 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
Feb 16, 2018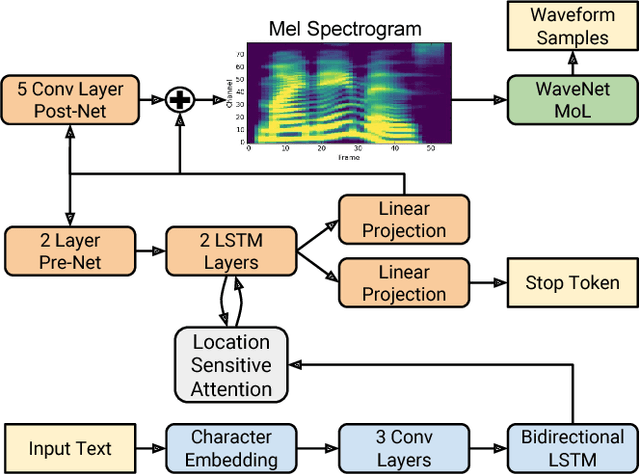

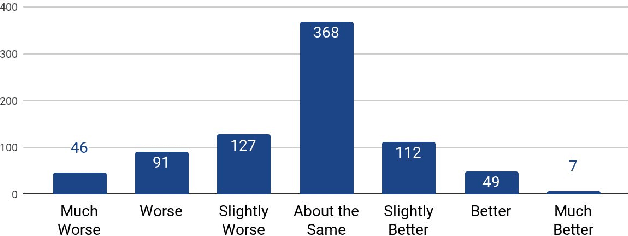
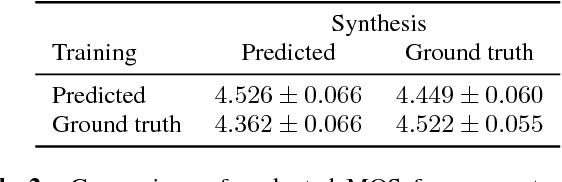
This paper describes Tacotron 2, a neural network architecture for speech synthesis directly from text. The system is composed of a recurrent sequence-to-sequence feature prediction network that maps character embeddings to mel-scale spectrograms, followed by a modified WaveNet model acting as a vocoder to synthesize timedomain waveforms from those spectrograms. Our model achieves a mean opinion score (MOS) of $4.53$ comparable to a MOS of $4.58$ for professionally recorded speech. To validate our design choices, we present ablation studies of key components of our system and evaluate the impact of using mel spectrograms as the input to WaveNet instead of linguistic, duration, and $F_0$ features. We further demonstrate that using a compact acoustic intermediate representation enables significant simplification of the WaveNet architecture.
Tacotron: Towards End-to-End Speech Synthesis
Apr 06, 2017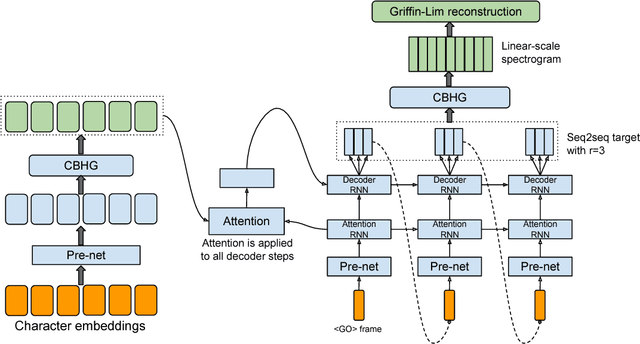
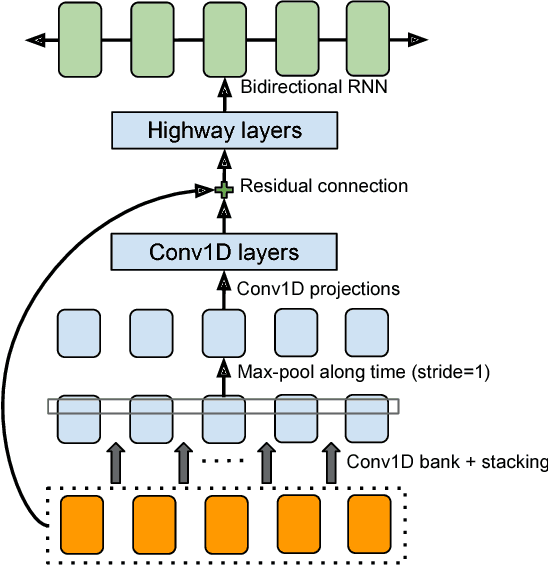
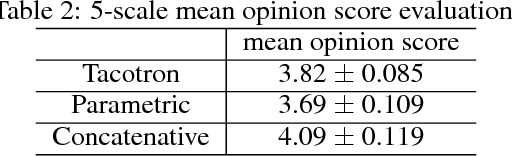
A text-to-speech synthesis system typically consists of multiple stages, such as a text analysis frontend, an acoustic model and an audio synthesis module. Building these components often requires extensive domain expertise and may contain brittle design choices. In this paper, we present Tacotron, an end-to-end generative text-to-speech model that