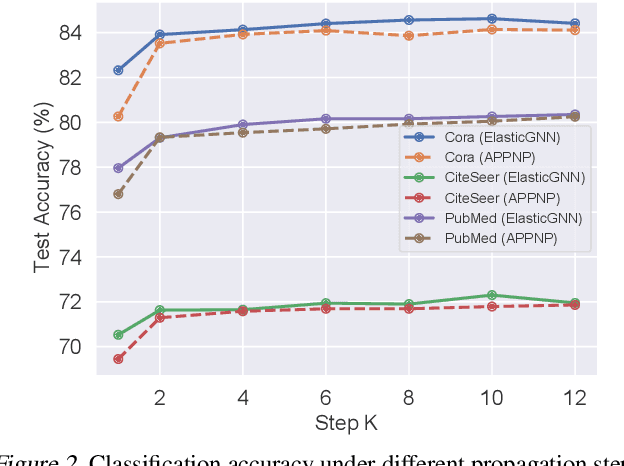
While many existing graph neural networks (GNNs) have been proven to perform $\ell_2$-based graph smoothing that enforces smoothness globally, in this work we aim to further enhance the local smoothness adaptivity of GNNs via $\ell_1$-based graph smoothing. As a result, we introduce a family of GNNs (Elastic GNNs) based on $\ell_1$ and $\ell_2$-based graph smoothing. In particular, we propose a novel and general message passing scheme into GNNs. This message passing algorithm is not only friendly to back-propagation training but also achieves the desired smoothing properties with a theoretical convergence guarantee. Experiments on semi-supervised learning tasks demonstrate that the proposed Elastic GNNs obtain better adaptivity on benchmark datasets and are significantly robust to graph adversarial attacks. The implementation of Elastic GNNs is available at \url{https://github.com/lxiaorui/ElasticGNN}.
Automatic sampling and training method for wood-leaf classification based on tree terrestrial point cloud
Dec 06, 2020

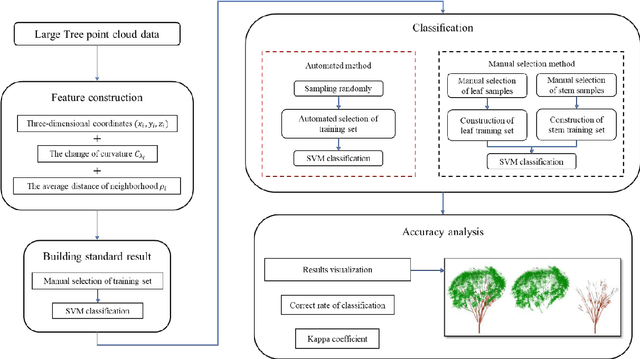
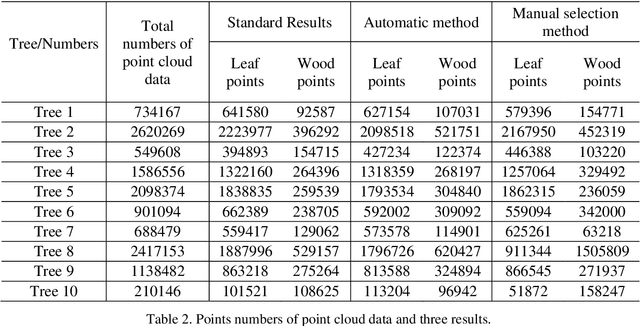
Terrestrial laser scanning technology provides an efficient and accuracy solution for acquiring three-dimensional information of plants. The leaf-wood classification of plant point cloud data is a fundamental step for some forestry and biological research. An automatic sampling and training method for classification was proposed based on tree point cloud data. The plane fitting method was used for selecting leaf sample points and wood sample points automatically, then two local features were calculated for training and classification by using support vector machine (SVM) algorithm. The point cloud data of ten trees were tested by using the proposed method and a manual selection method. The average correct classification rate and kappa coefficient are 0.9305 and 0.7904, respectively. The results show that the proposed method had better efficiency and accuracy comparing to the manual selection method.
To be Robust or to be Fair: Towards Fairness in Adversarial Training
Oct 13, 2020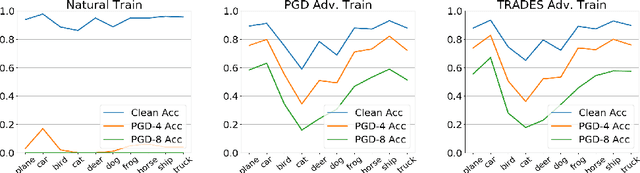

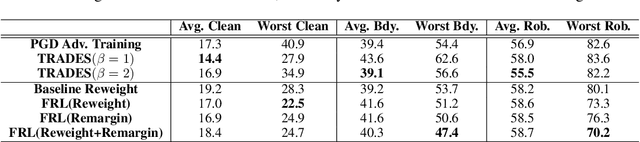
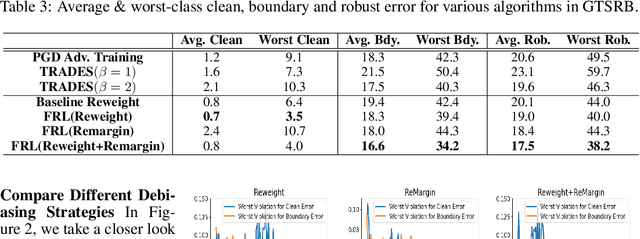
Adversarial training algorithms have been proven to be reliable to improve machine learning models' robustness against adversarial examples. However, we find that adversarial training algorithms tend to introduce severe disparity of accuracy and robustness between different groups of data. For instance, PGD adversarially trained ResNet18 model on CIFAR-10 has 93% clean accuracy and 67% PGD $l_\infty-8$ adversarial accuracy on the class "automobile" but only 59% and 17% on class "cat". This phenomenon happens in balanced datasets and does not exist in naturally trained models when only using clean samples. In this work, we theoretically show that this phenomenon can generally happen under adversarial training algorithms which minimize DNN models' robust errors. Motivated by these findings, we propose a Fair-Robust-Learning (FRL) framework to mitigate this unfairness problem when doing adversarial defenses and experimental results validate the effectiveness of FRL.
Yet Meta Learning Can Adapt Fast, It Can Also Break Easily
Sep 02, 2020Meta learning algorithms have been widely applied in many tasks for efficient learning, such as few-shot image classification and fast reinforcement learning. During meta training, the meta learner develops a common learning strategy, or experience, from a variety of learning tasks. Therefore, during meta test, the meta learner can use the learned strategy to quickly adapt to new tasks even with a few training samples. However, there is still a dark side about meta learning in terms of reliability and robustness. In particular, is meta learning vulnerable to adversarial attacks? In other words, would a well-trained meta learner utilize its learned experience to build wrong or likely useless knowledge, if an adversary unnoticeably manipulates the given training set? Without the understanding of this problem, it is extremely risky to apply meta learning in safety-critical applications. Thus, in this paper, we perform the initial study about adversarial attacks on meta learning under the few-shot classification problem. In particular, we formally define key elements of adversarial attacks unique to meta learning and propose the first attacking algorithm against meta learning under various settings. We evaluate the effectiveness of the proposed attacking strategy as well as the robustness of several representative meta learning algorithms. Experimental results demonstrate that the proposed attacking strategy can easily break the meta learner and meta learning is vulnerable to adversarial attacks. The implementation of the proposed framework will be released upon the acceptance of this paper.