 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming CLIP to an Open-vocabulary Video Model via Interpolated Weight Optimization
Feb 01, 2023



Contrastive Language-Image Pretraining (CLIP) has demonstrated impressive zero-shot learning abilities for image understanding, yet limited effort has been made to investigate CLIP for zero-shot video recognition. We introduce Open-VCLIP, a simple yet effective approach that transforms CLIP into strong zero-shot video classifiers that can recognize unseen actions and events at test time. Our framework extends CLIP with minimal modifications to model spatial-temporal relationships in videos, making it a specialized video classifier, while striving for generalization. We formally show that training an Open-VCLIP is equivalent to continual learning with zero historical data. To address this problem, we propose Interpolated Weight Optimization, which utilizes the benefit of weight interpolation in both training and test time. We evaluate our method on three popular and challenging action recognition datasets following various zero-shot evaluation protocols and we demonstrate our approach outperforms state-of-the-art methods by clear margins. In particular, we achieve 87.9%, 58.3%, 81.1% zero-shot accuracy on UCF, HMDB and Kinetics-600 respectively, outperforming state-of-the-art methods by 8.3%, 7.8% and 12.2%.
Vision Transformers Are Good Mask Auto-Labelers
Jan 10, 2023We propose Mask Auto-Labeler (MAL), a high-quality Transformer-based mask auto-labeling framework for instance segmentation using only box annotations. MAL takes box-cropped images as inputs and conditionally generates their mask pseudo-labels.We show that Vision Transformers are good mask auto-labelers. Our method significantly reduces the gap between auto-labeling and human annotation regarding mask quality. Instance segmentation models trained using the MAL-generated masks can nearly match the performance of their fully-supervised counterparts, retaining up to 97.4\% performance of fully supervised models. The best model achieves 44.1\% mAP on COCO instance segmentation (test-dev 2017), outperforming state-of-the-art box-supervised methods by significant margins. Qualitative results indicate that masks produced by MAL are, in some cases, even better than human annotations.
ASM-Loc: Action-aware Segment Modeling for Weakly-Supervised Temporal Action Localization
Mar 29, 2022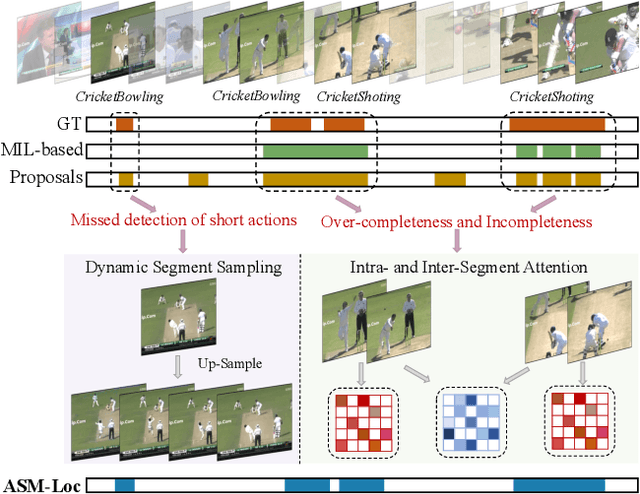

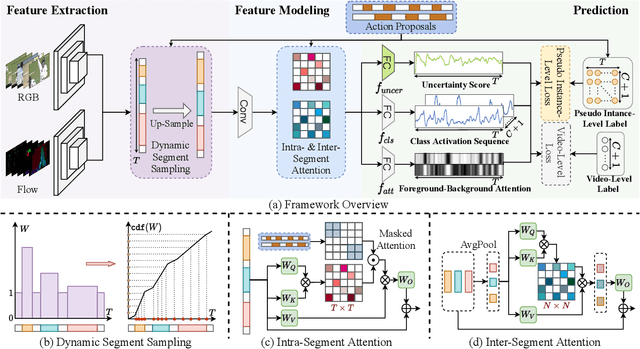

Weakly-supervised temporal action localization aims to recognize and localize action segments in untrimmed videos given only video-level action labels for training. Without the boundary information of action segments, existing methods mostly rely on multiple instance learning (MIL), where the predictions of unlabeled instances (i.e., video snippets) are supervised by classifying labeled bags (i.e., untrimmed videos). However, this formulation typically treats snippets in a video as independent instances, ignoring the underlying temporal structures within and across action segments. To address this problem, we propose \system, a novel WTAL framework that enables explicit, action-aware segment modeling beyond standard MIL-based methods. Our framework entails three segment-centric components: (i) dynamic segment sampling for compensating the contribution of short actions; (ii) intra- and inter-segment attention for modeling action dynamics and capturing temporal dependencies; (iii) pseudo instance-level supervision for improving action boundary prediction. Furthermore, a multi-step refinement strategy is proposed to progressively improve action proposals along the model training process. Extensive experiments on THUMOS-14 and ActivityNet-v1.3 demonstrate the effectiveness of our approach, establishing new state of the art on both datasets. The code and models are publicly available at~\url{https://github.com/boheumd/ASM-Loc}.
