 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeatInsight: An Online ML Feature Management System on 4Paradigm Sage-Studio Platform
Apr 01, 2025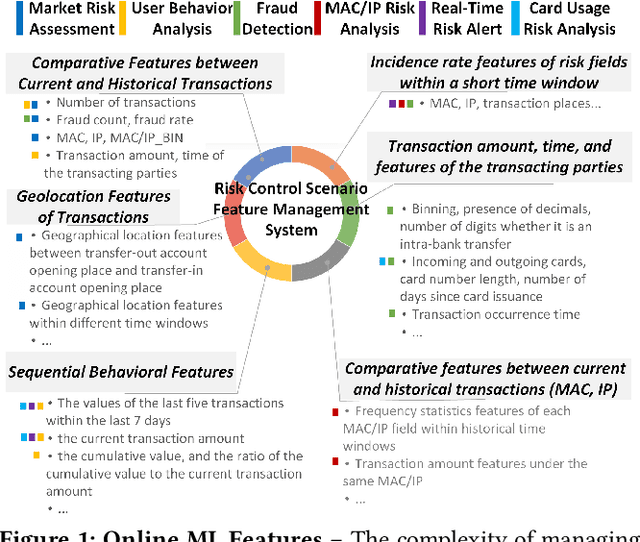
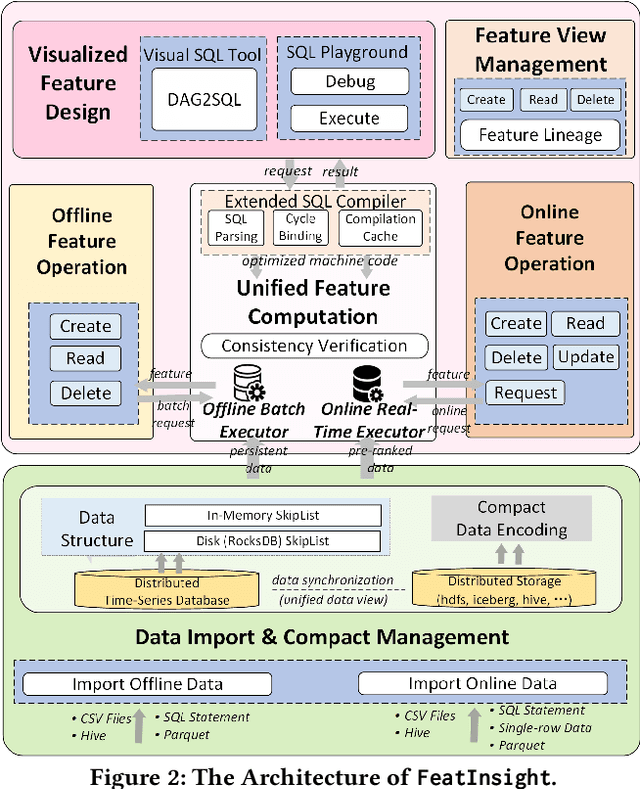
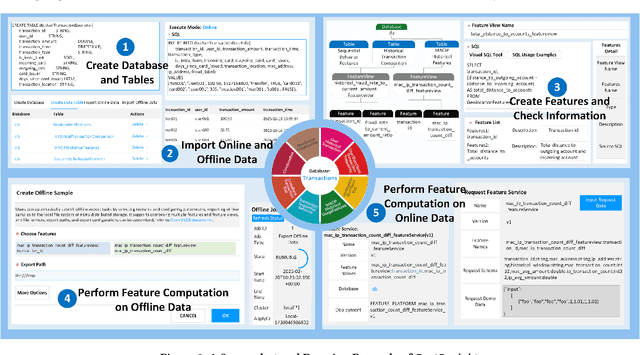
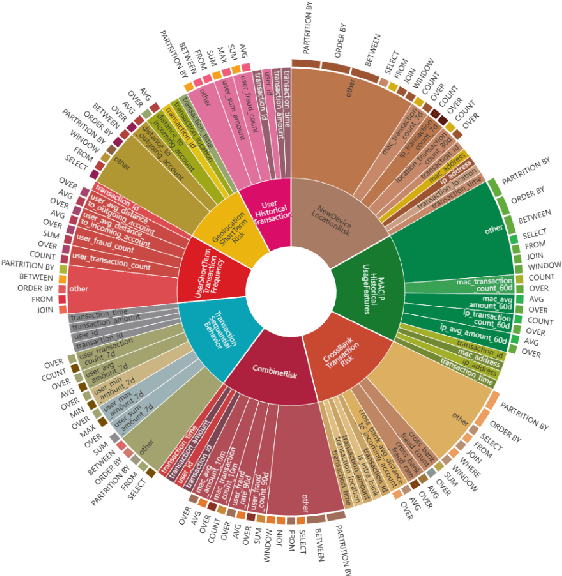
Feature management is essential for many online machine learning applications and can often become the performance bottleneck (e.g., taking up to 70% of the overall latency in sales prediction service). Improper feature configurations (e.g., introducing too many irrelevant features) can severely undermine the model's generalization capabilities. However, managing online ML features is challenging due to (1) large-scale, complex raw data (e.g., the 2018 PHM dataset contains 17 tables and dozens to hundreds of columns), (2) the need for high-performance, consistent computation of interdependent features with complex patterns, and (3) the requirement for rapid updates and deployments to accommodate real-time data changes. In this demo, we present FeatInsight, a system that supports the entire feature lifecycle, including feature design, storage, visualization, computation, verification, and lineage management. FeatInsight (with OpenMLDB as the execution engine) has been deployed in over 100 real-world scenarios on 4Paradigm's Sage Studio platform, handling up to a trillion-dimensional feature space and enabling millisecond-level feature updates. We demonstrate how FeatInsight enhances feature design efficiency (e.g., for online product recommendation) and improve feature computation performance (e.g., for online fraud detection). The code is available at https://github.com/4paradigm/FeatInsight.
Improving Transformer Based Line Segment Detection with Matched Predicting and Re-ranking
Feb 25, 2025Classical Transformer-based line segment detection methods have delivered impressive results. However, we observe that some accurately detected line segments are assigned low confidence scores during prediction, causing them to be ranked lower and potentially suppressed. Additionally, these models often require prolonged training periods to achieve strong performance, largely due to the necessity of bipartite matching. In this paper, we introduce RANK-LETR, a novel Transformer-based line segment detection method. Our approach leverages learnable geometric information to refine the ranking of predicted line segments by enhancing the confidence scores of high-quality predictions in a posterior verification step. We also propose a new line segment proposal method, wherein the feature point nearest to the centroid of the line segment directly predicts the location, significantly improving training efficiency and stability. Moreover, we introduce a line segment ranking loss to stabilize rankings during training, thereby enhancing the generalization capability of the model. Experimental results demonstrate that our method outperforms other Transformer-based and CNN-based approaches in prediction accuracy while requiring fewer training epochs than previous Transformer-based models.
Towards Typologically Aware Rescoring to Mitigate Unfaithfulness in Lower-Resource Languages
Feb 24, 2025Multilingual large language models (LLMs) are known to more frequently generate non-faithful output in resource-constrained languages (Guerreiro et al., 2023 - arXiv:2303.16104), potentially because these typologically diverse languages are underrepresented in their training data. To mitigate unfaithfulness in such settings, we propose using computationally light auxiliary models to rescore the outputs of larger architectures. As proof of the feasibility of such an approach, we show that monolingual 4-layer BERT models pretrained from scratch on less than 700 MB of data without fine-tuning are able to identify faithful summaries with a mean accuracy of 88.33% in three genetically unrelated languages that differ in their morphological complexity - Vietnamese, Polish and Georgian. The same hyperparameter combination moreover generalises well to three other tasks, suggesting applications for rescoring beyond improving faithfulness. In order to inform typologically aware model selection, we also investigate how morphological complexity interacts with regularisation, model depth and training objectives, ultimately demonstrating that morphologically complex languages are more likely to benefit from dropout, while across languages downstream performance is enhanced most by shallow architectures as well as training using the standard BERT objectives.
Noise-Adaptive Conformal Classification with Marginal Coverage
Jan 29, 2025



