 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Feature Mining for Predictive Model Enhancement with Large Language Models
Oct 06, 2024Predictive modeling often faces challenges due to limited data availability and quality, especially in domains where collected features are weakly correlated with outcomes and where additional feature collection is constrained by ethical or practical difficulties. Traditional machine learning (ML) models struggle to incorporate unobserved yet critical factors. In this work, we introduce an effective approach to formulate latent feature mining as text-to-text propositional logical reasoning. We propose FLAME (Faithful Latent Feature Mining for Predictive Model Enhancement), a framework that leverages large language models (LLMs) to augment observed features with latent features and enhance the predictive power of ML models in downstream tasks. Our framework is generalizable across various domains with necessary domain-specific adaptation, as it is designed to incorporate contextual information unique to each area, ensuring effective transfer to different areas facing similar data availability challenges. We validate our framework with two case studies: (1) the criminal justice system, a domain characterized by limited and ethically challenging data collection; (2) the healthcare domain, where patient privacy concerns and the complexity of medical data limit comprehensive feature collection. Our results show that inferred latent features align well with ground truth labels and significantly enhance the downstream classifier.
Data-pooling Reinforcement Learning for Personalized Healthcare Intervention
Nov 16, 2022Motivated by the emerging needs of personalized preventative intervention in many healthcare applications, we consider a multi-stage, dynamic decision-making problem in the online setting with unknown model parameters. To deal with the pervasive issue of small sample size in personalized planning, we develop a novel data-pooling reinforcement learning (RL) algorithm based on a general perturbed value iteration framework. Our algorithm adaptively pools historical data, with three main innovations: (i) the weight of pooling ties directly to the performance of decision (measured by regret) as opposed to estimation accuracy in conventional methods; (ii) no parametric assumptions are needed between historical and current data; and (iii) requiring data-sharing only via aggregate statistics, as opposed to patient-level data. Our data-pooling algorithm framework applies to a variety of popular RL algorithms, and we establish a theoretical performance guarantee showing that our pooling version achieves a regret bound strictly smaller than that of the no-pooling counterpart. We substantiate the theoretical development with empirically better performance of our algorithm via a case study in the context of post-discharge intervention to prevent unplanned readmissions, generating practical insights for healthcare management. In particular, our algorithm alleviates privacy concerns about sharing health data, which (i) opens the door for individual organizations to levering public datasets or published studies to better manage their own patients; and (ii) provides the basis for public policy makers to encourage organizations to share aggregate data to improve population health outcomes for the broader community.
Group-Aware Threshold Adaptation for Fair Classification
Nov 08, 2021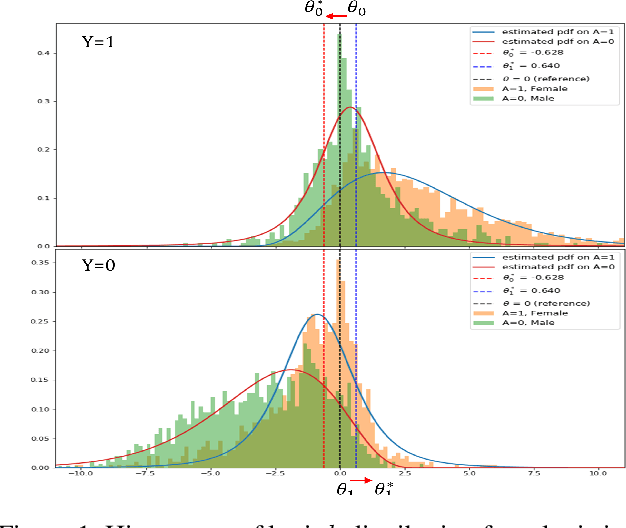


