 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Cut Selection for Mixed-Integer Linear Programming via Hierarchical Sequence Model
Feb 01, 2023



Cutting planes (cuts) are important for solving mixed-integer linear programs (MILPs), which formulate a wide range of important real-world applications. Cut selection -- which aims to select a proper subset of the candidate cuts to improve the efficiency of solving MILPs -- heavily depends on (P1) which cuts should be preferred, and (P2) how many cuts should be selected. Although many modern MILP solvers tackle (P1)-(P2) by manually designed heuristics, machine learning offers a promising approach to learn more effective heuristics from MILPs collected from specific applications. However, many existing learning-based methods focus on learning which cuts should be preferred, neglecting the importance of learning the number of cuts that should be selected. Moreover, we observe from extensive empirical results that (P3) what order of selected cuts should be preferred has a significant impact on the efficiency of solving MILPs as well. To address this challenge, we propose a novel hierarchical sequence model (HEM) to learn cut selection policies via reinforcement learning. Specifically, HEM consists of a two-level model: (1) a higher-level model to learn the number of cuts that should be selected, (2) and a lower-level model -- that formulates the cut selection task as a sequence to sequence learning problem -- to learn policies selecting an ordered subset with the size determined by the higher-level model. To the best of our knowledge, HEM is the first method that can tackle (P1)-(P3) in cut selection simultaneously from a data-driven perspective. Experiments show that HEM significantly improves the efficiency of solving MILPs compared to human-designed and learning-based baselines on both synthetic and large-scale real-world MILPs, including MIPLIB 2017. Moreover, experiments demonstrate that HEM well generalizes to MILPs that are significantly larger than those seen during training.
Offline Reinforcement Learning with Adaptive Behavior Regularization
Nov 15, 2022



Offline reinforcement learning (RL) defines a sample-efficient learning paradigm, where a policy is learned from static and previously collected datasets without additional interaction with the environment. The major obstacle to offline RL is the estimation error arising from evaluating the value of out-of-distribution actions. To tackle this problem, most existing offline RL methods attempt to acquire a policy both ``close" to the behaviors contained in the dataset and sufficiently improved over them, which requires a trade-off between two possibly conflicting targets. In this paper, we propose a novel approach, which we refer to as adaptive behavior regularization (ABR), to balance this critical trade-off. By simply utilizing a sample-based regularization, ABR enables the policy to adaptively adjust its optimization objective between cloning and improving over the policy used to generate the dataset. In the evaluation on D4RL datasets, a widely adopted benchmark for offline reinforcement learning, ABR can achieve improved or competitive performance compared to existing state-of-the-art algorithms.
LQoCo: Learning to Optimize Cache Capacity Overloading in Storage Systems
Mar 21, 2022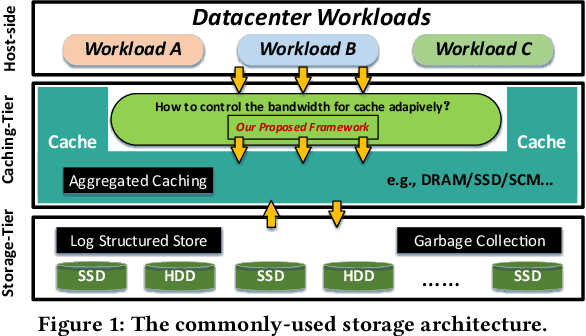

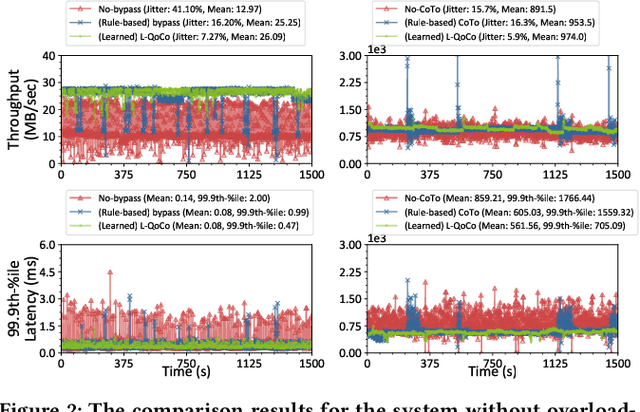
Cache plays an important role to maintain high and stable performance (i.e. high throughput, low tail latency and throughput jitter) in storage systems. Existing rule-based cache management methods, coupled with engineers' manual configurations, cannot meet ever-growing requirements of both time-varying workloads and complex storage systems, leading to frequent cache overloading. In this paper, we for the first time propose a light-weight learning-based cache bandwidth control technique, called \LQoCo which can adaptively control the cache bandwidth so as to effectively prevent cache overloading in storage systems. Extensive experiments with various workloads on real systems show that LQoCo, with its strong adaptability and fast learning ability, can adapt to various workloads to effectively control cache bandwidth, thereby significantly improving the storage performance (e.g. increasing the throughput by 10\%-20\% and reducing the throughput jitter and tail latency by 2X-6X and 1.5X-4X, respectively, compared with two representative rule-based methods).
