 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Start Up a Start-Up$-$Embedding Strategic Demand Development in Operational On-Demand Fulfillment via Reinforcement Learning with Information Shaping
Apr 08, 2025The last few years have witnessed rapid growth in the on-demand delivery market, with many start-ups entering the field. However, not all of these start-ups have succeeded due to various reasons, among others, not being able to establish a large enough customer base. In this paper, we address this problem that many on-demand transportation start-ups face: how to establish themselves in a new market. When starting, such companies often have limited fleet resources to serve demand across a city. Depending on the use of the fleet, varying service quality is observed in different areas of the city, and in turn, the service quality impacts the respective growth of demand in each area. Thus, operational fulfillment decisions drive the longer-term demand development. To integrate strategic demand development into real-time fulfillment operations, we propose a two-step approach. First, we derive analytical insights into optimal allocation decisions for a stylized problem. Second, we use these insights to shape the training data of a reinforcement learning strategy for operational real-time fulfillment. Our experiments demonstrate that combining operational efficiency with long-term strategic planning is highly advantageous. Further, we show that the careful shaping of training data is essential for the successful development of demand.
GPTDrawer: Enhancing Visual Synthesis through ChatGPT
Dec 11, 2024



In the burgeoning field of AI-driven image generation, the quest for precision and relevance in response to textual prompts remains paramount. This paper introduces GPTDrawer, an innovative pipeline that leverages the generative prowess of GPT-based models to enhance the visual synthesis process. Our methodology employs a novel algorithm that iteratively refines input prompts using keyword extraction, semantic analysis, and image-text congruence evaluation. By integrating ChatGPT for natural language processing and Stable Diffusion for image generation, GPTDrawer produces a batch of images that undergo successive refinement cycles, guided by cosine similarity metrics until a threshold of semantic alignment is attained. The results demonstrate a marked improvement in the fidelity of images generated in accordance with user-defined prompts, showcasing the system's ability to interpret and visualize complex semantic constructs. The implications of this work extend to various applications, from creative arts to design automation, setting a new benchmark for AI-assisted creative processes.
Energy-Guided Diffusion Sampling for Offline-to-Online Reinforcement Learning
Jul 17, 2024



Combining offline and online reinforcement learning (RL) techniques is indeed crucial for achieving efficient and safe learning where data acquisition is expensive. Existing methods replay offline data directly in the online phase, resulting in a significant challenge of data distribution shift and subsequently causing inefficiency in online fine-tuning. To address this issue, we introduce an innovative approach, \textbf{E}nergy-guided \textbf{DI}ffusion \textbf{S}ampling (EDIS), which utilizes a diffusion model to extract prior knowledge from the offline dataset and employs energy functions to distill this knowledge for enhanced data generation in the online phase. The theoretical analysis demonstrates that EDIS exhibits reduced suboptimality compared to solely utilizing online data or directly reusing offline data. EDIS is a plug-in approach and can be combined with existing methods in offline-to-online RL setting. By implementing EDIS to off-the-shelf methods Cal-QL and IQL, we observe a notable 20% average improvement in empirical performance on MuJoCo, AntMaze, and Adroit environments. Code is available at \url{https://github.com/liuxhym/EDIS}.
Region-level labels in ice charts can produce pixel-level segmentation for Sea Ice types
May 16, 2024



Fully supervised deep learning approaches have demonstrated impressive accuracy in sea ice classification, but their dependence on high-resolution labels presents a significant challenge due to the difficulty of obtaining such data. In response, our weakly supervised learning method provides a compelling alternative by utilizing lower-resolution regional labels from expert-annotated ice charts. This approach achieves exceptional pixel-level classification performance by introducing regional loss representations during training to measure the disparity between predicted and ice chart-derived sea ice type distributions. Leveraging the AI4Arctic Sea Ice Challenge Dataset, our method outperforms the fully supervised U-Net benchmark, the top solution of the AutoIce challenge, in both mapping resolution and class-wise accuracy, marking a significant advancement in automated operational sea ice mapping.
Mix of Experts Language Model for Named Entity Recognition
Apr 30, 2024Named Entity Recognition (NER) is an essential steppingstone in the field of natural language processing. Although promising performance has been achieved by various distantly supervised models, we argue that distant supervision inevitably introduces incomplete and noisy annotations, which may mislead the model training process. To address this issue, we propose a robust NER model named BOND-MoE based on Mixture of Experts (MoE). Instead of relying on a single model for NER prediction, multiple models are trained and ensembled under the Expectation-Maximization (EM) framework, so that noisy supervision can be dramatically alleviated. In addition, we introduce a fair assignment module to balance the document-model assignment process. Extensive experiments on real-world datasets show that the proposed method achieves state-of-the-art performance compared with other distantly supervised NER.
Few-shot Name Entity Recognition on StackOverflow
Apr 15, 2024StackOverflow, with its vast question repository and limited labeled examples, raise an annotation challenge for us. We address this gap by proposing RoBERTa+MAML, a few-shot named entity recognition (NER) method leveraging meta-learning. Our approach, evaluated on the StackOverflow NER corpus (27 entity types), achieves a 5% F1 score improvement over the baseline. We improved the results further domain-specific phrase processing enhance results.