The fairness in machine learning is getting increasing attention, as its applications in different fields continue to expand and diversify. To mitigate the discriminated model behaviors between different demographic groups, we introduce a novel post-processing method to optimize over multiple fairness constraints through group-aware threshold adaptation. We propose to learn adaptive classification thresholds for each demographic group by optimizing the confusion matrix estimated from the probability distribution of a classification model output. As we only need an estimated probability distribution of model output instead of the classification model structure, our post-processing model can be applied to a wide range of classification models and improve fairness in a model-agnostic manner and ensure privacy. This even allows us to post-process existing fairness methods to further improve the trade-off between accuracy and fairness. Moreover, our model has low computational cost. We provide rigorous theoretical analysis on the convergence of our optimization algorithm and the trade-off between accuracy and fairness of our method. Our method theoretically enables a better upper bound in near optimality than existing method under same condition. Experimental results demonstrate that our method outperforms state-of-the-art methods and obtains the result that is closest to the theoretical accuracy-fairness trade-off boundary.
A High-fidelity, Machine-learning Enhanced Queueing Network Simulation Model for Hospital Ultrasound Operations
Apr 12, 2021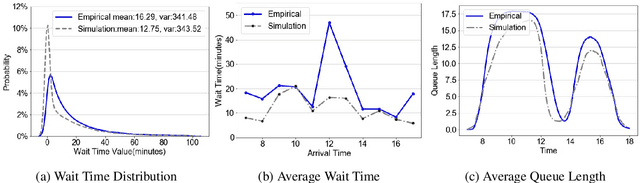

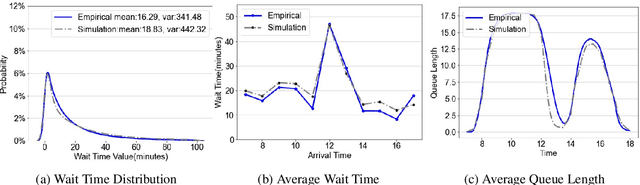

We collaborate with a large teaching hospital in Shenzhen, China and build a high-fidelity simulation model for its ultrasound center to predict key performance metrics, including the distributions of queue length, waiting time and sojourn time, with high accuracy. The key challenge to build an accurate simulation model is to understanding the complicated patient routing at the ultrasound center. To address the issue, we propose a novel two-level routing component to the queueing network model. We apply machine learning tools to calibrate the key components of the queueing model from data with enhanced accuracy.
An Efficient Pessimistic-Optimistic Algorithm for Constrained Linear Bandits
Feb 10, 2021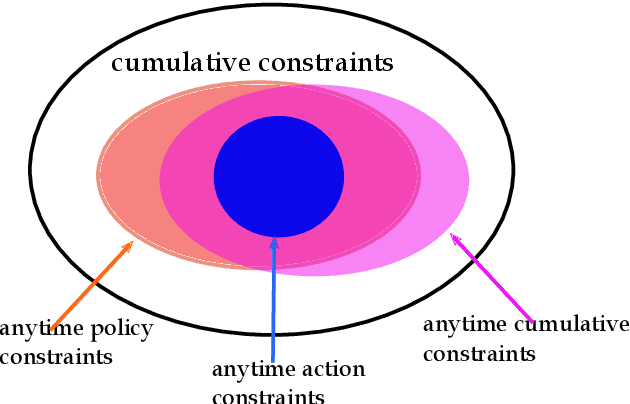