Conformal inference provides a rigorous statistical framework for uncertainty quantification in machine learning, enabling well-calibrated prediction sets with precise coverage guarantees for any classification model. However, its reliance on the idealized assumption of perfect data exchangeability limits its effectiveness in the presence of real-world complications, such as low-quality labels -- a widespread issue in modern large-scale data sets. This work tackles this open problem by introducing an adaptive conformal inference method capable of efficiently handling deviations from exchangeability caused by random label noise, leading to informative prediction sets with tight marginal coverage guarantees even in those challenging scenarios. We validate our method through extensive numerical experiments demonstrating its effectiveness on synthetic and real data sets, including CIFAR-10H and BigEarthNet.
Structured 3D Latents for Scalable and Versatile 3D Generation
Dec 02, 2024



We introduce a novel 3D generation method for versatile and high-quality 3D asset creation. The cornerstone is a unified Structured LATent (SLAT) representation which allows decoding to different output formats, such as Radiance Fields, 3D Gaussians, and meshes. This is achieved by integrating a sparsely-populated 3D grid with dense multiview visual features extracted from a powerful vision foundation model, comprehensively capturing both structural (geometry) and textural (appearance) information while maintaining flexibility during decoding. We employ rectified flow transformers tailored for SLAT as our 3D generation models and train models with up to 2 billion parameters on a large 3D asset dataset of 500K diverse objects. Our model generates high-quality results with text or image conditions, significantly surpassing existing methods, including recent ones at similar scales. We showcase flexible output format selection and local 3D editing capabilities which were not offered by previous models. Code, model, and data will be released.
MoGe: Unlocking Accurate Monocular Geometry Estimation for Open-Domain Images with Optimal Training Supervision
Oct 24, 2024



