 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Stationary Time Series Forecasting Based on Fourier Analysis and Cross Attention Mechanism
May 11, 2025Time series forecasting has important applications in financial analysis, weather forecasting, and traffic management. However, existing deep learning models are limited in processing non-stationary time series data because they cannot effectively capture the statistical characteristics that change over time. To address this problem, this paper proposes a new framework, AEFIN, which enhances the information sharing ability between stable and unstable components by introducing a cross-attention mechanism, and combines Fourier analysis networks with MLP to deeply explore the seasonal patterns and trend characteristics in unstable components. In addition, we design a new loss function that combines time-domain stability constraints, time-domain instability constraints, and frequency-domain stability constraints to improve the accuracy and robustness of forecasting. Experimental results show that AEFIN outperforms the most common models in terms of mean square error and mean absolute error, especially under non-stationary data conditions, and shows excellent forecasting capabilities. This paper provides an innovative solution for the modeling and forecasting of non-stationary time series data, and contributes to the research of deep learning for complex time series.
Multi-Weather Image Restoration via Histogram-Based Transformer Feature Enhancement
Sep 10, 2024



Currently, the mainstream restoration tasks under adverse weather conditions have predominantly focused on single-weather scenarios. However, in reality, multiple weather conditions always coexist and their degree of mixing is usually unknown. Under such complex and diverse weather conditions, single-weather restoration models struggle to meet practical demands. This is particularly critical in fields such as autonomous driving, where there is an urgent need for a model capable of effectively handling mixed weather conditions and enhancing image quality in an automated manner. In this paper, we propose a Task Sequence Generator module that, in conjunction with the Task Intra-patch Block, effectively extracts task-specific features embedded in degraded images. The Task Intra-patch Block introduces an external learnable sequence that aids the network in capturing task-specific information. Additionally, we employ a histogram-based transformer module as the backbone of our network, enabling the capture of both global and local dynamic range features. Our proposed model achieves state-of-the-art performance on public datasets.
Multiple weather images restoration using the task transformer and adaptive mixup strategy
Sep 05, 2024



The current state-of-the-art in severe weather removal predominantly focuses on single-task applications, such as rain removal, haze removal, and snow removal. However, real-world weather conditions often consist of a mixture of several weather types, and the degree of weather mixing in autonomous driving scenarios remains unknown. In the presence of complex and diverse weather conditions, a single weather removal model often encounters challenges in producing clear images from severe weather images. Therefore, there is a need for the development of multi-task severe weather removal models that can effectively handle mixed weather conditions and improve image quality in autonomous driving scenarios. In this paper, we introduce a novel multi-task severe weather removal model that can effectively handle complex weather conditions in an adaptive manner. Our model incorporates a weather task sequence generator, enabling the self-attention mechanism to selectively focus on features specific to different weather types. To tackle the challenge of repairing large areas of weather degradation, we introduce Fast Fourier Convolution (FFC) to increase the receptive field. Additionally, we propose an adaptive upsampling technique that effectively processes both the weather task information and underlying image features by selectively retaining relevant information. Our proposed model has achieved state-of-the-art performance on the publicly available dataset.
ViewFormer: Exploring Spatiotemporal Modeling for Multi-View 3D Occupancy Perception via View-Guided Transformers
May 07, 2024



3D occupancy, an advanced perception technology for driving scenarios, represents the entire scene without distinguishing between foreground and background by quantifying the physical space into a grid map. The widely adopted projection-first deformable attention, efficient in transforming image features into 3D representations, encounters challenges in aggregating multi-view features due to sensor deployment constraints. To address this issue, we propose our learning-first view attention mechanism for effective multi-view feature aggregation. Moreover, we showcase the scalability of our view attention across diverse multi-view 3D tasks, such as map construction and 3D object detection. Leveraging the proposed view attention as well as an additional multi-frame streaming temporal attention, we introduce ViewFormer, a vision-centric transformer-based framework for spatiotemporal feature aggregation. To further explore occupancy-level flow representation, we present FlowOcc3D, a benchmark built on top of existing high-quality datasets. Qualitative and quantitative analyses on this benchmark reveal the potential to represent fine-grained dynamic scenes. Extensive experiments show that our approach significantly outperforms prior state-of-the-art methods. The codes and benchmark will be released soon.
