 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Implicit Ray Function for Generalizable Radiance Field Representation
Apr 25, 2023We propose LIRF (Local Implicit Ray Function), a generalizable neural rendering approach for novel view rendering. Current generalizable neural radiance fields (NeRF) methods sample a scene with a single ray per pixel and may therefore render blurred or aliased views when the input views and rendered views capture scene content with different resolutions. To solve this problem, we propose LIRF to aggregate the information from conical frustums to construct a ray. Given 3D positions within conical frustums, LIRF takes 3D coordinates and the features of conical frustums as inputs and predicts a local volumetric radiance field. Since the coordinates are continuous, LIRF renders high-quality novel views at a continuously-valued scale via volume rendering. Besides, we predict the visible weights for each input view via transformer-based feature matching to improve the performance in occluded areas. Experimental results on real-world scenes validate that our method outperforms state-of-the-art methods on novel view rendering of unseen scenes at arbitrary scales.
Inverting the Imaging Process by Learning an Implicit Camera Model
Apr 25, 2023Representing visual signals with implicit coordinate-based neural networks, as an effective replacement of the traditional discrete signal representation, has gained considerable popularity in computer vision and graphics. In contrast to existing implicit neural representations which focus on modelling the scene only, this paper proposes a novel implicit camera model which represents the physical imaging process of a camera as a deep neural network. We demonstrate the power of this new implicit camera model on two inverse imaging tasks: i) generating all-in-focus photos, and ii) HDR imaging. Specifically, we devise an implicit blur generator and an implicit tone mapper to model the aperture and exposure of the camera's imaging process, respectively. Our implicit camera model is jointly learned together with implicit scene models under multi-focus stack and multi-exposure bracket supervision. We have demonstrated the effectiveness of our new model on a large number of test images and videos, producing accurate and visually appealing all-in-focus and high dynamic range images. In principle, our new implicit neural camera model has the potential to benefit a wide array of other inverse imaging tasks.
Privileged Prior Information Distillation for Image Matting
Nov 25, 2022



Performance of trimap-free image matting methods is limited when trying to decouple the deterministic and undetermined regions, especially in the scenes where foregrounds are semantically ambiguous, chromaless, or high transmittance. In this paper, we propose a novel framework named Privileged Prior Information Distillation for Image Matting (PPID-IM) that can effectively transfer privileged prior environment-aware information to improve the performance of students in solving hard foregrounds. The prior information of trimap regulates only the teacher model during the training stage, while not being fed into the student network during actual inference. In order to achieve effective privileged cross-modality (i.e. trimap and RGB) information distillation, we introduce a Cross-Level Semantic Distillation (CLSD) module that reinforces the trimap-free students with more knowledgeable semantic representations and environment-aware information. We also propose an Attention-Guided Local Distillation module that efficiently transfers privileged local attributes from the trimap-based teacher to trimap-free students for the guidance of local-region optimization. Extensive experiments demonstrate the effectiveness and superiority of our PPID framework on the task of image matting. In addition, our trimap-free IndexNet-PPID surpasses the other competing state-of-the-art methods by a large margin, especially in scenarios with chromaless, weak texture, or irregular objects.
Characterizing the Efficiency of Graph Neural Network Frameworks with a Magnifying Glass
Nov 06, 2022



Graph neural networks (GNNs) have received great attention due to their success in various graph-related learning tasks. Several GNN frameworks have then been developed for fast and easy implementation of GNN models. Despite their popularity, they are not well documented, and their implementations and system performance have not been well understood. In particular, unlike the traditional GNNs that are trained based on the entire graph in a full-batch manner, recent GNNs have been developed with different graph sampling techniques for mini-batch training of GNNs on large graphs. While they improve the scalability, their training times still depend on the implementations in the frameworks as sampling and its associated operations can introduce non-negligible overhead and computational cost. In addition, it is unknown how much the frameworks are 'eco-friendly' from a green computing perspective. In this paper, we provide an in-depth study of two mainstream GNN frameworks along with three state-of-the-art GNNs to analyze their performance in terms of runtime and power/energy consumption. We conduct extensive benchmark experiments at several different levels and present detailed analysis results and observations, which could be helpful for further improvement and optimization.
