 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Tool Makers
May 26, 2023Recent research shows the potential of enhancing the problem-solving ability of large language models (LLMs) through the use of external tools. However, prior work along this line depends on the availability of existing tools. In this work, we take an initial step towards removing this dependency by proposing a closed-loop framework, referred to as LLMs As Tool Makers (LATM), where LLMs create their own reusable tools for problem-solving. Our approach consists of two key phases: 1) tool making: an LLM acts as the tool maker that crafts tools for given tasks, where a tool is implemented as a Python utility function. 2) tool using: an LLM acts as the tool user, which applies the tool built by the tool maker for problem-solving. The tool user can be either the same or a different LLM from the tool maker. Tool-making enables an LLM to continually generate tools that can be applied to different requests so that future requests can call the corresponding APIs when beneficial for solving the tasks. Furthermore, the division of labor among LLMs for tool-making and tool-using phases introduces the opportunity to achieve cost effectiveness without degrading the quality of generated tools and problem solutions. For example, recognizing that tool-making demands more sophisticated capabilities than tool-using, we can apply a powerful yet resource-intensive model as the tool maker, and a lightweight while cost-effective model as the tool user. We validate the effectiveness of our approach across a variety of complex reasoning tasks, including Big-Bench tasks. With GPT-4 as the tool maker and GPT-3.5 as the tool user, LATM can achieve performance that is on par with using GPT-4 for both tool making and tool using, while the inference cost is significantly reduced.
Flan-MoE: Scaling Instruction-Finetuned Language Models with Sparse Mixture of Experts
May 24, 2023The explosive growth of language models and their applications have led to an increased demand for efficient and scalable methods. In this paper, we introduce Flan-MoE, a set of Instruction-Finetuned Sparse Mixture-of-Expert (MoE) models. We show that naively finetuning MoE models on a task-specific dataset (in other words, no instruction-finetuning) often yield worse performance compared to dense models of the same computational complexity. However, our Flan-MoE outperforms dense models under multiple experiment settings: instruction-finetuning only and instruction-finetuning followed by task-specific finetuning. This shows that instruction-finetuning is an essential stage for MoE models. Specifically, our largest model, Flan-MoE-32B, surpasses the performance of Flan-PaLM-62B on four benchmarks, while utilizing only one-third of the FLOPs. The success of Flan-MoE encourages rethinking the design of large-scale, high-performance language models, under the setting of task-agnostic learning.
Symbol tuning improves in-context learning in language models
May 15, 2023



We present symbol tuning - finetuning language models on in-context input-label pairs where natural language labels (e.g., "positive/negative sentiment") are replaced with arbitrary symbols (e.g., "foo/bar"). Symbol tuning leverages the intuition that when a model cannot use instructions or natural language labels to figure out a task, it must instead do so by learning the input-label mappings. We experiment with symbol tuning across Flan-PaLM models up to 540B parameters and observe benefits across various settings. First, symbol tuning boosts performance on unseen in-context learning tasks and is much more robust to underspecified prompts, such as those without instructions or without natural language labels. Second, symbol-tuned models are much stronger at algorithmic reasoning tasks, with up to 18.2% better performance on the List Functions benchmark and up to 15.3% better performance on the Simple Turing Concepts benchmark. Finally, symbol-tuned models show large improvements in following flipped-labels presented in-context, meaning that they are more capable of using in-context information to override prior semantic knowledge.
Teaching Large Language Models to Self-Debug
Apr 11, 2023



