 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy Modality Selection via Approximate Submodular Maximization
Oct 22, 2022Multimodal learning considers learning from multi-modality data, aiming to fuse heterogeneous sources of information. However, it is not always feasible to leverage all available modalities due to memory constraints. Further, training on all the modalities may be inefficient when redundant information exists within data, such as different subsets of modalities providing similar performance. In light of these challenges, we study modality selection, intending to efficiently select the most informative and complementary modalities under certain computational constraints. We formulate a theoretical framework for optimizing modality selection in multimodal learning and introduce a utility measure to quantify the benefit of selecting a modality. For this optimization problem, we present efficient algorithms when the utility measure exhibits monotonicity and approximate submodularity. We also connect the utility measure with existing Shapley-value-based feature importance scores. Last, we demonstrate the efficacy of our algorithm on synthetic (Patch-MNIST) and two real-world (PEMS-SF, CMU-MOSI) datasets.
Towards Multimodal Multitask Scene Understanding Models for Indoor Mobile Agents
Sep 27, 2022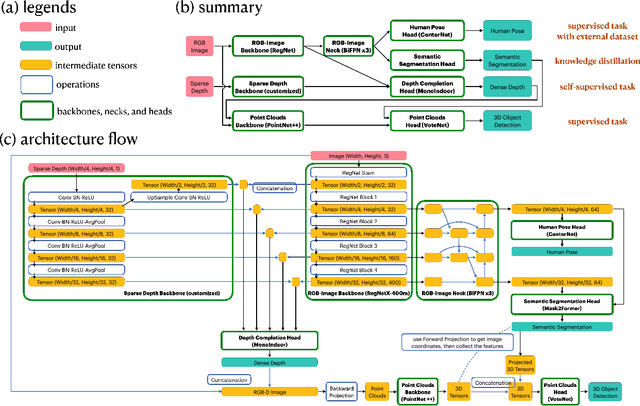
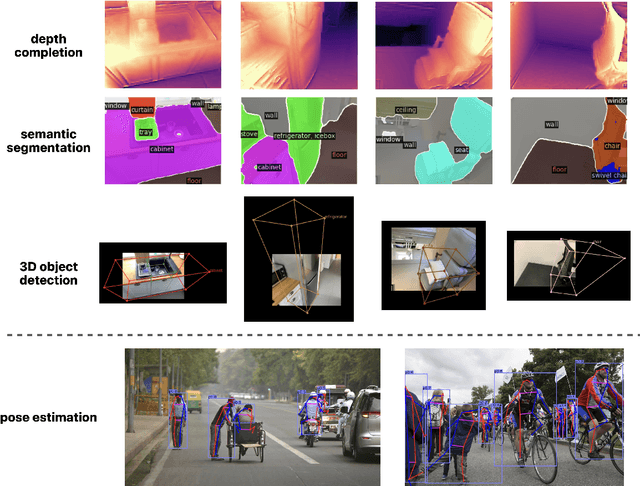
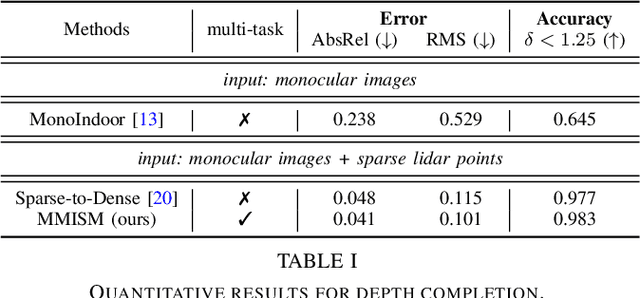
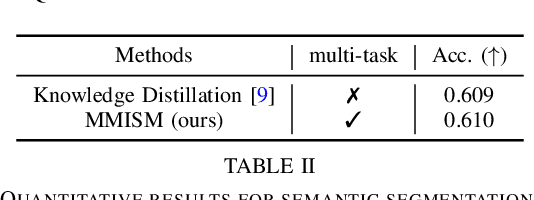
The perception system in personalized mobile agents requires developing indoor scene understanding models, which can understand 3D geometries, capture objectiveness, analyze human behaviors, etc. Nonetheless, this direction has not been well-explored in comparison with models for outdoor environments (e.g., the autonomous driving system that includes pedestrian prediction, car detection, traffic sign recognition, etc.). In this paper, we first discuss the main challenge: insufficient, or even no, labeled data for real-world indoor environments, and other challenges such as fusion between heterogeneous sources of information (e.g., RGB images and Lidar point clouds), modeling relationships between a diverse set of outputs (e.g., 3D object locations, depth estimation, and human poses), and computational efficiency. Then, we describe MMISM (Multi-modality input Multi-task output Indoor Scene understanding Model) to tackle the above challenges. MMISM considers RGB images as well as sparse Lidar points as inputs and 3D object detection, depth completion, human pose estimation, and semantic segmentation as output tasks. We show that MMISM performs on par or even better than single-task models; e.g., we improve the baseline 3D object detection results by 11.7% on the benchmark ARKitScenes dataset.