Efficient Video Transformers with Spatial-Temporal Token Selection
Nov 23, 2021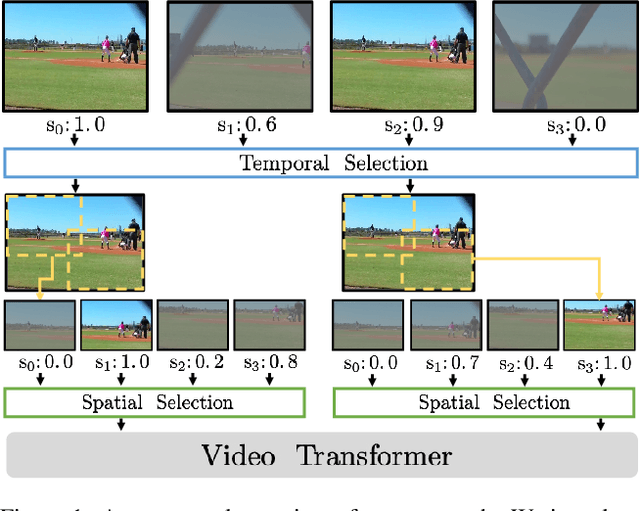
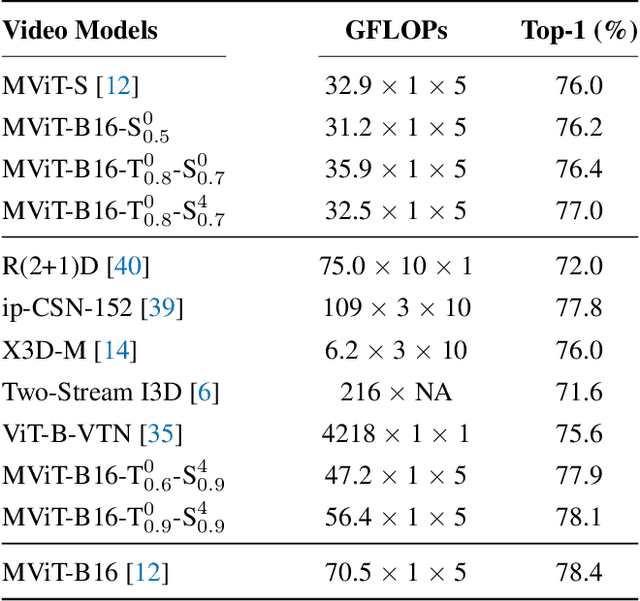
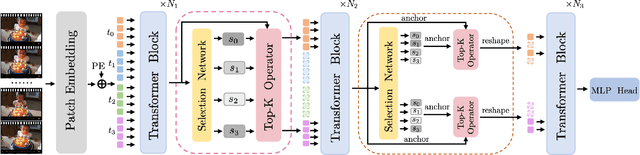
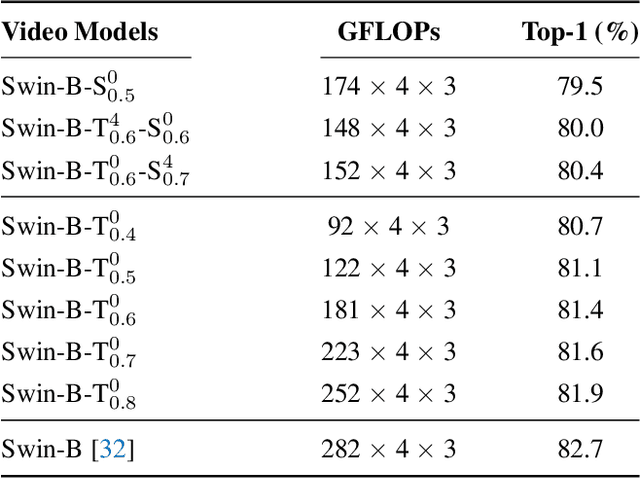
Video transformers have achieved impressive results on major video recognition benchmarks, however they suffer from high computational cost. In this paper, we present STTS, a token selection framework that dynamically selects a few informative tokens in both temporal and spatial dimensions conditioned on input video samples. Specifically, we formulate token selection as a ranking problem, which estimates the importance of each token through a lightweight selection network and only those with top scores will be used for downstream evaluation. In the temporal dimension, we keep the frames that are most relevant for recognizing action categories, while in the spatial dimension, we identify the most discriminative region in feature maps without affecting spatial context used in a hierarchical way in most video transformers. Since the decision of token selection is non-differentiable, we employ a perturbed-maximum based differentiable Top-K operator for end-to-end training. We conduct extensive experiments on Kinetics-400 with a recently introduced video transformer backbone, MViT. Our framework achieves similar results while requiring 20% less computation. We also demonstrate that our approach is compatible with other transformer architectures.