Large language models (LLMs) have achieved impressive performance on code generation. However, for complex programming tasks, generating the correct solution in one go becomes challenging, thus some prior works have designed program repair approaches to improve code generation performance. In this work, we propose Self-Debugging, which teaches a large language model to debug its predicted program via few-shot demonstrations. In particular, we demonstrate that Self-Debugging can teach the large language model to perform rubber duck debugging; i.e., without any feedback on the code correctness or error messages, the model is able to identify its mistakes by explaining the generated code in natural language. Self-Debugging achieves the state-of-the-art performance on several code generation benchmarks, including the Spider dataset for text-to-SQL generation, TransCoder for C++-to-Python translation, and MBPP for text-to-Python generation. On the Spider benchmark where there are no unit tests to verify the correctness of predictions, Self-Debugging with code explanation consistently improves the baseline by 2-3%, and improves the prediction accuracy on problems of the hardest label by 9%. On TransCoder and MBPP where unit tests are available, Self-Debugging improves the baseline accuracy by up to 12%. Meanwhile, by leveraging feedback messages and reusing failed predictions, Self-Debugging notably improves sample efficiency, and can match or outperform baseline models that generate more than 10x candidate programs.
DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection
Apr 01, 2023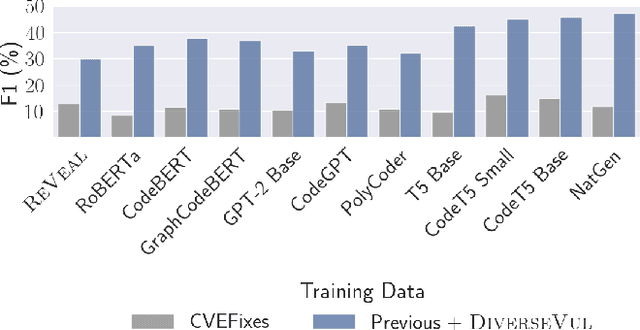
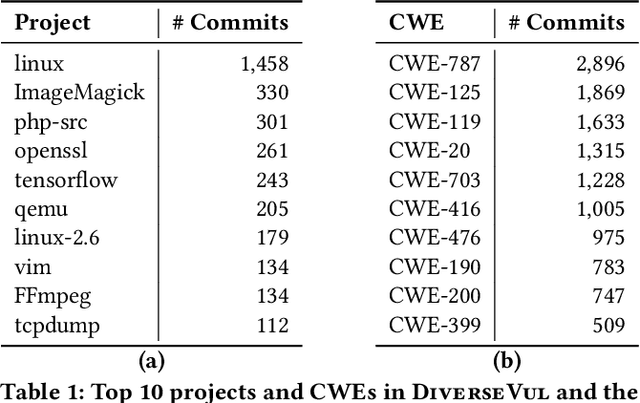
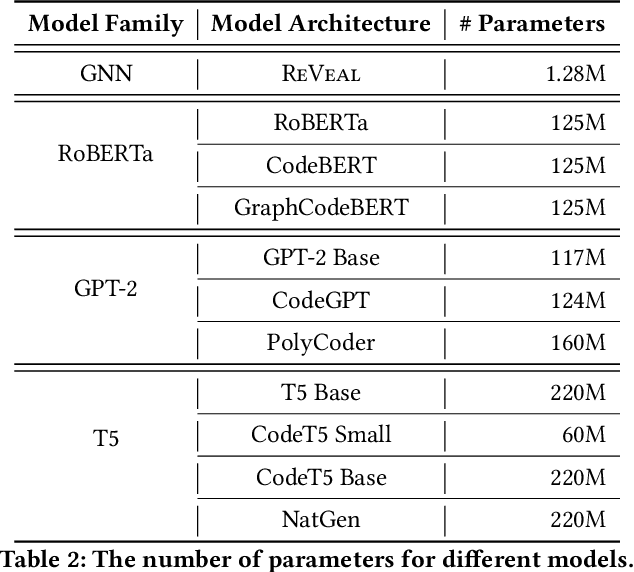
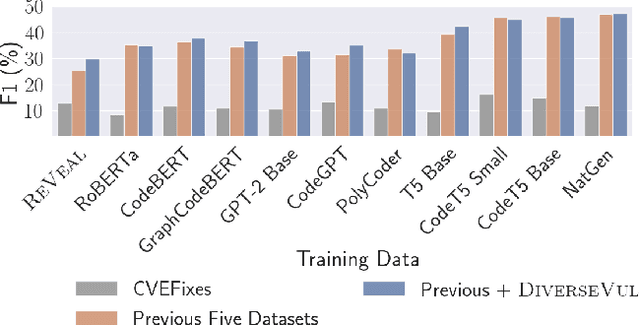
We propose and release a new vulnerable source code dataset. We curate the dataset by crawling security issue websites, extracting vulnerability-fixing commits and source codes from the corresponding projects. Our new dataset contains 150 CWEs, 26,635 vulnerable functions, and 352,606 non-vulnerable functions extracted from 7,861 commits. Our dataset covers 305 more projects than all previous datasets combined. We show that increasing the diversity and volume of training data improves the performance of deep learning models for vulnerability detection. Combining our new dataset with previous datasets, we present an analysis of the challenges and promising research directions of using deep learning for detecting software vulnerabilities. We study 11 model architectures belonging to 4 families. Our results show that deep learning is still not ready for vulnerability detection, due to high false positive rate, low F1 score, and difficulty of detecting hard CWEs. In particular, we demonstrate an important generalization challenge for the deployment of deep learning-based models. However, we also identify hopeful future research directions. We demonstrate that large language models (LLMs) are the future for vulnerability detection, outperforming Graph Neural Networks (GNNs) with manual feature engineering. Moreover, developing source code specific pre-training objectives is a promising research direction to improve the vulnerability detection performance.
Larger language models do in-context learning differently
Mar 08, 2023