synthesizes speech directly from characters. Given <text, audio> pairs, the model can be trained completely from scratch with random initialization. We present several key techniques to make the sequence-to-sequence framework perform well for this challenging task. Tacotron achieves a 3.82 subjective 5-scale mean opinion score on US English, outperforming a production parametric system in terms of naturalness. In addition, since Tacotron generates speech at the frame level, it's substantially faster than sample-level autoregressive methods.
AutoMOS: Learning a non-intrusive assessor of naturalness-of-speech
Nov 28, 2016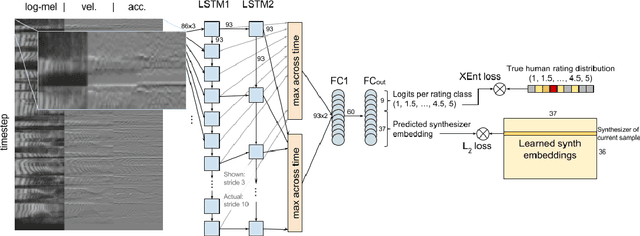
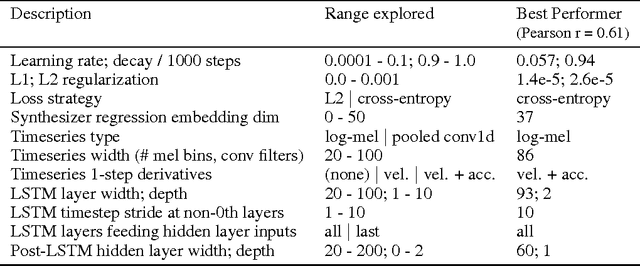
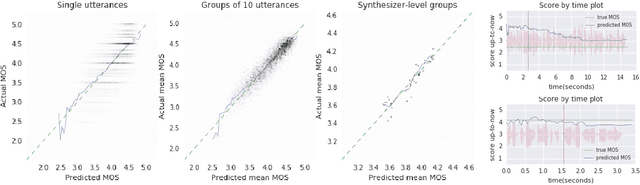
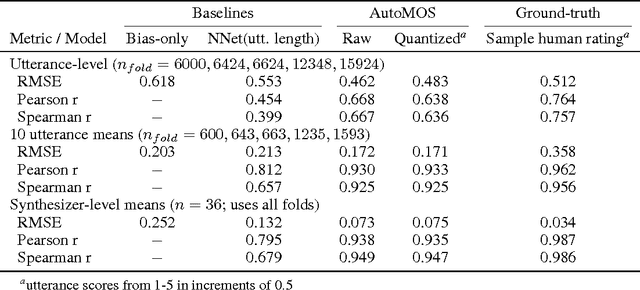
Developers of text-to-speech synthesizers (TTS) often make use of human raters to assess the quality of synthesized speech. We demonstrate that we can model human raters' mean opinion scores (MOS) of synthesized speech using a deep recurrent neural network whose inputs consist solely of a raw waveform. Our best models provide utterance-level estimates of MOS only moderately inferior to sampled human ratings, as shown by Pearson and Spearman correlations. When multiple utterances are scored and averaged, a scenario common in synthesizer quality assessment, AutoMOS achieves correlations approaching those of human raters. The AutoMOS model has a number of applications, such as the ability to explore the parameter space of a speech synthesizer without requiring a human-in-the-loop.