DriveMLM: Aligning Multi-Modal Large Language Models with Behavioral Planning States for Autonomous Driving
Dec 25, 2023



Large language models (LLMs) have opened up new possibilities for intelligent agents, endowing them with human-like thinking and cognitive abilities. In this work, we delve into the potential of large language models (LLMs) in autonomous driving (AD). We introduce DriveMLM, an LLM-based AD framework that can perform close-loop autonomous driving in realistic simulators. To this end, (1) we bridge the gap between the language decisions and the vehicle control commands by standardizing the decision states according to the off-the-shelf motion planning module. (2) We employ a multi-modal LLM (MLLM) to model the behavior planning module of a module AD system, which uses driving rules, user commands, and inputs from various sensors (e.g., camera, lidar) as input and makes driving decisions and provide explanations; This model can plug-and-play in existing AD systems such as Apollo for close-loop driving. (3) We design an effective data engine to collect a dataset that includes decision state and corresponding explanation annotation for model training and evaluation. We conduct extensive experiments and show that our model achieves 76.1 driving score on the CARLA Town05 Long, and surpasses the Apollo baseline by 4.7 points under the same settings, demonstrating the effectiveness of our model. We hope this work can serve as a baseline for autonomous driving with LLMs. Code and models shall be released at https://github.com/OpenGVLab/DriveMLM.
Deep Dynamic Epidemiological Modelling for COVID-19 Forecasting in Multi-level Districts
Jun 21, 2023



Objective: COVID-19 has spread worldwide and made a huge influence across the world. Modeling the infectious spread situation of COVID-19 is essential to understand the current condition and to formulate intervention measurements. Epidemiological equations based on the SEIR model simulate disease development. The traditional parameter estimation method to solve SEIR equations could not precisely fit real-world data due to different situations, such as social distancing policies and intervention strategies. Additionally, learning-based models achieve outstanding fitting performance, but cannot visualize mechanisms. Methods: Thus, we propose a deep dynamic epidemiological (DDE) method that combines epidemiological equations and deep-learning advantages to obtain high accuracy and visualization. The DDE contains deep networks to fit the effect function to simulate the ever-changing situations based on the neural ODE method in solving variants' equations, ensuring the fitting performance of multi-level areas. Results: We introduce four SEIR variants to fit different situations in different countries and regions. We compare our DDE method with traditional parameter estimation methods (Nelder-Mead, BFGS, Powell, Truncated Newton Conjugate-Gradient, Neural ODE) in fitting the real-world data in the cases of countries (the USA, Columbia, South Africa) and regions (Wuhan in China, Piedmont in Italy). Our DDE method achieves the best Mean Square Error and Pearson coefficient in all five areas. Further, compared with the state-of-art learning-based approaches, the DDE outperforms all techniques, including LSTM, RNN, GRU, Random Forest, Extremely Random Trees, and Decision Tree. Conclusion: DDE presents outstanding predictive ability and visualized display of the changes in infection rates in different regions and countries.
Rethinking Vision Transformers for MobileNet Size and Speed
Dec 15, 2022



With the success of Vision Transformers (ViTs) in computer vision tasks, recent arts try to optimize the performance and complexity of ViTs to enable efficient deployment on mobile devices. Multiple approaches are proposed to accelerate attention mechanism, improve inefficient designs, or incorporate mobile-friendly lightweight convolutions to form hybrid architectures. However, ViT and its variants still have higher latency or considerably more parameters than lightweight CNNs, even true for the years-old MobileNet. In practice, latency and size are both crucial for efficient deployment on resource-constraint hardware. In this work, we investigate a central question, can transformer models run as fast as MobileNet and maintain a similar size? We revisit the design choices of ViTs and propose an improved supernet with low latency and high parameter efficiency. We further introduce a fine-grained joint search strategy that can find efficient architectures by optimizing latency and number of parameters simultaneously. The proposed models, EfficientFormerV2, achieve about $4\%$ higher top-1 accuracy than MobileNetV2 and MobileNetV2$\times1.4$ on ImageNet-1K with similar latency and parameters. We demonstrate that properly designed and optimized vision transformers can achieve high performance with MobileNet-level size and speed.
