 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Bellman: High-Order Generator Regression for Continuous-Time Policy Evaluation
Apr 21, 2026We study finite-horizon continuous-time policy evaluation from discrete closed-loop trajectories under time-inhomogeneous dynamics. The target value surface solves a backward parabolic equation, but the Bellman baseline obtained from one-step recursion is only first-order in the grid width. We estimate the time-dependent generator from multi-step transitions using moment-matching coefficients that cancel lower-order truncation terms, and combine the resulting surrogate with backward regression. The main theory gives an end-to-end decomposition into generator misspecification, projection error, pooling bias, finite-sample error, and start-up error, together with a decision-frequency regime map explaining when higher-order gains should be visible. Across calibration studies, four-scale benchmarks, feature and start-up ablations, and gain-mismatch stress tests, the second-order estimator consistently improves on the Bellman baseline and remains stable in the regime where the theory predicts visible gains. These results position high-order generator regression as an interpretable continuous-time policy-evaluation method with a clear operating region.
DataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models
Mar 27, 2026Data-centric training has emerged as a promising direction for improving large language models (LLMs) by optimizing not only model parameters but also the selection, composition, and weighting of training data during optimization. However, existing approaches to data selection, data mixture optimization, and data reweighting are often developed in isolated codebases with inconsistent interfaces, hindering reproducibility, fair comparison, and practical integration. In this paper, we present DataFlex, a unified data-centric dynamic training framework built upon LLaMA-Factory. DataFlex supports three major paradigms of dynamic data optimization: sample selection, domain mixture adjustment, and sample reweighting, while remaining fully compatible with the original training workflow. It provides extensible trainer abstractions and modular components, enabling a drop-in replacement for standard LLM training, and unifies key model-dependent operations such as embedding extraction, inference, and gradient computation, with support for large-scale settings including DeepSpeed ZeRO-3. We conduct comprehensive experiments across multiple data-centric methods. Dynamic data selection consistently outperforms static full-data training on MMLU across both Mistral-7B and Llama-3.2-3B. For data mixture, DoReMi and ODM improve both MMLU accuracy and corpus-level perplexity over default proportions when pretraining Qwen2.5-1.5B on SlimPajama at 6B and 30B token scales. DataFlex also achieves consistent runtime improvements over original implementations. These results demonstrate that DataFlex provides an effective, efficient, and reproducible infrastructure for data-centric dynamic training of LLMs.
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
Dec 18, 2025The rapidly growing demand for high-quality data in Large Language Models (LLMs) has intensified the need for scalable, reliable, and semantically rich data preparation pipelines. However, current practices remain dominated by ad-hoc scripts and loosely specified workflows, which lack principled abstractions, hinder reproducibility, and offer limited support for model-in-the-loop data generation. To address these challenges, we present DataFlow, a unified and extensible LLM-driven data preparation framework. DataFlow is designed with system-level abstractions that enable modular, reusable, and composable data transformations, and provides a PyTorch-style pipeline construction API for building debuggable and optimizable dataflows. The framework consists of nearly 200 reusable operators and six domain-general pipelines spanning text, mathematical reasoning, code, Text-to-SQL, agentic RAG, and large-scale knowledge extraction. To further improve usability, we introduce DataFlow-Agent, which automatically translates natural-language specifications into executable pipelines via operator synthesis, pipeline planning, and iterative verification. Across six representative use cases, DataFlow consistently improves downstream LLM performance. Our math, code, and text pipelines outperform curated human datasets and specialized synthetic baselines, achieving up to +3\% execution accuracy in Text-to-SQL over SynSQL, +7\% average improvements on code benchmarks, and 1--3 point gains on MATH, GSM8K, and AIME. Moreover, a unified 10K-sample dataset produced by DataFlow enables base models to surpass counterparts trained on 1M Infinity-Instruct data. These results demonstrate that DataFlow provides a practical and high-performance substrate for reliable, reproducible, and scalable LLM data preparation, and establishes a system-level foundation for future data-centric AI development.
Lost-in-the-Middle in Long-Text Generation: Synthetic Dataset, Evaluation Framework, and Mitigation
Mar 10, 2025Existing long-text generation methods primarily concentrate on producing lengthy texts from short inputs, neglecting the long-input and long-output tasks. Such tasks have numerous practical applications while lacking available benchmarks. Moreover, as the input grows in length, existing methods inevitably encounter the "lost-in-the-middle" phenomenon. In this paper, we first introduce a Long Input and Output Benchmark (LongInOutBench), including a synthetic dataset and a comprehensive evaluation framework, addressing the challenge of the missing benchmark. We then develop the Retrieval-Augmented Long-Text Writer (RAL-Writer), which retrieves and restates important yet overlooked content, mitigating the "lost-in-the-middle" issue by constructing explicit prompts. We finally employ the proposed LongInOutBench to evaluate our RAL-Writer against comparable baselines, and the results demonstrate the effectiveness of our approach. Our code has been released at https://github.com/OnlyAR/RAL-Writer.