Paraphrasing Is All You Need for Novel Object Captioning
Sep 25, 2022
Novel object captioning (NOC) aims to describe images containing objects without observing their ground truth captions during training. Due to the absence of caption annotation, captioning models cannot be directly optimized via sequence-to-sequence training or CIDEr optimization. As a result, we present Paraphrasing-to-Captioning (P2C), a two-stage learning framework for NOC, which would heuristically optimize the output captions via paraphrasing. With P2C, the captioning model first learns paraphrasing from a language model pre-trained on text-only corpus, allowing expansion of the word bank for improving linguistic fluency. To further enforce the output caption sufficiently describing the visual content of the input image, we perform self-paraphrasing for the captioning model with fidelity and adequacy objectives introduced. Since no ground truth captions are available for novel object images during training, our P2C leverages cross-modality (image-text) association modules to ensure the above caption characteristics can be properly preserved. In the experiments, we not only show that our P2C achieves state-of-the-art performances on nocaps and COCO Caption datasets, we also verify the effectiveness and flexibility of our learning framework by replacing language and cross-modality association models for NOC. Implementation details and code are available in the supplementary materials.
Scale dependant layer for self-supervised nuclei encoding
Jul 22, 2022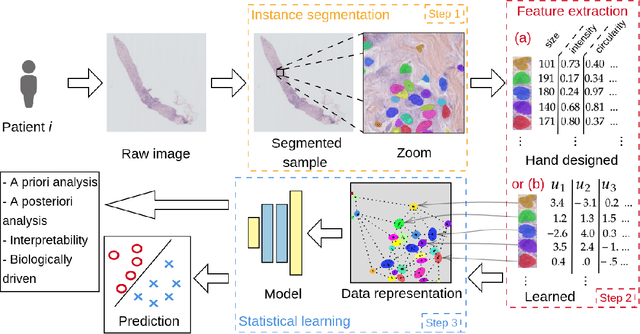
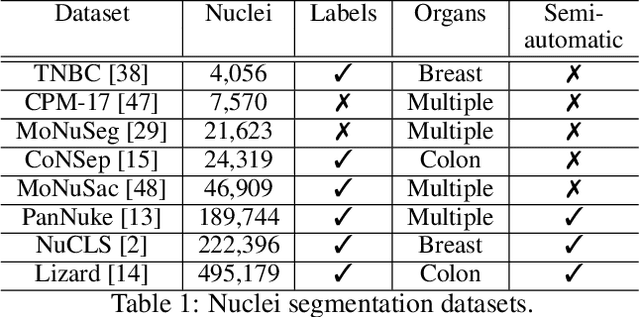
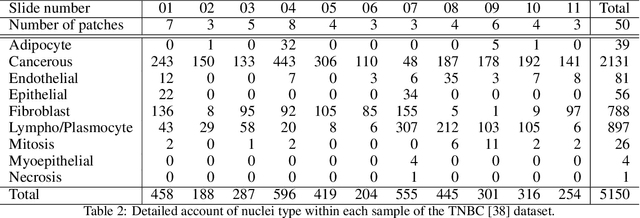
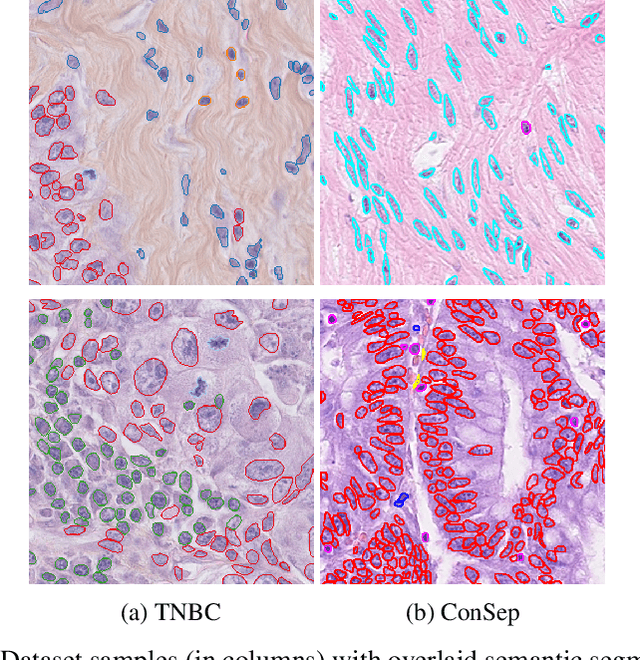
Recent developments in self-supervised learning give us the possibility to further reduce human intervention in multi-step pipelines where the focus evolves around particular objects of interest. In the present paper, the focus lays in the nuclei in histopathology images. In particular we aim at extracting cellular information in an unsupervised manner for a downstream task. As nuclei present themselves in a variety of sizes, we propose a new Scale-dependant convolutional layer to bypass scaling issues when resizing nuclei. On three nuclei datasets, we benchmark the following methods: handcrafted, pre-trained ResNet, supervised ResNet and self-supervised features. We show that the proposed convolution layer boosts performance and that this layer combined with Barlows-Twins allows for better nuclei encoding compared to the supervised paradigm in the low sample setting and outperforms all other proposed unsupervised methods. In addition, we extend the existing TNBC dataset to incorporate nuclei class annotation in order to enrich and publicly release a small sample setting dataset for nuclei segmentation and classification.