Semi-Supervised Vision Transformers
Nov 22, 2021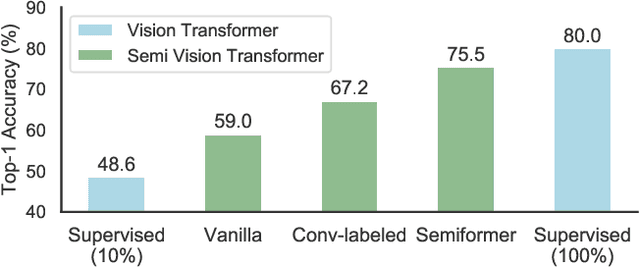

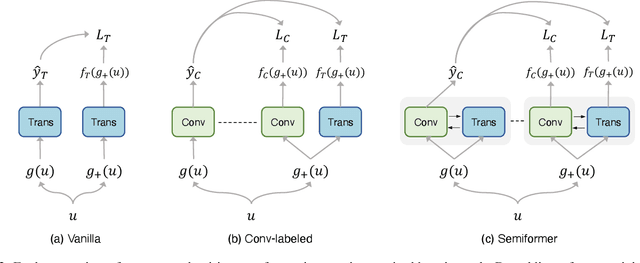

We study the training of Vision Transformers for semi-supervised image classification. Transformers have recently demonstrated impressive performance on a multitude of supervised learning tasks. Surprisingly, we find Vision Transformers perform poorly on a semi-supervised ImageNet setting. In contrast, Convolutional Neural Networks (CNNs) achieve superior results in small labeled data regime. Further investigation reveals that the reason is CNNs have strong spatial inductive bias. Inspired by this observation, we introduce a joint semi-supervised learning framework, Semiformer, which contains a Transformer branch, a Convolutional branch and a carefully designed fusion module for knowledge sharing between the branches. The Convolutional branch is trained on the limited supervised data and generates pseudo labels to supervise the training of the transformer branch on unlabeled data. Extensive experiments on ImageNet demonstrate that Semiformer achieves 75.5\% top-1 accuracy, outperforming the state-of-the-art. In addition, we show Semiformer is a general framework which is compatible with most modern Transformer and Convolutional neural architectures.