P4P: Conflict-Aware Motion Prediction for Planning in Autonomous Driving
Nov 03, 2022Motion prediction is crucial in enabling safe motion planning for autonomous vehicles in interactive scenarios. It allows the planner to identify potential conflicts with other traffic agents and generate safe plans. Existing motion predictors often focus on reducing prediction errors, yet it remains an open question on how well they help identify the conflicts for the planner. In this paper, we evaluate state-of-the-art predictors through novel conflict-related metrics, such as the success rate of identifying conflicts. Surprisingly, the predictors suffer from a low success rate and thus lead to a large percentage of collisions when we test the prediction-planning system in an interactive simulator. To fill the gap, we propose a simple but effective alternative that combines a physics-based trajectory generator and a learning-based relation predictor to identify conflicts and infer conflict relations. We demonstrate that our predictor, P4P, achieves superior performance over existing learning-based predictors in realistic interactive driving scenarios from Waymo Open Motion Dataset.
InterSim: Interactive Traffic Simulation via Explicit Relation Modeling
Oct 26, 2022



Interactive traffic simulation is crucial to autonomous driving systems by enabling testing for planners in a more scalable and safe way compared to real-world road testing. Existing approaches learn an agent model from large-scale driving data to simulate realistic traffic scenarios, yet it remains an open question to produce consistent and diverse multi-agent interactive behaviors in crowded scenes. In this work, we present InterSim, an interactive traffic simulator for testing autonomous driving planners. Given a test plan trajectory from the ego agent, InterSim reasons about the interaction relations between the agents in the scene and generates realistic trajectories for each environment agent that are consistent with the relations. We train and validate our model on a large-scale interactive driving dataset. Experiment results show that InterSim achieves better simulation realism and reactivity in two simulation tasks compared to a state-of-the-art learning-based traffic simulator.
Multi-Agent Chance-Constrained Stochastic Shortest Path with Application to Risk-Aware Intelligent Intersection
Oct 03, 2022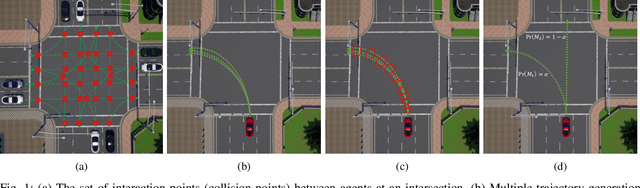
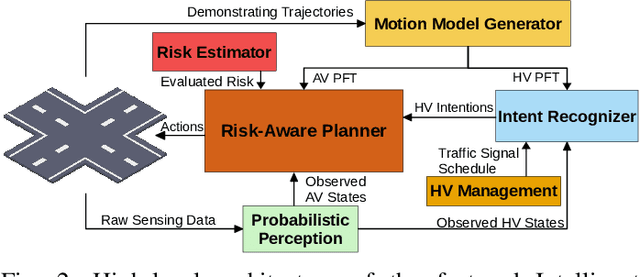
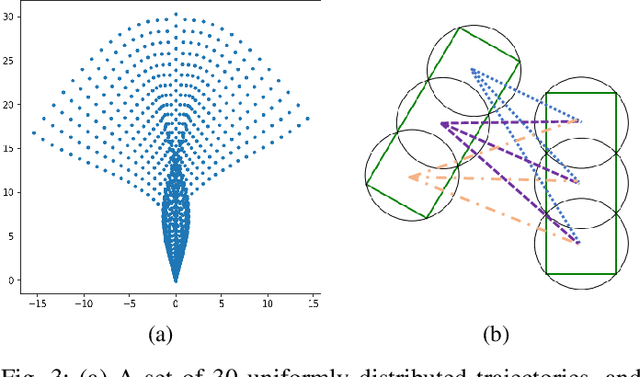
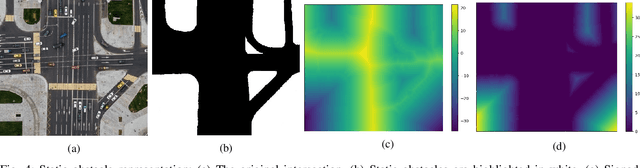
In transportation networks, where traffic lights have traditionally been used for vehicle coordination, intersections act as natural bottlenecks. A formidable challenge for existing automated intersections lies in detecting and reasoning about uncertainty from the operating environment and human-driven vehicles. In this paper, we propose a risk-aware intelligent intersection system for autonomous vehicles (AVs) as well as human-driven vehicles (HVs). We cast the problem as a novel class of Multi-agent Chance-Constrained Stochastic Shortest Path (MCC-SSP) problems and devise an exact Integer Linear Programming (ILP) formulation that is scalable in the number of agents' interaction points (e.g., potential collision points at the intersection). In particular, when the number of agents within an interaction point is small, which is often the case in intersections, the ILP has a polynomial number of variables and constraints. To further improve the running time performance, we show that the collision risk computation can be performed offline. Additionally, a trajectory optimization workflow is provided to generate risk-aware trajectories for any given intersection. The proposed framework is implemented in CARLA simulator and evaluated under a fully autonomous intersection with AVs only as well as in a hybrid setup with a signalized intersection for HVs and an intelligent scheme for AVs. As verified via simulations, the featured approach improves intersection's efficiency by up to $200\%$ while also conforming to the specified tunable risk threshold.
