 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSVG: A Unified Dataset for Vector Graphic Understanding and Generation with Multimodal Large Language Models
Aug 11, 2025Unlike bitmap images, scalable vector graphics (SVG) maintain quality when scaled, frequently employed in computer vision and artistic design in the representation of SVG code. In this era of proliferating AI-powered systems, enabling AI to understand and generate SVG has become increasingly urgent. However, AI-driven SVG understanding and generation (U&G) remain significant challenges. SVG code, equivalent to a set of curves and lines controlled by floating-point parameters, demands high precision in SVG U&G. Besides, SVG generation operates under diverse conditional constraints, including textual prompts and visual references, which requires powerful multi-modal processing for condition-to-SVG transformation. Recently, the rapid growth of Multi-modal Large Language Models (MLLMs) have demonstrated capabilities to process multi-modal inputs and generate complex vector controlling parameters, suggesting the potential to address SVG U&G tasks within a unified model. To unlock MLLM's capabilities in the SVG area, we propose an SVG-centric dataset called UniSVG, comprising 525k data items, tailored for MLLM training and evaluation. To our best knowledge, it is the first comprehensive dataset designed for unified SVG generation (from textual prompts and images) and SVG understanding (color, category, usage, etc.). As expected, learning on the proposed dataset boosts open-source MLLMs' performance on various SVG U&G tasks, surpassing SOTA close-source MLLMs like GPT-4V. We release dataset, benchmark, weights, codes and experiment details on https://ryanlijinke.github.io/.
A High-Performance Thermal Infrared Object Detection Framework with Centralized Regulation
May 16, 2025Thermal Infrared (TIR) technology involves the use of sensors to detect and measure infrared radiation emitted by objects, and it is widely utilized across a broad spectrum of applications. The advancements in object detection methods utilizing TIR images have sparked significant research interest. However, most traditional methods lack the capability to effectively extract and fuse local-global information, which is crucial for TIR-domain feature attention. In this study, we present a novel and efficient thermal infrared object detection framework, known as CRT-YOLO, that is based on centralized feature regulation, enabling the establishment of global-range interaction on TIR information. Our proposed model integrates efficient multi-scale attention (EMA) modules, which adeptly capture long-range dependencies while incurring minimal computational overhead. Additionally, it leverages the Centralized Feature Pyramid (CFP) network, which offers global regulation of TIR features. Extensive experiments conducted on two benchmark datasets demonstrate that our CRT-YOLO model significantly outperforms conventional methods for TIR image object detection. Furthermore, the ablation study provides compelling evidence of the effectiveness of our proposed modules, reinforcing the potential impact of our approach on advancing the field of thermal infrared object detection.
* This manuscript has been accepted for publication in the International Journal for Housing Science and Its Applications (IJHSA), 2025
Spatio-Temporal Electromagnetic Kernel Learning for Channel Prediction
Dec 23, 2024



Accurate channel prediction is essential for addressing channel aging caused by user mobility. However, the actual channel variations over time are highly complex in high-mobility scenarios, which makes it difficult for existing predictors to obtain future channels accurately. The low accuracy of channel predictors leads to difficulties in supporting reliable communication. To overcome this challenge, we propose a channel predictor based on spatio-temporal electromagnetic (EM) kernel learning (STEM-KL). Specifically, inspired by recent advancements in EM information theory (EIT), the STEM kernel function is derived. The velocity and the concentration kernel parameters are designed to reflect the time-varying propagation of the wireless signal. We obtain the parameters through kernel learning. Then, the future channels are predicted by computing their Bayesian posterior, with the STEM kernel acting as the prior. To further improve the stability and model expressibility, we propose a grid-based EM mixed kernel learning (GEM-KL) scheme. We design the mixed kernel to be a convex combination of multiple sub-kernels, where each of the sub-kernel corresponds to a grid point in the set of pre-selected parameters. This approach transforms non-convex STEM kernel learning problem into a convex grid-based problem that can be easily solved by weight optimization. Finally, simulation results verify that the proposed STEM-KL and GEM-KL schemes can achieve more accurate channel prediction. This indicates that EIT can improve the performance of wireless system efficiently.
Exploring Fungal Morphology Simulation and Dynamic Light Containment from a Graphics Generation Perspective
Sep 08, 2024



Fungal simulation and control are considered crucial techniques in Bio-Art creation. However, coding algorithms for reliable fungal simulations have posed significant challenges for artists. This study equates fungal morphology simulation to a two-dimensional graphic time-series generation problem. We propose a zero-coding, neural network-driven cellular automaton. Fungal spread patterns are learned through an image segmentation model and a time-series prediction model, which then supervise the training of neural network cells, enabling them to replicate real-world spreading behaviors. We further implemented dynamic containment of fungal boundaries with lasers. Synchronized with the automaton, the fungus successfully spreads into pre-designed complex shapes in reality.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024



In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
ViewFormer: Exploring Spatiotemporal Modeling for Multi-View 3D Occupancy Perception via View-Guided Transformers
May 07, 2024