This paper considers stochastic linear bandits with general constraints. The objective is to maximize the expected cumulative reward over horizon $T$ subject to a set of constraints in each round $\tau\leq T$. We propose a pessimistic-optimistic algorithm for this problem, which is efficient in two aspects. First, the algorithm yields $\tilde{\cal O}\left(\left(\frac{K^{1.5}}{\delta^2}+d\right)\sqrt{\tau}\right)$ (pseudo) regret in round $\tau\leq T,$ where $K$ is the number of constraints, $d$ is the dimension of the reward feature space, and $\delta$ is a Slater's constant; and zero constraint violation in any round $\tau>\tau',$ where $\tau'$ is independent of horizon $T.$ Second, the algorithm is computationally efficient. Our algorithm is based on the primal-dual approach in optimization, and includes two components. The primal component is similar to unconstrained stochastic linear bandits (our algorithm uses the linear upper confidence bound algorithm (LinUCB)). The computational complexity of the dual component depends on the number of constraints, and is independent of sizes of the contextual space, the action space, and even the feature space. So the overall computational complexity of our algorithm is similar to the linear UCB for unconstrained stochastic linear bandits.
POND: Pessimistic-Optimistic oNline Dispatch
Oct 20, 2020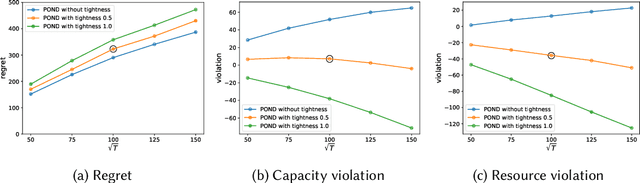
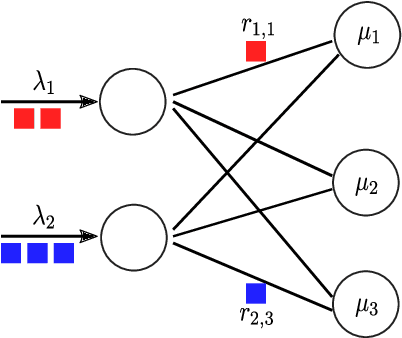
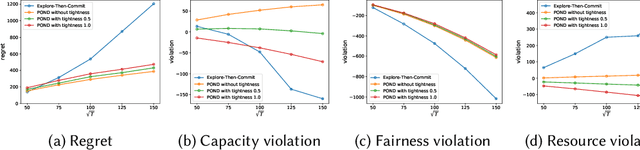
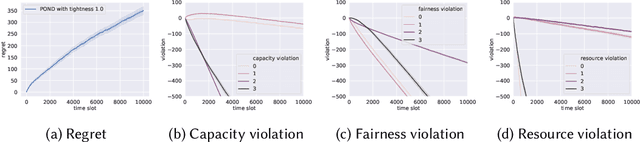
This paper considers constrained online dispatch with unknown arrival, reward and constraint distributions. We propose a novel online dispatch algorithm, named POND, standing for Pessimistic-Optimistic oNline Dispatch, which achieves $O(\sqrt{T})$ regret and $O(1)$ constraint violation. Both bounds are sharp. Our experiments on synthetic and real datasets show that POND achieves low regret with minimal constraint violations.
Robustness-Driven Exploration with Probabilistic Metric Temporal Logic
Dec 03, 2019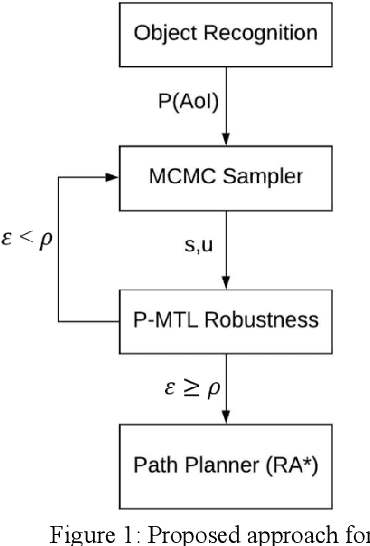
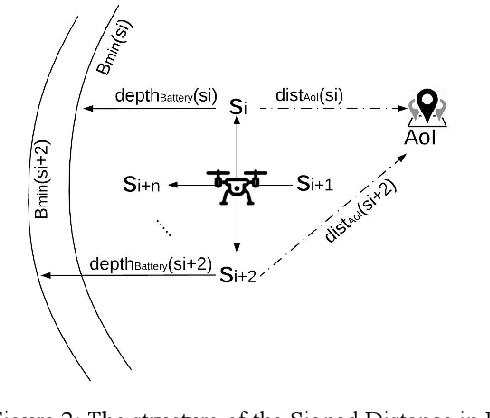
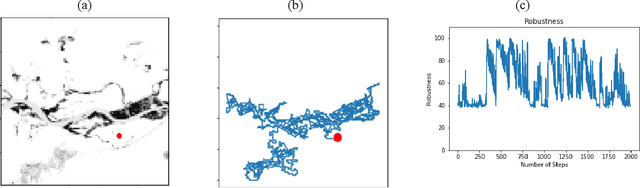

The ability to perform autonomous exploration is essential for unmanned aerial vehicles (UAV) operating in unstructured or unknown environments where it is hard or even impossible to describe the environment beforehand. However, algorithms for autonomous exploration often focus on optimizing time and coverage in a greedy fashion. That type of exploration can collect irrelevant data and wastes time navigating areas with no important information. In this paper, we propose a method for exploiting the discovered knowledge about the environment while exploring it by relying on a theory of robustness based on Probabilistic Metric Temporal Logic (P-MTL) as applied to offline verification and online control of hybrid systems. By maximizing the satisfaction of the predefined P-MTL specifications of the exploration problem, the robustness values guide the UAV towards areas with more interesting information to gain. We use Markov Chain Monte Carlo to solve the P-MTL constraints. We demonstrate the effectiveness of the proposed approach by simulating autonomous exploration over Amazonian rainforest where our approach is used to detect areas occupied by illegal Artisanal Small-scale Gold Mining (ASGM) activities. The results show that our approach outperform a greedy exploration approach (Autonomous Exploration Planner) by 38% in terms of ASGM coverage.