VectorFlow: Combining Images and Vectors for Traffic Occupancy and Flow Prediction
Aug 09, 2022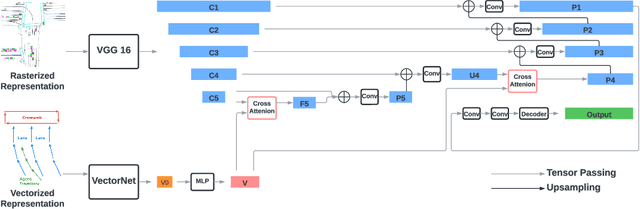
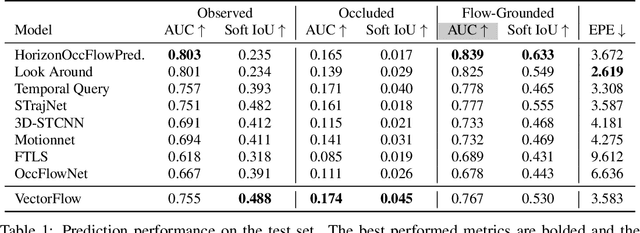

Predicting future behaviors of road agents is a key task in autonomous driving. While existing models have demonstrated great success in predicting marginal agent future behaviors, it remains a challenge to efficiently predict consistent joint behaviors of multiple agents. Recently, the occupancy flow fields representation was proposed to represent joint future states of road agents through a combination of occupancy grid and flow, which supports efficient and consistent joint predictions. In this work, we propose a novel occupancy flow fields predictor to produce accurate occupancy and flow predictions, by combining the power of an image encoder that learns features from a rasterized traffic image and a vector encoder that captures information of continuous agent trajectories and map states. The two encoded features are fused by multiple attention modules before generating final predictions. Our simple but effective model ranks 3rd place on the Waymo Open Dataset Occupancy and Flow Prediction Challenge, and achieves the best performance in the occluded occupancy and flow prediction task.
UniNet: Unified Architecture Search with Convolution, Transformer, and MLP
Jul 12, 2022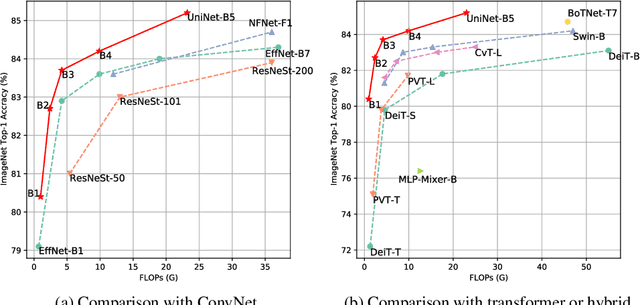
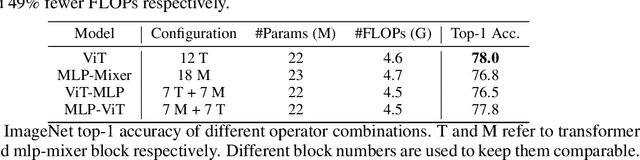
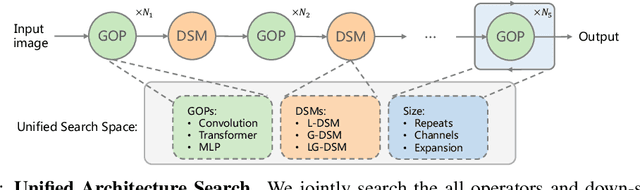
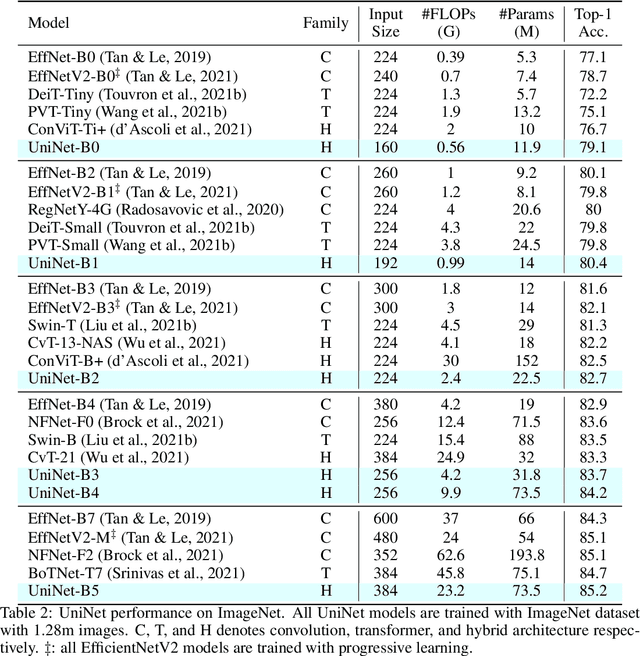
Recently, transformer and multi-layer perceptron (MLP) architectures have achieved impressive results on various vision tasks. However, how to effectively combine those operators to form high-performance hybrid visual architectures still remains a challenge. In this work, we study the learnable combination of convolution, transformer, and MLP by proposing a novel unified architecture search approach. Our approach contains two key designs to achieve the search for high-performance networks. First, we model the very different searchable operators in a unified form, and thus enable the operators to be characterized with the same set of configuration parameters. In this way, the overall search space size is significantly reduced, and the total search cost becomes affordable. Second, we propose context-aware downsampling modules (DSMs) to mitigate the gap between the different types of operators. Our proposed DSMs are able to better adapt