Fast, Compact, and High Quality LSTM-RNN Based Statistical Parametric Speech Synthesizers for Mobile Devices
Jun 22, 2016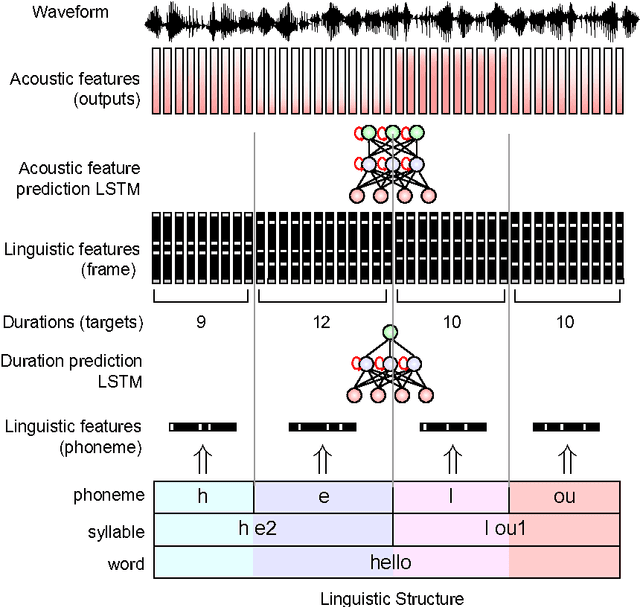
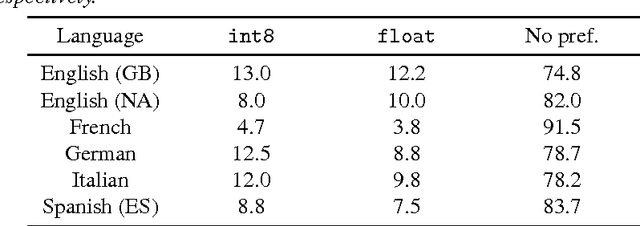
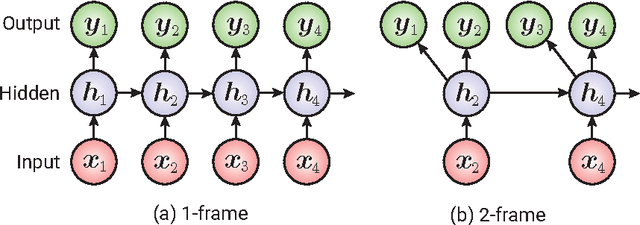
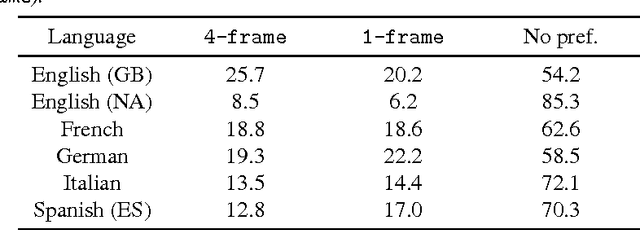
Acoustic models based on long short-term memory recurrent neural networks (LSTM-RNNs) were applied to statistical parametric speech synthesis (SPSS) and showed significant improvements in naturalness and latency over those based on hidden Markov models (HMMs). This paper describes further optimizations of LSTM-RNN-based SPSS for deployment on mobile devices; weight quantization, multi-frame inference, and robust inference using an {\epsilon}-contaminated Gaussian loss function. Experimental results in subjective listening tests show that these optimizations can make LSTM-RNN-based SPSS comparable to HMM-based SPSS in runtime speed while maintaining naturalness. Evaluations between LSTM-RNN- based SPSS and HMM-driven unit selection speech synthesis are also presented.