Learning Weakly-Supervised Contrastive Representations
Feb 18, 2022



We argue that a form of the valuable information provided by the auxiliary information is its implied data clustering information. For instance, considering hashtags as auxiliary information, we can hypothesize that an Instagram image will be semantically more similar with the same hashtags. With this intuition, we present a two-stage weakly-supervised contrastive learning approach. The first stage is to cluster data according to its auxiliary information. The second stage is to learn similar representations within the same cluster and dissimilar representations for data from different clusters. Our empirical experiments suggest the following three contributions. First, compared to conventional self-supervised representations, the auxiliary-information-infused representations bring the performance closer to the supervised representations, which use direct downstream labels as supervision signals. Second, our approach performs the best in most cases, when comparing our approach with other baseline representation learning methods that also leverage auxiliary data information. Third, we show that our approach also works well with unsupervised constructed clusters (e.g., no auxiliary information), resulting in a strong unsupervised representation learning approach.
Conditional Contrastive Learning with Kernel
Feb 14, 2022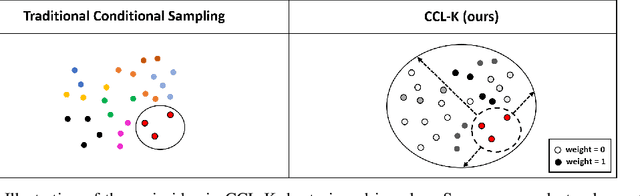



Conditional contrastive learning frameworks consider the conditional sampling procedure that constructs positive or negative data pairs conditioned on specific variables. Fair contrastive learning constructs negative pairs, for example, from the same gender (conditioning on sensitive information), which in turn reduces undesirable information from the learned representations; weakly supervised contrastive learning constructs positive pairs with similar annotative attributes (conditioning on auxiliary information), which in turn are incorporated into the representations. Although conditional contrastive learning enables many applications, the conditional sampling procedure can be challenging if we cannot obtain sufficient data pairs for some values of the conditioning variable. This paper presents Conditional Contrastive Learning with Kernel (CCL-K) that converts existing conditional contrastive objectives into alternative forms that mitigate the insufficient data problem. Instead of sampling data according to the value of the conditioning variable, CCL-K uses the Kernel Conditional Embedding Operator that samples data from all available data and assigns weights to each sampled data given the kernel similarity between the values of the conditioning variable. We conduct experiments using weakly supervised, fair, and hard negatives contrastive learning, showing CCL-K outperforms state-of-the-art baselines.
HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
Jun 14, 2021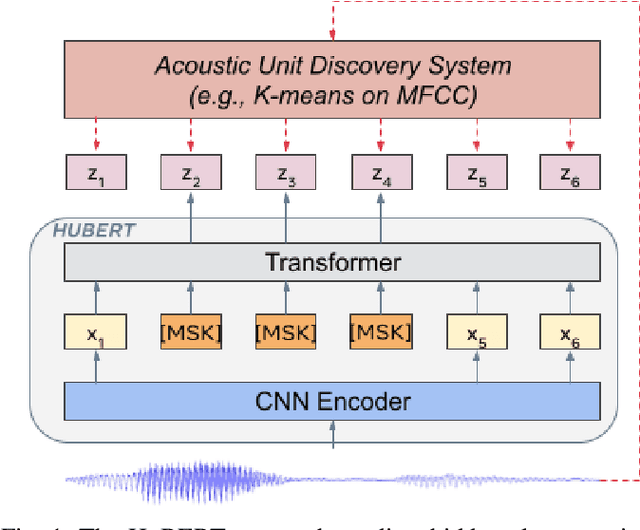
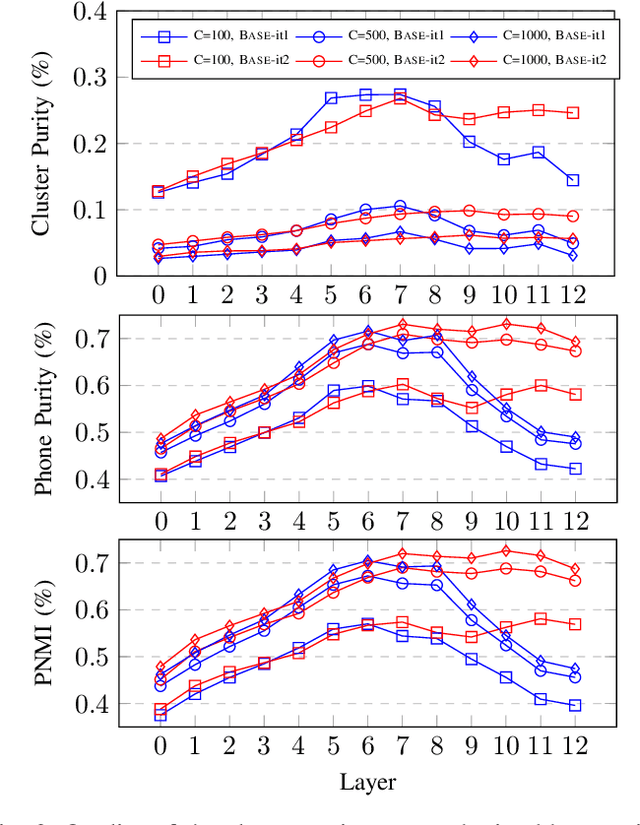
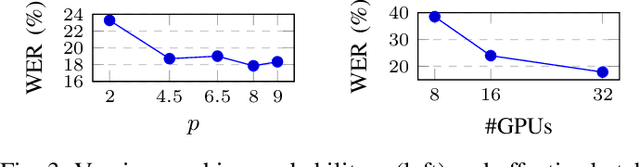
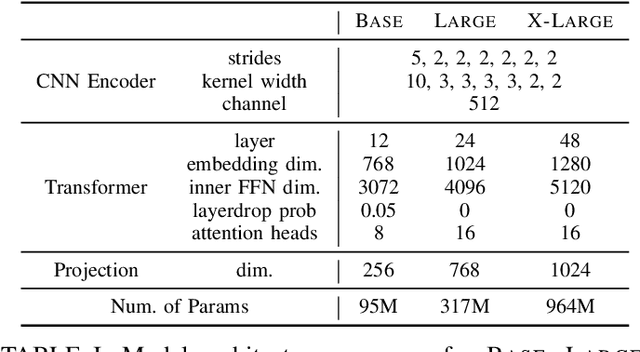
Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h, 10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER reduction on the more challenging dev-other and test-other evaluation subsets.
Integrating Auxiliary Information in Self-supervised Learning
Jun 05, 2021



This paper presents to integrate the auxiliary information (e.g., additional attributes for data such as the hashtags for Instagram images) in the self-supervised learning process. We first observe that the auxiliary information may bring us useful information about data structures: for instance, the Instagram images with the same hashtags can be semantically similar. Hence, to leverage the structural information from the auxiliary information, we present to construct data clusters according to the auxiliary information. Then, we introduce the Clustering InfoNCE (Cl-InfoNCE) objective that learns similar representations for augmented variants of data from the same cluster and dissimilar representations for data from different clusters. Our approach contributes as follows: 1) Comparing to conventional self-supervised representations, the auxiliary-information-infused self-supervised representations bring the performance closer to the supervised representations; 2) The presented Cl-InfoNCE can also work with unsupervised constructed clusters (e.g., k-means clusters) and outperform strong clustering-based self-supervised learning approaches, such as the Prototypical Contrastive Learning (PCL) method; 3) We show that Cl-InfoNCE may be a better approach to leverage the data clustering information, by comparing it to the baseline approach - learning to predict the clustering assignments with cross-entropy loss. For analysis, we connect the goodness of the learned representations with the statistical relationships: i) the mutual information between the labels and the clusters and ii) the conditional entropy of the clusters given the labels.