EfficientFormer: Vision Transformers at MobileNet Speed
Jun 02, 2022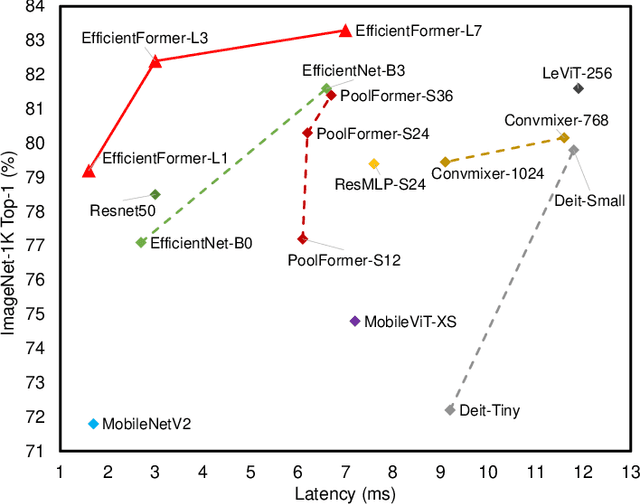
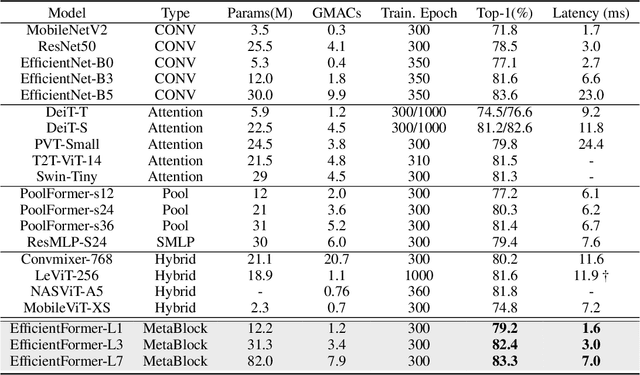
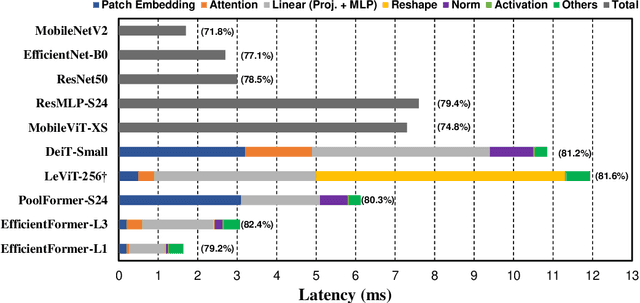
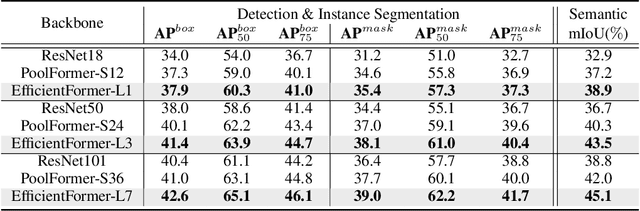
Vision Transformers (ViT) have shown rapid progress in computer vision tasks, achieving promising results on various benchmarks. However, due to the massive number of parameters and model design, e.g., attention mechanism, ViT-based models are generally times slower than lightweight convolutional networks. Therefore, the deployment of ViT for real-time applications is particularly challenging, especially on resource-constrained hardware such as mobile devices. Recent efforts try to reduce the computation complexity of ViT through network architecture search or hybrid design with MobileNet block, yet the inference speed is still unsatisfactory. This leads to an important question: can transformers run as fast as MobileNet while obtaining high performance? To answer this, we first revisit the network architecture and operators used in ViT-based models and identify inefficient designs. Then we introduce a dimension-consistent pure transformer (without MobileNet blocks) as design paradigm. Finally, we perform latency-driven slimming to get a series of final models dubbed EfficientFormer. Extensive experiments show the superiority of EfficientFormer in performance and speed on mobile devices. Our fastest model, EfficientFormer-L1, achieves 79.2% top-1 accuracy on ImageNet-1K with only 1.6 ms inference latency on iPhone 12 (compiled with CoreML), which is even a bit faster than MobileNetV2 (1.7 ms, 71.8% top-1), and our largest model, EfficientFormer-L7, obtains 83.3% accuracy with only 7.0 ms latency. Our work proves that properly designed transformers can reach extremely low latency on mobile devices while maintaining high performance