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Jan 21, 2025This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks. Experiments demonstrate its superior performance: UI-TARS achieves SOTA performance in 10+ GUI agent benchmarks evaluating perception, grounding, and GUI task execution. Notably, in the OSWorld benchmark, UI-TARS achieves scores of 24.6 with 50 steps and 22.7 with 15 steps, outperforming Claude (22.0 and 14.9 respectively). In AndroidWorld, UI-TARS achieves 46.6, surpassing GPT-4o (34.5). UI-TARS incorporates several key innovations: (1) Enhanced Perception: leveraging a large-scale dataset of GUI screenshots for context-aware understanding of UI elements and precise captioning; (2) Unified Action Modeling, which standardizes actions into a unified space across platforms and achieves precise grounding and interaction through large-scale action traces; (3) System-2 Reasoning, which incorporates deliberate reasoning into multi-step decision making, involving multiple reasoning patterns such as task decomposition, reflection thinking, milestone recognition, etc. (4) Iterative Training with Reflective Online Traces, which addresses the data bottleneck by automatically collecting, filtering, and reflectively refining new interaction traces on hundreds of virtual machines. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations with minimal human intervention. We also analyze the evolution path of GUI agents to guide the further development of this domain.
EasyRAG: Efficient Retrieval-Augmented Generation Framework for Automated Network Operations
Oct 15, 2024This paper presents EasyRAG, a simple, lightweight, and efficient retrieval-augmented generation framework for automated network operations. Our framework has three advantages. The first is accurate question answering. We designed a straightforward RAG scheme based on (1) a specific data processing workflow (2) dual-route sparse retrieval for coarse ranking (3) LLM Reranker for reranking (4) LLM answer generation and optimization. This approach achieved first place in the GLM4 track in the preliminary round and second place in the GLM4 track in the semifinals. The second is simple deployment. Our method primarily consists of BM25 retrieval and BGE-reranker reranking, requiring no fine-tuning of any models, occupying minimal VRAM, easy to deploy, and highly scalable; we provide a flexible code library with various search and generation strategies, facilitating custom process implementation. The last one is efficient inference. We designed an efficient inference acceleration scheme for the entire coarse ranking, reranking, and generation process that significantly reduces the inference latency of RAG while maintaining a good level of accuracy; each acceleration scheme can be plug-and-play into any component of the RAG process, consistently enhancing the efficiency of the RAG system. Our code and data are released at \url{https://github.com/BUAADreamer/EasyRAG}.
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Mar 21, 2024



Efficient fine-tuning is vital for adapting large language models (LLMs) to downstream tasks. However, it requires non-trivial efforts to implement these methods on different models. We present LlamaFactory, a unified framework that integrates a suite of cutting-edge efficient training methods. It allows users to flexibly customize the fine-tuning of 100+ LLMs without the need for coding through the built-in web UI LlamaBoard. We empirically validate the efficiency and effectiveness of our framework on language modeling and text generation tasks. It has been released at https://github.com/hiyouga/LLaMA-Factory and already received over 13,000 stars and 1,600 forks.
Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation
Jan 21, 2022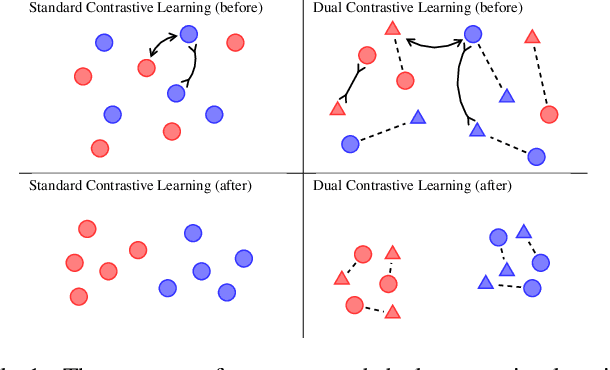
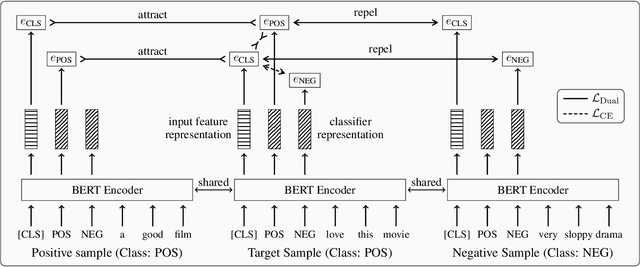
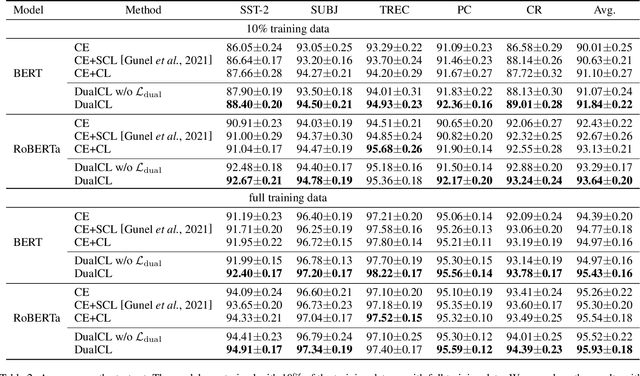
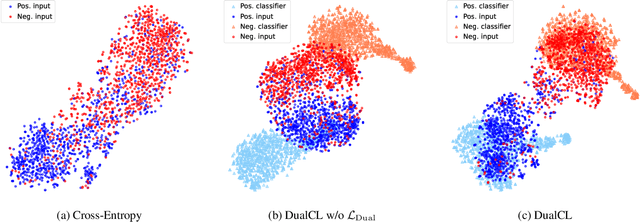
Contrastive learning has achieved remarkable success in representation learning via self-supervision in unsupervised settings. However, effectively adapting contrastive learning to supervised learning tasks remains as a challenge in practice. In this work, we introduce a dual contrastive learning (DualCL) framework that simultaneously learns the features of input samples and the parameters of classifiers in the same space. Specifically, DualCL regards the parameters of the classifiers as augmented samples associating to different labels and then exploits the contrastive learning between the input samples and the augmented samples. Empirical studies on five benchmark text classification datasets and their low-resource version demonstrate the improvement in classification accuracy and confirm the capability of learning discriminative representations of DualCL.