CoNi-MPC: Cooperative Non-inertial Frame Based Model Predictive Control
Jun 20, 2023This paper presents a novel solution for UAV control in cooperative multi-robot systems, which can be used in various scenarios such as leader-following, landing on a moving base, or specific relative motion with a target. Unlike classical methods that tackle UAV control in the world frame, we directly control the UAV in the target coordinate frame, without making motion assumptions about the target. In detail, we formulate a non-linear model predictive controller of a UAV within a non-inertial frame (i.e., the target frame). The system requires the relative states (pose and velocity), the angular velocity and the accelerations of the target, which can be obtained by relative localization methods and ubiquitous MEMS IMU sensors, respectively. This framework eliminates dependencies that are vital in classical solutions, such as accurate state estimation for both the agent and target, prior knowledge of the target motion model, and continuous trajectory re-planning for some complex tasks. We have performed extensive simulations to investigate the control performance considering the varying motion characteristics of the target. Furthermore, we conducted considerable real robot experiments, employing laboratory motion-capture systems or relative localization methods implemented outdoors, to validate the applicability and feasibility of the proposed approach.
Measuring Sample Efficiency and Generalization in Reinforcement Learning Benchmarks: NeurIPS 2020 Procgen Benchmark
Mar 29, 2021
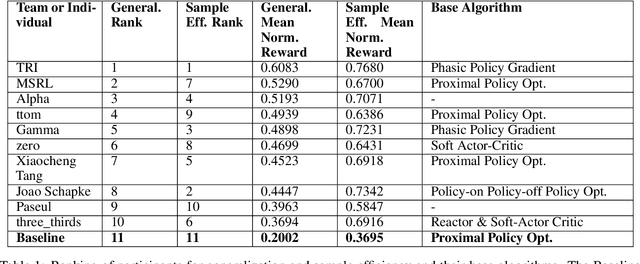
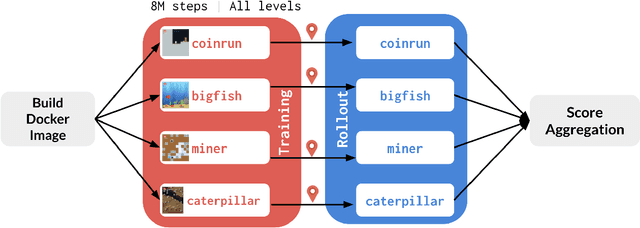
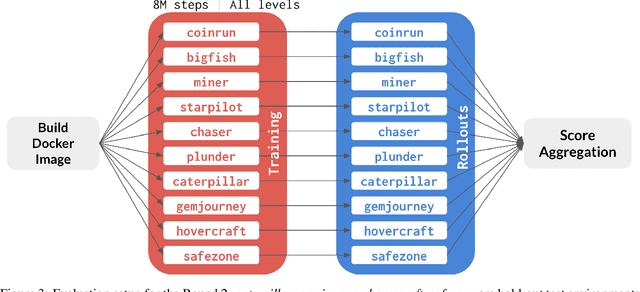
The NeurIPS 2020 Procgen Competition was designed as a centralized benchmark with clearly defined tasks for measuring Sample Efficiency and Generalization in Reinforcement Learning. Generalization remains one of the most fundamental challenges in deep reinforcement learning, and yet we do not have enough benchmarks to measure the progress of the community on Generalization in Reinforcement Learning. We present the design of a centralized benchmark for Reinforcement Learning which can help measure Sample Efficiency and Generalization in Reinforcement Learning by doing end to end evaluation of the training and rollout phases of thousands of user submitted code bases in a scalable way. We designed the benchmark on top of the already existing Procgen Benchmark by defining clear tasks and standardizing the end to end evaluation setups. The design aims to maximize the flexibility available for researchers who wish to design future iterations of such benchmarks, and yet imposes necessary practical constraints to allow for a system like this to scale. This paper presents the competition setup and the details and analysis of the top solutions identified through this setup in context of 2020 iteration of the competition at NeurIPS.