A Survey for Solving Mixed Integer Programming via Machine Learning
Mar 06, 2022

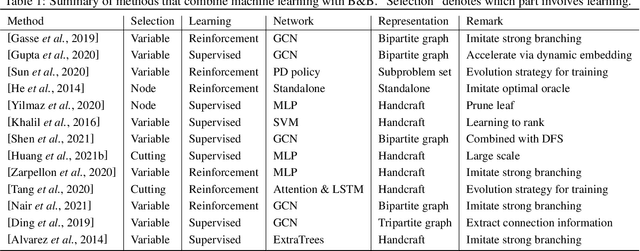
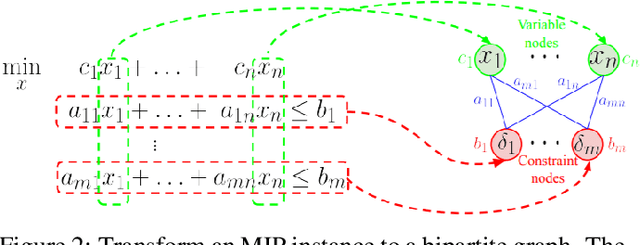
This paper surveys the trend of leveraging machine learning to solve mixed integer programming (MIP) problems. Theoretically, MIP is an NP-hard problem, and most of the combinatorial optimization (CO) problems can be formulated as the MIP. Like other CO problems, the human-designed heuristic algorithms for MIP rely on good initial solutions and cost a lot of computational resources. Therefore, we consider applying machine learning methods to solve MIP, since ML-enhanced approaches can provide the solution based on the typical patterns from the historical data. In this paper, we first introduce the formulation and preliminaries of MIP and several traditional algorithms to solve MIP. Then, we advocate further promoting the different integration of machine learning and MIP and introducing related learning-based methods, which can be classified into exact algorithms and heuristic algorithms. Finally, we propose the outlook for learning-based MIP solvers, direction towards more combinatorial optimization problems beyond MIP, and also the mutual embrace of traditional solvers and machine learning components.