Conditional Contrastive Learning: Removing Undesirable Information in Self-Supervised Representations
Jun 05, 2021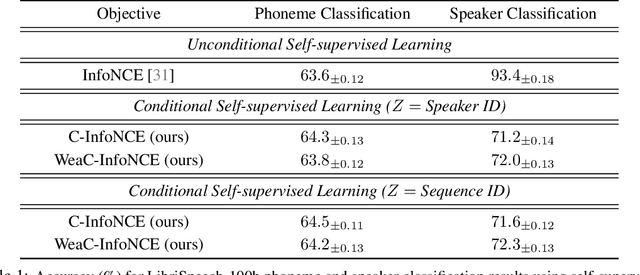
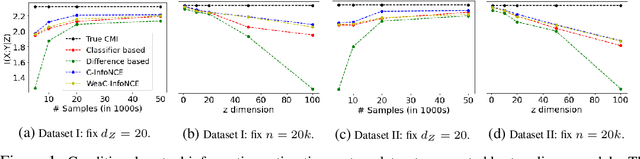
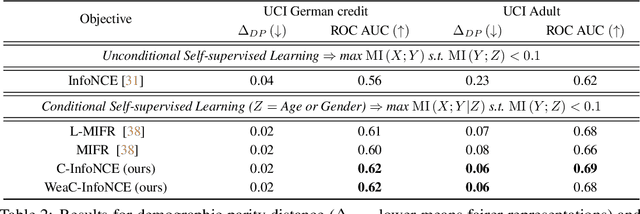
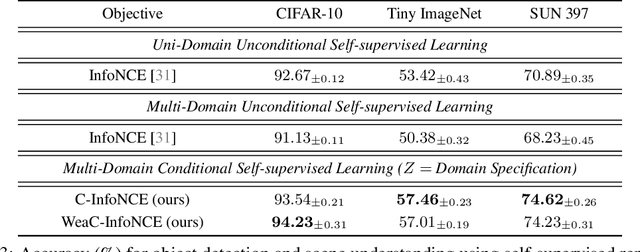
Self-supervised learning is a form of unsupervised learning that leverages rich information in data to learn representations. However, data sometimes contains certain information that may be undesirable for downstream tasks. For instance, gender information may lead to biased decisions on many gender-irrelevant tasks. In this paper, we develop conditional contrastive learning to remove undesirable information in self-supervised representations. To remove the effect of the undesirable variable, our proposed approach conditions on the undesirable variable (i.e., by fixing the variations of it) during the contrastive learning process. In particular, inspired by the contrastive objective InfoNCE, we introduce Conditional InfoNCE (C-InfoNCE), and its computationally efficient variant, Weak-Conditional InfoNCE (WeaC-InfoNCE), for conditional contrastive learning. We demonstrate empirically that our methods can successfully learn self-supervised representations for downstream tasks while removing a great level of information related to the undesirable variables. We study three scenarios, each with a different type of undesirable variables: task-irrelevant meta-information for self-supervised speech representation learning, sensitive attributes for fair representation learning, and domain specification for multi-domain visual representation learning.
A Note on Connecting Barlow Twins with Negative-Sample-Free Contrastive Learning
Apr 28, 2021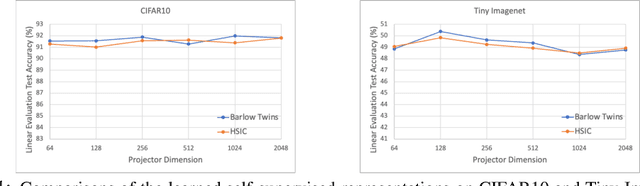
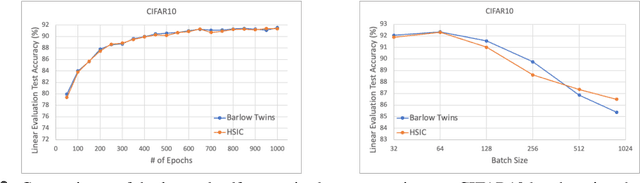
In this report, we relate the algorithmic design of Barlow Twins' method to the Hilbert-Schmidt Independence Criterion (HSIC), thus establishing it as a contrastive learning approach that is free of negative samples. Through this perspective, we argue that Barlow Twins (and thus the class of negative-sample-free contrastive learning methods) suggests a possibility to bridge the two major families of self-supervised learning philosophies: non-contrastive and contrastive approaches. In particular, Barlow twins exemplified how we could combine the best practices of both worlds: avoiding the need of large training batch size and negative sample pairing (like non-contrastive methods) and avoiding symmetry-breaking network designs (like contrastive methods).