Robust Regularization with Adversarial Labelling of Perturbed Samples
May 28, 2021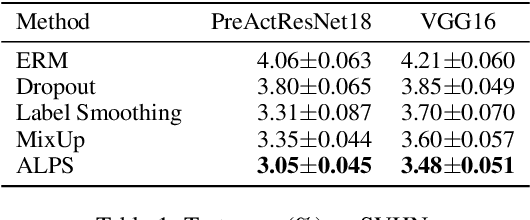



Recent researches have suggested that the predictive accuracy of neural network may contend with its adversarial robustness. This presents challenges in designing effective regularization schemes that also provide strong adversarial robustness. Revisiting Vicinal Risk Minimization (VRM) as a unifying regularization principle, we propose Adversarial Labelling of Perturbed Samples (ALPS) as a regularization scheme that aims at improving the generalization ability and adversarial robustness of the trained model. ALPS trains neural networks with synthetic samples formed by perturbing each authentic input sample towards another one along with an adversarially assigned label. The ALPS regularization objective is formulated as a min-max problem, in which the outer problem is minimizing an upper-bound of the VRM loss, and the inner problem is L$_1$-ball constrained adversarial labelling on perturbed sample. The analytic solution to the induced inner maximization problem is elegantly derived, which enables computational efficiency. Experiments on the SVHN, CIFAR-10, CIFAR-100 and Tiny-ImageNet datasets show that the ALPS has a state-of-the-art regularization performance while also serving as an effective adversarial training scheme.
Regularizing Neural Networks via Adversarial Model Perturbation
Oct 10, 2020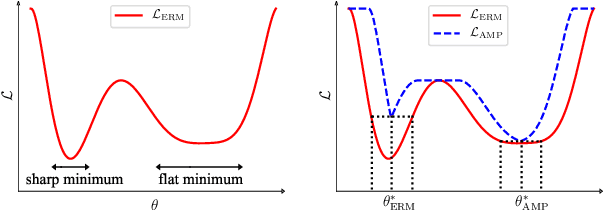
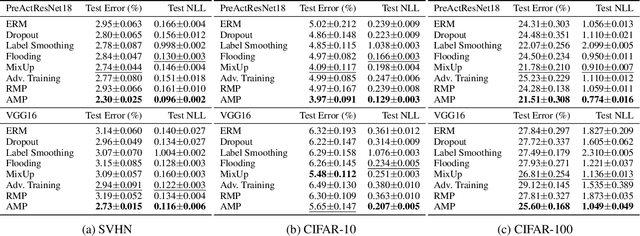
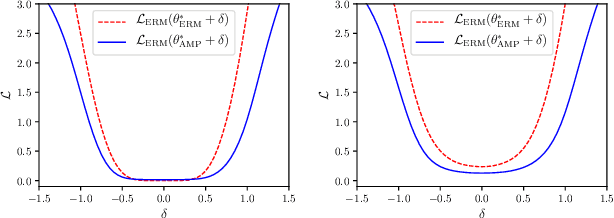
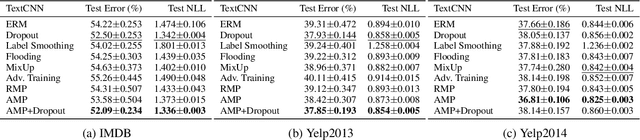
Recent research has suggested that when training neural networks, flat local minima of the empirical risk may cause the model to generalize better. Motivated by this understanding, we propose a new regularization scheme. In this scheme, referred to as adversarial model perturbation (AMP), instead directly minimizing the empirical risk, an alternative "AMP loss" function is minimized. Specifically, the AMP loss is obtained from the empirical risk by applying the "worst" norm-bounded perturbation on each point in the parameter space. We theoretically justify that minimizing the AMP loss favours flat local minima of the empirical risk and thereby improves generalization. Extensive experiments establish AMP as a new state of the art among regularization schemes.