Same-Day Delivery with Fairness
Jul 19, 2020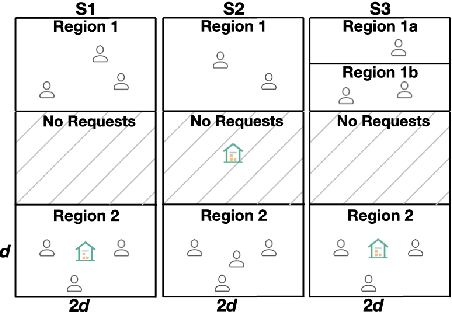
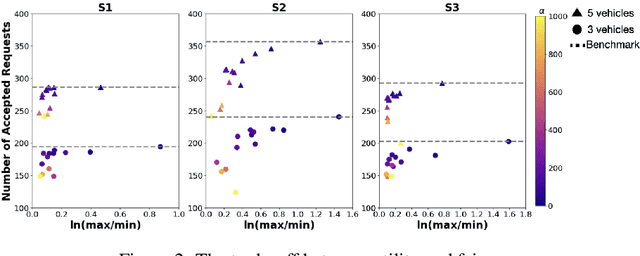
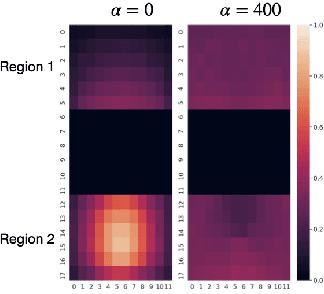
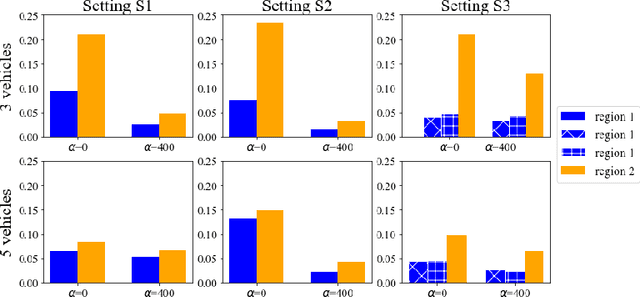
The demand for same-day delivery (SDD) has increased rapidly in the last few years and has particularly boomed during the COVID-19 pandemic. Existing literature on the problem has focused on maximizing the utility, represented as the total number of expected requests served. However, a utility-driven solution results in unequal opportunities for customers to receive delivery service, raising questions about fairness. In this paper, we study the problem of achieving fairness in SDD. We construct a regional-level fairness constraint that ensures customers from different regions have an equal chance of being served. We develop a reinforcement learning model to learn policies that focus on both overall utility and fairness. Experimental results demonstrate the ability of our approach to mitigate the unfairness caused by geographic differences and constraints of resources, at both coarser and finer-grained level and with a small cost to utility. In addition, we simulate a real-world situation where the system is suddenly overwhelmed by a surge of requests, mimicking the COVID-19 scenario. Our model is robust to the systematic pressure and is able to maintain fairness with little compromise to the utility.
Deep Learning for Content-based Personalized Viewport Prediction of 360-Degree VR Videos
Mar 01, 2020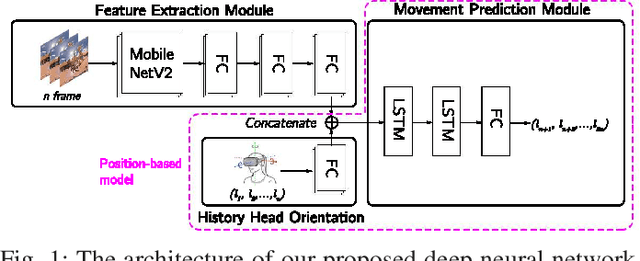
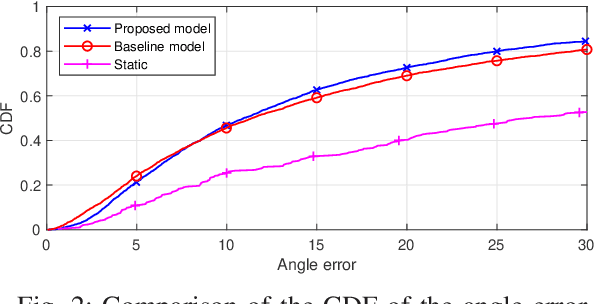
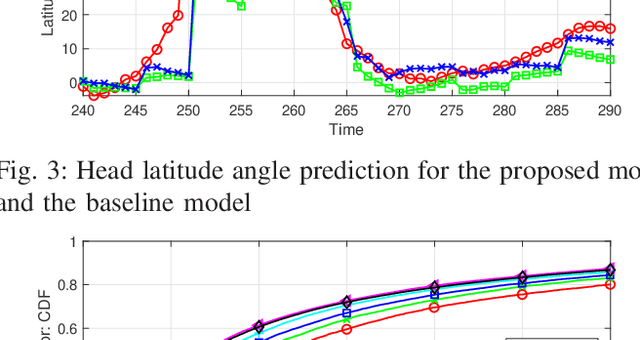
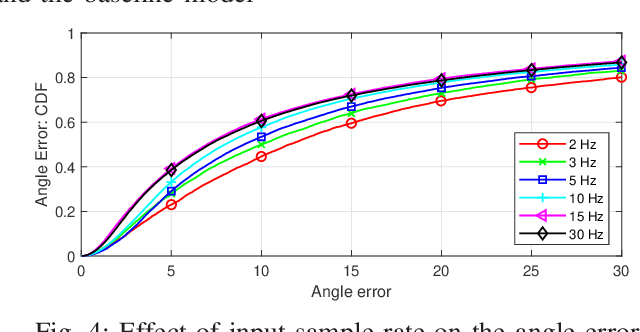
In this paper, the problem of head movement prediction for virtual reality videos is studied. In the considered model, a deep learning network is introduced to leverage position data as well as video frame content to predict future head movement. For optimizing data input into this neural network, data sample rate, reduced data, and long-period prediction length are also explored for this model. Simulation results show that the proposed approach yields 16.1\% improvement in terms of prediction accuracy compared to a baseline approach that relies only on the position data.