3D occupancy, an advanced perception technology for driving scenarios, represents the entire scene without distinguishing between foreground and background by quantifying the physical space into a grid map. The widely adopted projection-first deformable attention, efficient in transforming image features into 3D representations, encounters challenges in aggregating multi-view features due to sensor deployment constraints. To address this issue, we propose our learning-first view attention mechanism for effective multi-view feature aggregation. Moreover, we showcase the scalability of our view attention across diverse multi-view 3D tasks, such as map construction and 3D object detection. Leveraging the proposed view attention as well as an additional multi-frame streaming temporal attention, we introduce ViewFormer, a vision-centric transformer-based framework for spatiotemporal feature aggregation. To further explore occupancy-level flow representation, we present FlowOcc3D, a benchmark built on top of existing high-quality datasets. Qualitative and quantitative analyses on this benchmark reveal the potential to represent fine-grained dynamic scenes. Extensive experiments show that our approach significantly outperforms prior state-of-the-art methods. The codes and benchmark will be released soon.
A unified multichannel far-field speech recognition system: combining neural beamforming with attention based end-to-end model
Jan 05, 2024Far-field speech recognition is a challenging task that conventionally uses signal processing beamforming to attack noise and interference problem. But the performance has been found usually limited due to heavy reliance on environmental assumption. In this paper, we propose a unified multichannel far-field speech recognition system that combines the neural beamforming and transformer-based Listen, Spell, Attend (LAS) speech recognition system, which extends the end-to-end speech recognition system further to include speech enhancement. Such framework is then jointly trained to optimize the final objective of interest. Specifically, factored complex linear projection (fCLP) has been adopted to form the neural beamforming. Several pooling strategies to combine look directions are then compared in order to find the optimal approach. Moreover, information of the source direction is also integrated in the beamforming to explore the usefulness of source direction as a prior, which is usually available especially in multi-modality scenario. Experiments on different microphone array geometry are conducted to evaluate the robustness against spacing variance of microphone array. Large in-house databases are used to evaluate the effectiveness of the proposed framework and the proposed method achieve 19.26\% improvement when compared with a strong baseline.
Panoptic-PHNet: Towards Real-Time and High-Precision LiDAR Panoptic Segmentation via Clustering Pseudo Heatmap
May 14, 2022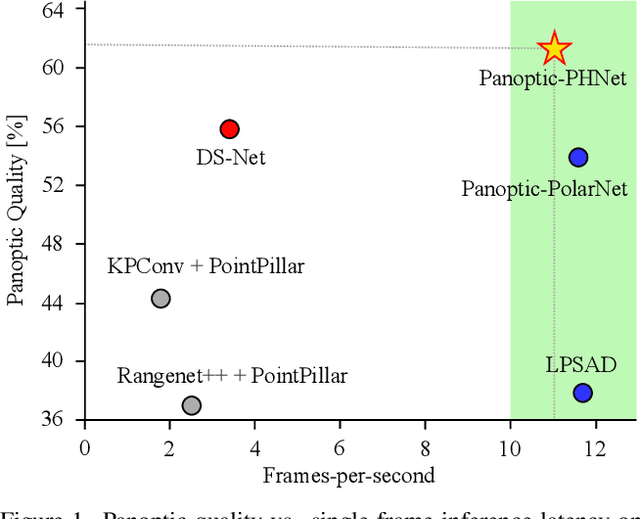
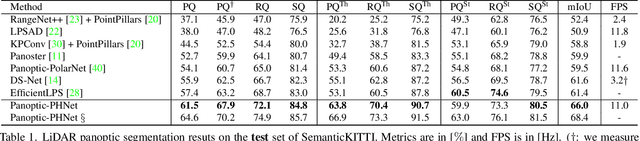
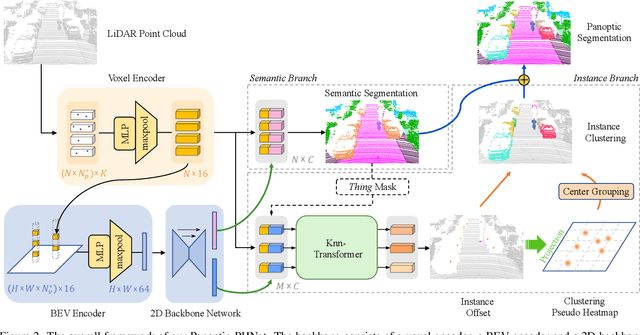
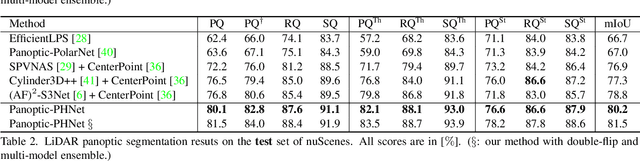
As a rising task, panoptic segmentation is faced with challenges in both semantic segmentation and instance segmentation. However, in terms of speed and accuracy, existing LiDAR methods in the field are still limited. In this paper, we propose a fast and high-performance LiDAR-based framework, referred to as Panoptic-PHNet, with three attractive aspects: 1) We introduce a clustering pseudo heatmap as a new paradigm, which, followed by a center grouping module, yields instance centers for efficient clustering without object-level learning tasks. 2) A knn-transformer module is proposed to model the interaction among foreground points for accurate offset regression. 3) For backbone design, we fuse the fine-grained voxel features and the 2D Bird's Eye View (BEV) features with different receptive fields to utilize both detailed and global information. Extensive experiments on both SemanticKITTI dataset and nuScenes dataset show that our Panoptic-PHNet surpasses state-of-the-art methods by remarkable margins with a real-time speed. We achieve the 1st place on the public leaderboard of SemanticKITTI and leading performance on the recently released leaderboard of nuScenes.