Beyond Short Clips: End-to-End Video-Level Learning with Collaborative Memories
Apr 02, 2021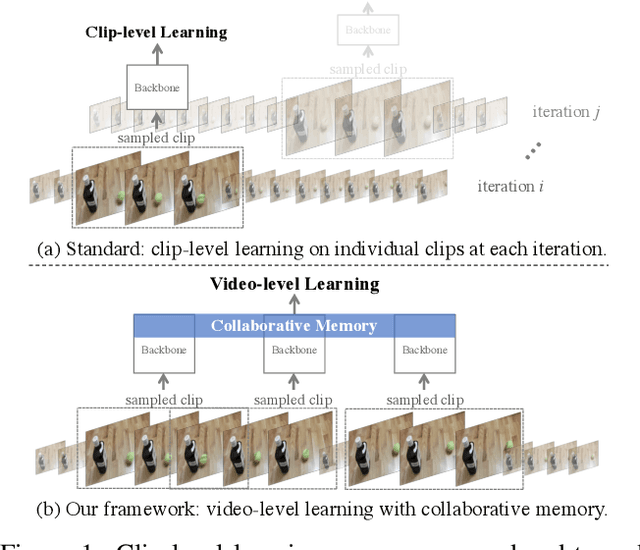
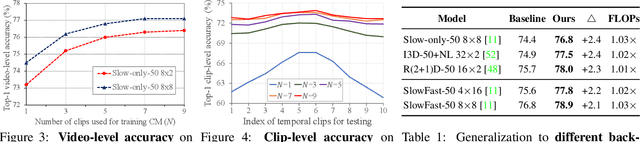
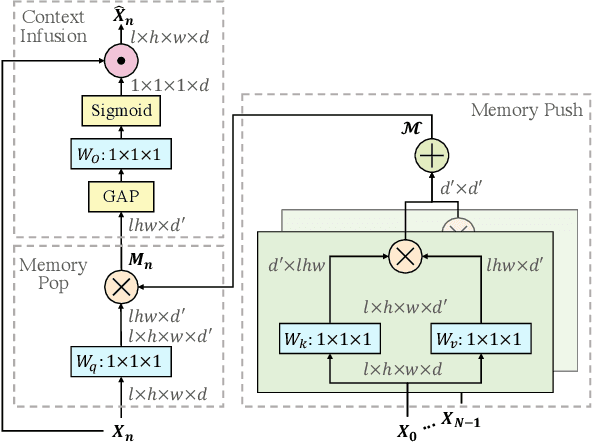
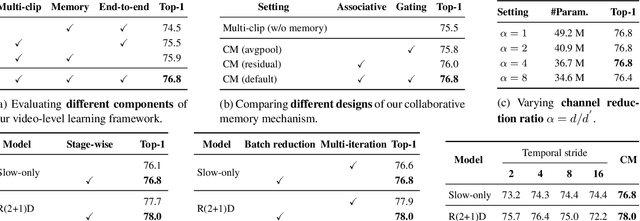
The standard way of training video models entails sampling at each iteration a single clip from a video and optimizing the clip prediction with respect to the video-level label. We argue that a single clip may not have enough temporal coverage to exhibit the label to recognize, since video datasets are often weakly labeled with categorical information but without dense temporal annotations. Furthermore, optimizing the model over brief clips impedes its ability to learn long-term temporal dependencies. To overcome these limitations, we introduce a collaborative memory mechanism that encodes information across multiple sampled clips of a video at each training iteration. This enables the learning of long-range dependencies beyond a single clip. We explore different design choices for the collaborative memory to ease the optimization difficulties. Our proposed framework is end-to-end trainable and significantly improves the accuracy of video classification at a negligible computational overhead. Through extensive experiments, we demonstrate that our framework generalizes to different video architectures and tasks, outperforming the state of the art on both action recognition (e.g., Kinetics-400 & 700, Charades, Something-Something-V1) and action detection (e.g., AVA v2.1 & v2.2).
GTA: Global Temporal Attention for Video Action Understanding
Dec 15, 2020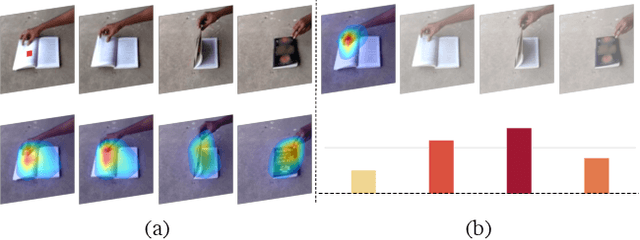
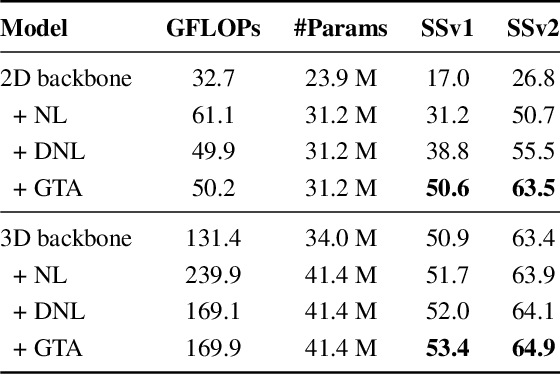
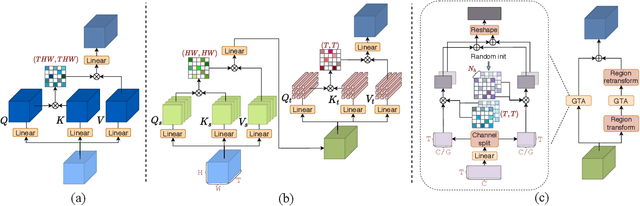
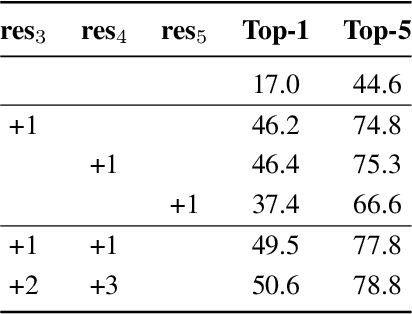
Self-attention learns pairwise interactions via dot products to model long-range dependencies, yielding great improvements for video action recognition. In this paper, we seek a deeper understanding of self-attention for temporal modeling in videos. In particular, we demonstrate that the entangled modeling of spatial-temporal information by flattening all pixels is sub-optimal, failing to capture temporal