We study how in-context learning (ICL) in language models is affected by semantic priors versus input-label mappings. We investigate two setups-ICL with flipped labels and ICL with semantically-unrelated labels-across various model families (GPT-3, InstructGPT, Codex, PaLM, and Flan-PaLM). First, experiments on ICL with flipped labels show that overriding semantic priors is an emergent ability of model scale. While small language models ignore flipped labels presented in-context and thus rely primarily on semantic priors from pretraining, large models can override semantic priors when presented with in-context exemplars that contradict priors, despite the stronger semantic priors that larger models may hold. We next study semantically-unrelated label ICL (SUL-ICL), in which labels are semantically unrelated to their inputs (e.g., foo/bar instead of negative/positive), thereby forcing language models to learn the input-label mappings shown in in-context exemplars in order to perform the task. The ability to do SUL-ICL also emerges primarily with scale, and large-enough language models can even perform linear classification in a SUL-ICL setting. Finally, we evaluate instruction-tuned models and find that instruction tuning strengthens both the use of semantic priors and the capacity to learn input-label mappings, but more of the former.
Online Learning and Optimization for Queues with Unknown Demand Curve and Service Distribution
Mar 06, 2023



We investigate an optimization problem in a queueing system where the service provider selects the optimal service fee p and service capacity \mu to maximize the cumulative expected profit (the service revenue minus the capacity cost and delay penalty). The conventional predict-then-optimize (PTO) approach takes two steps: first, it estimates the model parameters (e.g., arrival rate and service-time distribution) from data; second, it optimizes a model based on the estimated parameters. A major drawback of PTO is that its solution accuracy can often be highly sensitive to the parameter estimation errors because PTO is unable to properly link these errors (step 1) to the quality of the optimized solutions (step 2). To remedy this issue, we develop an online learning framework that automatically incorporates the aforementioned parameter estimation errors in the solution prescription process; it is an integrated method that can "learn" the optimal solution without needing to set up the parameter estimation as a separate step as in PTO. Effectiveness of our online learning approach is substantiated by (i) theoretical results including the algorithm convergence and analysis of the regret ("cost" to pay over time for the algorithm to learn the optimal policy), and (ii) engineering confirmation via simulation experiments of a variety of representative examples. We also provide careful comparisons for PTO and the online learning method.
Large Language Models Can Be Easily Distracted by Irrelevant Context
Feb 13, 2023



Large language models have achieved impressive performance on various natural language processing tasks. However, so far they have been evaluated primarily on benchmarks where all information in the input context is relevant for solving the task. In this work, we investigate the distractibility of large language models, i.e., how the model problem-solving accuracy can be influenced by irrelevant context. In particular, we introduce Grade-School Math with Irrelevant Context (GSM-IC), an arithmetic reasoning dataset with irrelevant information in the problem description. We use this benchmark to measure the distractibility of cutting-edge prompting techniques for large language models, and find that the model performance is dramatically decreased when irrelevant information is included. We also identify several approaches for mitigating this deficiency, such as decoding with self-consistency and adding to the prompt an instruction that tells the language model to ignore the irrelevant information.
Data-pooling Reinforcement Learning for Personalized Healthcare Intervention
Nov 16, 2022Motivated by the emerging needs of personalized preventative intervention in many healthcare applications, we consider a multi-stage, dynamic decision-making problem in the online setting with unknown model parameters. To deal with the pervasive issue of small sample size in personalized planning, we develop a novel data-pooling reinforcement learning (RL) algorithm based on a general perturbed value iteration framework. Our algorithm adaptively pools historical data, with three main innovations: (i) the weight of pooling ties directly to the performance of decision (measured by regret) as opposed to estimation accuracy in conventional methods; (ii) no parametric assumptions are needed between historical and current data; and (iii) requiring data-sharing only via aggregate statistics, as opposed to patient-level data. Our data-pooling algorithm framework applies to a variety of popular RL algorithms, and we establish a theoretical performance guarantee showing that our pooling version achieves a regret bound strictly smaller than that of the no-pooling counterpart. We substantiate the theoretical development with empirically better performance of our algorithm via a case study in the context of post-discharge intervention to prevent unplanned readmissions, generating practical insights for healthcare management. In particular, our algorithm alleviates privacy concerns about sharing health data, which (i) opens the door for individual organizations to levering public datasets or published studies to better manage their own patients; and (ii) provides the basis for public policy makers to encourage organizations to share aggregate data to improve population health outcomes for the broader community.
Benchmarking Language Models for Code Syntax Understanding
Oct 26, 2022



Pre-trained language models have demonstrated impressive performance in both natural language processing and program understanding, which represent the input as a token sequence without explicitly modeling its structure. Some prior works show that pre-trained language models can capture the syntactic rules of natural languages without finetuning on syntax understanding tasks. However, there is limited understanding of how well pre-trained models understand the code structure so far. In this work, we perform the first thorough benchmarking of the state-of-the-art pre-trained models for identifying the syntactic structures of programs. Specifically, we introduce CodeSyntax, a large-scale dataset of programs annotated with the syntactic relationships in their corresponding abstract syntax trees. Our key observation is that existing language models pretrained on code still lack the understanding of code syntax. In fact, these pre-trained programming language models fail to match the performance of simple baselines based on positional offsets and keywords. We also present a natural language benchmark to highlight the differences between natural languages and programming languages in terms of syntactic structure understanding. Our findings point out key limitations of existing pre-training methods for programming languages, and suggest the importance of modeling code syntactic structures.