We present MoGe, a powerful model for recovering 3D geometry from monocular open-domain images. Given a single image, our model directly predicts a 3D point map of the captured scene with an affine-invariant representation, which is agnostic to true global scale and shift. This new representation precludes ambiguous supervision in training and facilitate effective geometry learning. Furthermore, we propose a set of novel global and local geometry supervisions that empower the model to learn high-quality geometry. These include a robust, optimal, and efficient point cloud alignment solver for accurate global shape learning, and a multi-scale local geometry loss promoting precise local geometry supervision. We train our model on a large, mixed dataset and demonstrate its strong generalizability and high accuracy. In our comprehensive evaluation on diverse unseen datasets, our model significantly outperforms state-of-the-art methods across all tasks, including monocular estimation of 3D point map, depth map, and camera field of view. Code and models will be released on our project page.
l_inf-approximation of localized distributions
Oct 15, 2024Distributions in spatial model often exhibit localized features. Intuitively, this locality implies a low intrinsic dimensionality, which can be exploited for efficient approximation and computation of complex distributions. However, existing approximation theory mainly considers the joint distributions, which does not guarantee that the marginal errors are small. In this work, we establish a dimension independent error bound for the marginals of approximate distributions. This $\ell_\infty$-approximation error is obtained using Stein's method, and we propose a $\delta$-locality condition that quantifies the degree of localization in a distribution. We also show how $\delta$-locality can be derived from different conditions that characterize the distribution's locality. Our $\ell_\infty$ bound motivates the localization of existing approximation methods to respect the locality. As examples, we show how to use localized likelihood-informed subspace method and localized score matching, which not only avoid dimension dependence in the approximation error, but also significantly reduce the computational cost due to the local and parallel implementation based on the localized structure.
Data-Driven Fire Modeling: Learning First Arrival Times and Model Parameters with Neural Networks
Aug 16, 2024



Data-driven techniques are being increasingly applied to complement physics-based models in fire science. However, the lack of sufficiently large datasets continues to hinder the application of certain machine learning techniques. In this paper, we use simulated data to investigate the ability of neural networks to parameterize dynamics in fire science. In particular, we investigate neural networks that map five key parameters in fire spread to the first arrival time, and the corresponding inverse problem. By using simulated data, we are able to characterize the error, the required dataset size, and the convergence properties of these neural networks. For the inverse problem, we quantify the network's sensitivity in estimating each of the key parameters. The findings demonstrate the potential of machine learning in fire science, highlight the challenges associated with limited dataset sizes, and quantify the sensitivity of neural networks to estimate key parameters governing fire spread dynamics.
Evaluation of Missing Data Analytical Techniques in Longitudinal Research: Traditional and Machine Learning Approaches
Jun 19, 2024Missing Not at Random (MNAR) and nonnormal data are challenging to handle. Traditional missing data analytical techniques such as full information maximum likelihood estimation (FIML) may fail with nonnormal data as they are built on normal distribution assumptions. Two-Stage Robust Estimation (TSRE) does manage nonnormal data, but both FIML and TSRE are less explored in longitudinal studies under MNAR conditions with nonnormal distributions. Unlike traditional statistical approaches, machine learning approaches do not require distributional assumptions about the data. More importantly, they have shown promise for MNAR data; however, their application in longitudinal studies, addressing both Missing at Random (MAR) and MNAR scenarios, is also underexplored. This study utilizes Monte Carlo simulations to assess and compare the effectiveness of six analytical techniques for missing data within the growth curve modeling framework. These techniques include traditional approaches like FIML and TSRE, machine learning approaches by single imputation (K-Nearest Neighbors and missForest), and machine learning approaches by multiple imputation (micecart and miceForest). We investigate the influence of sample size, missing data rate, missing data mechanism, and data distribution on the accuracy and efficiency of model estimation. Our findings indicate that FIML is most effective for MNAR data among the tested approaches. TSRE excels in handling MAR data, while missForest is only advantageous in limited conditions with a combination of very skewed distributions, very large sample sizes (e.g., n larger than 1000), and low missing data rates.
ComboStoc: Combinatorial Stochasticity for Diffusion Generative Models
May 22, 2024



In this paper, we study an under-explored but important factor of diffusion generative models, i.e., the combinatorial complexity. Data samples are generally high-dimensional, and for various structured generation tasks, there are additional attributes which are combined to associate with data samples. We show that the space spanned by the combination of dimensions and attributes is insufficiently sampled by existing training scheme of diffusion generative models, causing degraded test time performance. We present a simple fix to this problem by constructing stochastic processes that fully exploit the combinatorial structures, hence the name ComboStoc. Using this simple strategy, we show that network training is significantly accelerated across diverse data modalities, including images and 3D structured shapes. Moreover, ComboStoc enables a new way of test time generation which uses insynchronized time steps for different dimensions and attributes, thus allowing for varying degrees of control over them.