relationships among frames explicitly. We introduce Global Temporal Attention (GTA), which performs global temporal attention on top of spatial attention in a decoupled manner. Unlike conventional self-attention that computes an instance-specific attention matrix, GTA randomly initializes a global attention matrix that is intended to learn stable temporal structures to generalize across different samples. GTA is further augmented with a cross-channel multi-head fashion to exploit feature interactions for better temporal modeling. We apply GTA not only on pixels but also on semantically similar regions identified automatically by a learned transformation matrix. Extensive experiments on 2D and 3D networks demonstrate that our approach consistently enhances the temporal modeling and provides state-of-the-art performance on three video action recognition datasets.
Hierarchical Contrastive Motion Learning for Video Action Recognition
Jul 20, 2020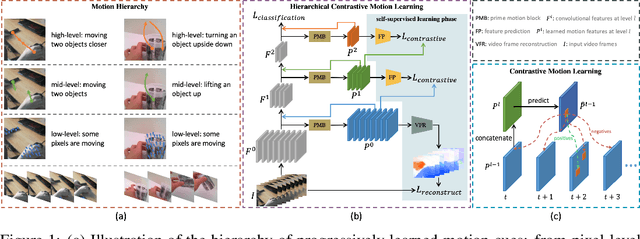
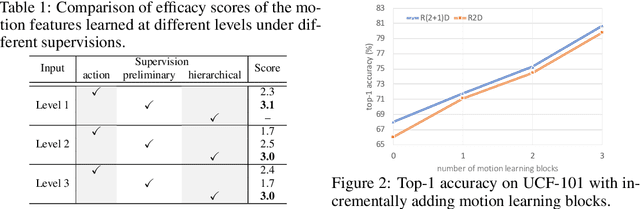
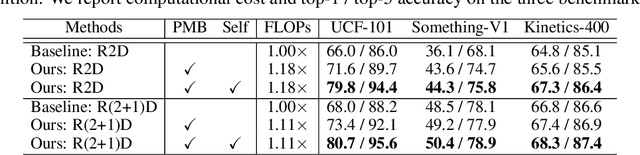

One central question for video action recognition is how to model motion. In this paper, we present hierarchical contrastive motion learning, a new self-supervised learning framework to extract effective motion representations from raw video frames. Our approach progressively learns a hierarchy of motion features that correspond to different abstraction levels in a network. This hierarchical design bridges the semantic gap between low-level motion cues and high-level recognition tasks, and promotes the fusion of appearance and motion information at multiple levels. At each level, an explicit motion self-supervision is provided via contrastive learning to enforce the motion features at the current level to predict the future ones at the previous level. Thus, the motion features at higher levels are trained to gradually capture semantic dynamics and evolve more discriminative for action recognition. Our motion learning module is lightweight and flexible to be embedded into various backbone networks. Extensive experiments on four benchmarks show that the proposed approach consistently achieves superior results.