Panoptic-PHNet: Towards Real-Time and High-Precision LiDAR Panoptic Segmentation via Clustering Pseudo Heatmap
May 14, 2022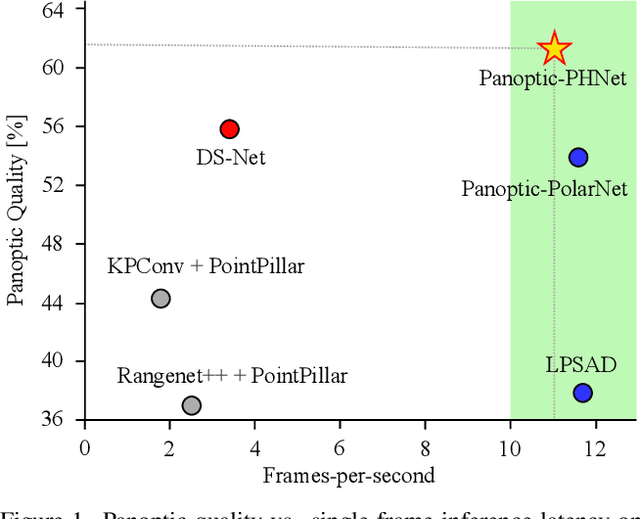
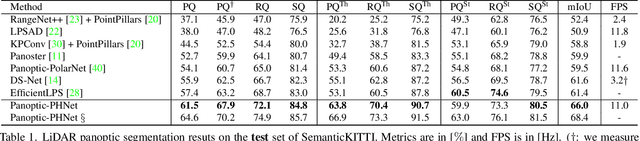
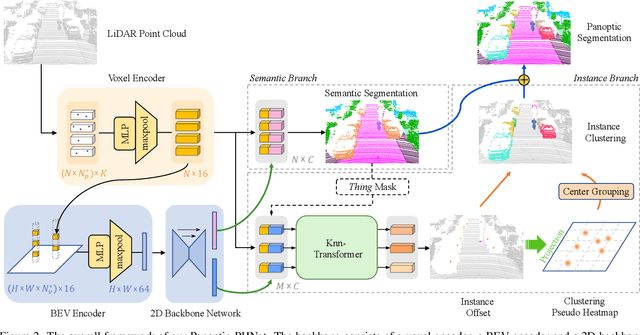
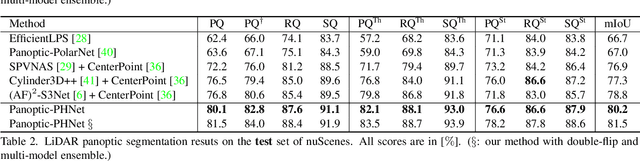
As a rising task, panoptic segmentation is faced with challenges in both semantic segmentation and instance segmentation. However, in terms of speed and accuracy, existing LiDAR methods in the field are still limited. In this paper, we propose a fast and high-performance LiDAR-based framework, referred to as Panoptic-PHNet, with three attractive aspects: 1) We introduce a clustering pseudo heatmap as a new paradigm, which, followed by a center grouping module, yields instance centers for efficient clustering without object-level learning tasks. 2) A knn-transformer module is proposed to model the interaction among foreground points for accurate offset regression. 3) For backbone design, we fuse the fine-grained voxel features and the 2D Bird's Eye View (BEV) features with different receptive fields to utilize both detailed and global information. Extensive experiments on both SemanticKITTI dataset and nuScenes dataset show that our Panoptic-PHNet surpasses state-of-the-art methods by remarkable margins with a real-time speed. We achieve the 1st place on the public leaderboard of SemanticKITTI and leading performance on the recently released leaderboard of nuScenes.
Medical Datasets Collections for Artificial Intelligence-based Medical Image Analysis
Feb 18, 2021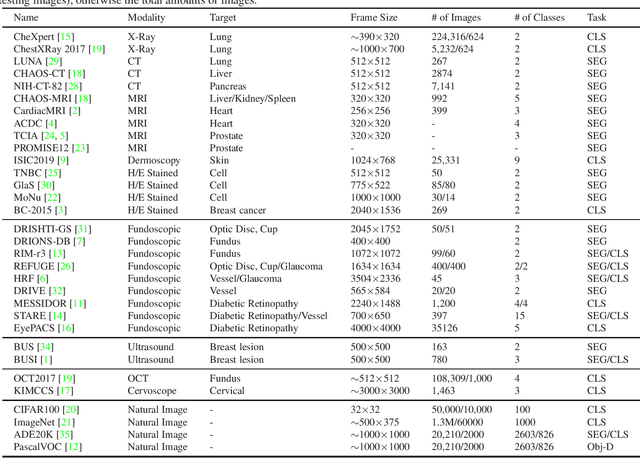
We collected 32 public datasets, of which 28 for medical imaging and 4 for natural images, to conduct study. The images of these datasets are captured by different cameras, thus vary from each other in modality, frame size and capacity. For data accessibility, we also provide the websites of most datasets and hope this will help the readers reach the datasets.