features from different types of operators, which is important for identifying high-performance hybrid architectures. Finally, we integrate configurable operators and DSMs into a unified search space and search with a Reinforcement Learning-based search algorithm to fully explore the optimal combination of the operators. To this end, we search a baseline network and scale it up to obtain a family of models, named UniNets, which achieve much better accuracy and efficiency than previous ConvNets and Transformers. In particular, our UniNet-B5 achieves 84.9% top-1 accuracy on ImageNet, outperforming EfficientNet-B7 and BoTNet-T7 with 44% and 55% fewer FLOPs respectively. By pretraining on the ImageNet-21K, our UniNet-B6 achieves 87.4%, outperforming Swin-L with 51% fewer FLOPs and 41% fewer parameters. Code is available at https://github.com/Sense-X/UniNet.
MixMIM: Mixed and Masked Image Modeling for Efficient Visual Representation Learning
May 28, 2022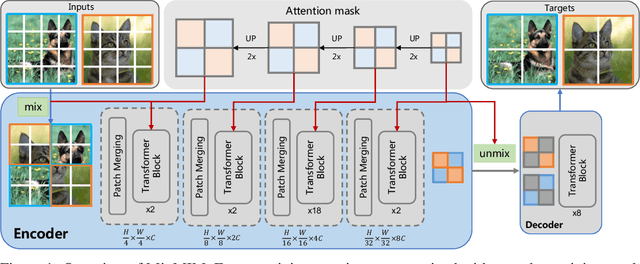

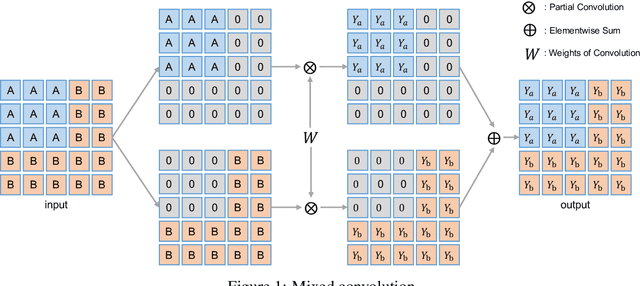
In this study, we propose Mixed and Masked Image Modeling (MixMIM), a simple but efficient MIM method that is applicable to various hierarchical Vision Transformers. Existing MIM methods replace a random subset of input tokens with a special MASK symbol and aim at reconstructing original image tokens from the corrupted image. However, we find that using the MASK symbol greatly slows down the training and causes training-finetuning inconsistency, due to the large masking ratio (e.g., 40% in BEiT). In contrast, we replace the masked tokens of one image with visible tokens of another image, i.e., creating a mixed image. We then conduct dual reconstruction to reconstruct the original two images from the mixed input, which significantly improves efficiency. While MixMIM can be applied to various architectures, this paper explores a simpler but stronger hierarchical Transformer, and scales with MixMIM-B, -L, and -H. Empirical results demonstrate that MixMIM can learn high-quality visual representations efficiently. Notably, MixMIM-B with 88M parameters achieves 85.1% top-1 accuracy on ImageNet-1K by pretraining for 600 epochs, setting a new record for neural networks with comparable model sizes (e.g., ViT-B) among MIM methods. Besides, its transferring performances on the other 6 datasets show MixMIM has better FLOPs / performance tradeoff than previous MIM methods. Code is available at https://github.com/Sense-X/MixMIM.