A Generic Visualization Approach for Convolutional Neural Networks
Jul 19, 2020
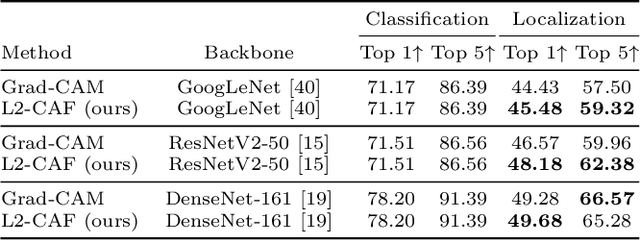

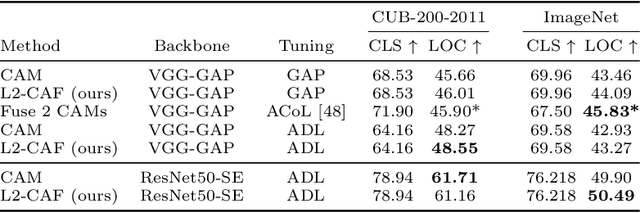
Retrieval networks are essential for searching and indexing. Compared to classification networks, attention visualization for retrieval networks is hardly studied. We formulate attention visualization as a constrained optimization problem. We leverage the unit L2-Norm constraint as an attention filter (L2-CAF) to localize attention in both classification and retrieval networks. Unlike recent literature, our approach requires neither architectural changes nor fine-tuning. Thus, a pre-trained network's performance is never undermined L2-CAF is quantitatively evaluated using weakly supervised object localization. State-of-the-art results are achieved on classification networks. For retrieval networks, significant improvement margins are achieved over a Grad-CAM baseline. Qualitative evaluation demonstrates how the L2-CAF visualizes attention per frame for a recurrent retrieval network. Further ablation studies highlight the computational cost of our approach and compare L2-CAF with other feasible alternatives. Code available at https://bit.ly/3iDBLFv
Cross-X Learning for Fine-Grained Visual Categorization
Sep 10, 2019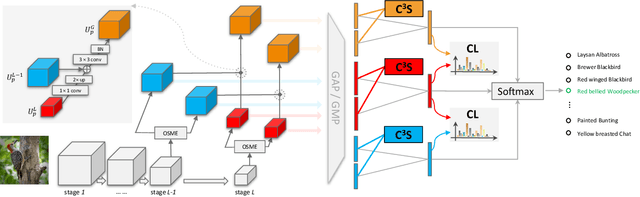
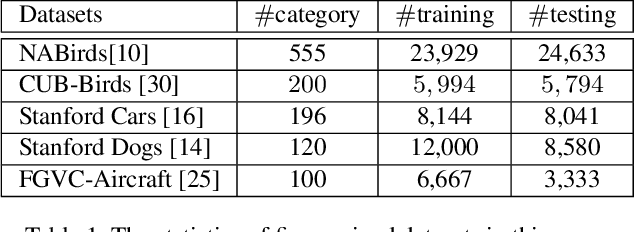
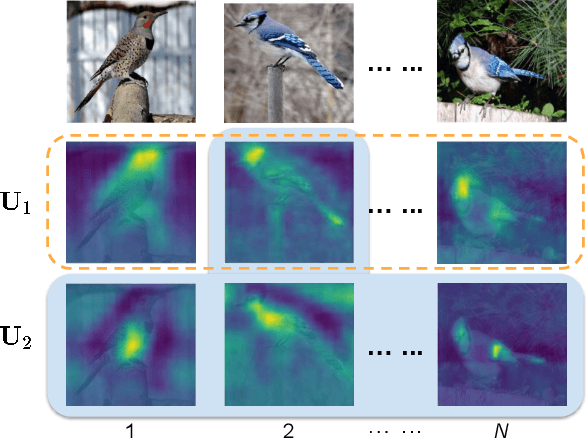
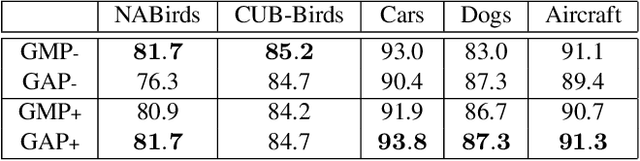
Recognizing objects from subcategories with very subtle differences remains a challenging task due to the large intra-class and small inter-class variation. Recent work tackles this problem in a weakly-supervised manner: object parts are first detected and the corresponding part-specific features are extracted for fine-grained classification. However, these methods typically treat the part-specific features of each image in isolation while neglecting their relationships between different images. In this paper, we propose Cross-X learning, a simple yet effective approach that exploits the relationships between different images and between different network layers for robust multi-scale feature learning. Our approach involves two novel components: (i) a cross-category cross-semantic regularizer that guides the extracted features to represent semantic parts and, (ii) a cross-layer regularizer that improves the robustness of multi-scale features by matching the prediction distribution across multiple layers. Our approach can be easily trained end-to-end and is scalable to large datasets like NABirds. We empirically analyze the contributions of different components of our approach and demonstrate its robustness, effectiveness and state-of-the-art performance on five benchmark datasets. Code is available at \url{https://github.com/cswluo/CrossX}.