 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safe Mobility: A Unified Transportation Foundation Model enabled by Open-Ended Vision-Language Dataset
Apr 24, 2026Urban transportation systems face growing safety challenges that require scalable intelligence for emerging smart mobility infrastructures. While recent advances in foundation models and large-scale multimodal datasets have strengthened perception and reasoning in intelligent transportation systems (ITS), existing research remains largely centered on microscopic autonomous driving (AD), with limited attention to city-scale traffic analysis. In particular, open-ended safety-oriented visual question answering (VQA) and corresponding foundation models for reasoning over heterogeneous roadside camera observations remain underexplored. To address this gap, we introduce the Land Transportation Dataset (LTD), a large-scale open-source vision-language dataset for open-ended reasoning in urban traffic environments. LTD contains 11.6K high-quality VQA pairs collected from heterogeneous roadside cameras, spanning diverse road geometries, traffic participants, illumination conditions, and adverse weather. The dataset integrates three complementary tasks: fine-grained multi-object grounding, multi-image camera selection, and multi-image risk analysis, requiring joint reasoning over minimally correlated views to infer hazardous objects, contributing factors, and risky road directions. To ensure annotation fidelity, we combine multi-model vision-language generation with cross-validation and human-in-the-loop refinement. Building upon LTD, we further propose UniVLT, a transportation foundation model trained via curriculum-based knowledge transfer to unify microscopic AD reasoning and macroscopic traffic analysis within a single architecture. Extensive experiments on LTD and multiple AD benchmarks demonstrate that UniVLT achieves SOTA performance on open-ended reasoning tasks across diverse domains, while exposing limitations of existing foundation models in complex multi-view traffic scenarios.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Multimodal Semi-Supervised Learning for 3D Objects
Oct 25, 2021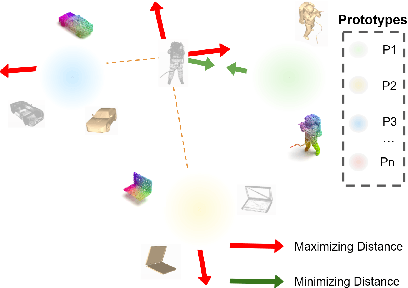
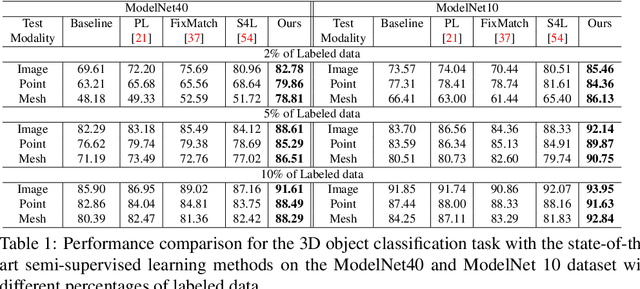
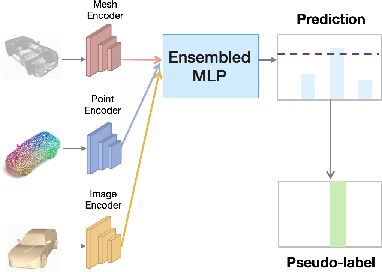
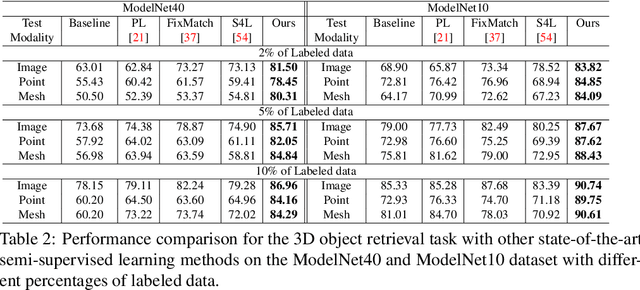
In recent years, semi-supervised learning has been widely explored and shows excellent data efficiency for 2D data. There is an emerging need to improve data efficiency for 3D tasks due to the scarcity of labeled 3D data. This paper explores how the coherence of different modelities of 3D data (e.g. point cloud, image, and mesh) can be used to improve data efficiency for both 3D classification and retrieval tasks. We propose a novel multimodal semi-supervised learning framework by introducing instance-level consistency constraint and a novel multimodal contrastive prototype (M2CP) loss. The instance-level consistency enforces the network to generate consistent representations for multimodal data of the same object regardless of its modality. The M2CP maintains a multimodal prototype for each class and learns features with small intra-class variations by minimizing the feature distance of each object to its prototype while maximizing the distance to the others. Our proposed framework significantly outperforms all the state-of-the-art counterparts for both classification and retrieval tasks by a large margin on the modelNet10 and ModelNet40 datasets.