Machine Learning Methods in Solving the Boolean Satisfiability Problem
Mar 02, 2022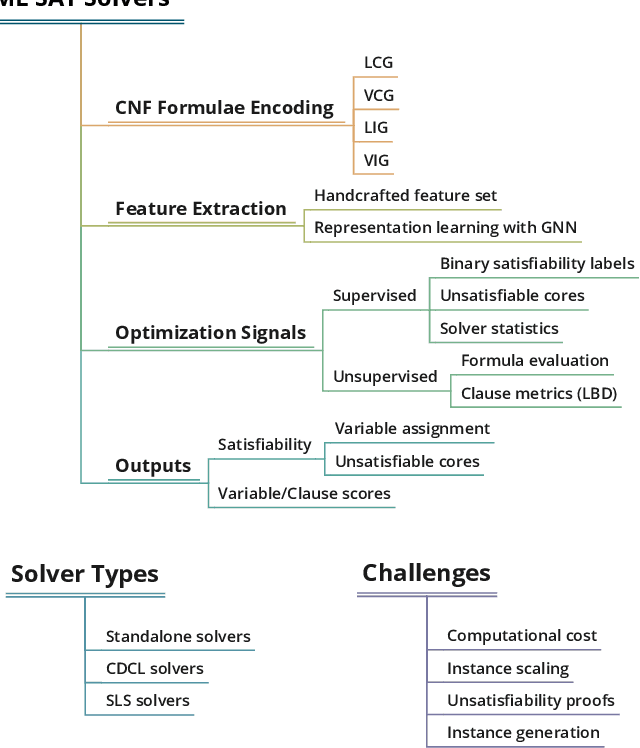
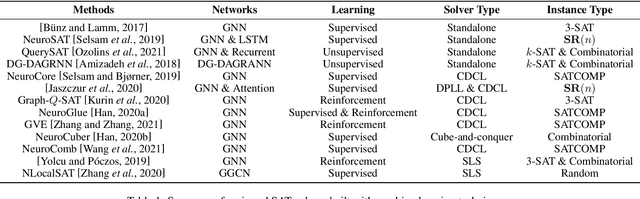
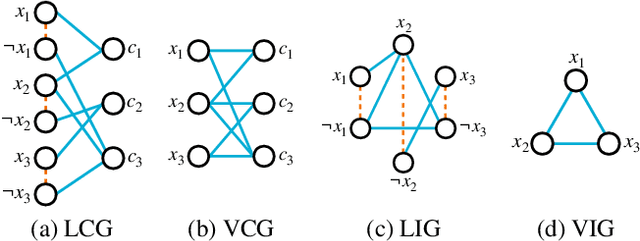
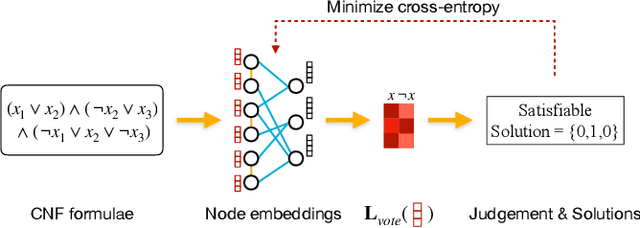
This paper reviews the recent literature on solving the Boolean satisfiability problem (SAT), an archetypal NP-complete problem, with the help of machine learning techniques. Despite the great success of modern SAT solvers to solve large industrial instances, the design of handcrafted heuristics is time-consuming and empirical. Under the circumstances, the flexible and expressive machine learning methods provide a proper alternative to solve this long-standing problem. We examine the evolving ML-SAT solvers from naive classifiers with handcrafted features to the emerging end-to-end SAT solvers such as NeuroSAT, as well as recent progress on combinations of existing CDCL and local search solvers with machine learning methods. Overall, solving SAT with machine learning is a promising yet challenging research topic. We conclude the limitations of current works and suggest possible future directions.
Yordle: An Efficient Imitation Learning for Branch and Bound
Feb 02, 2022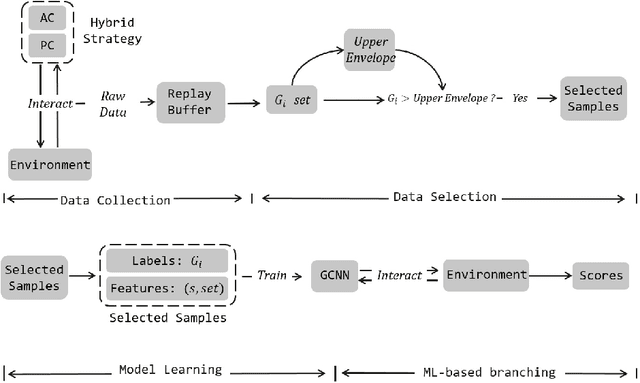
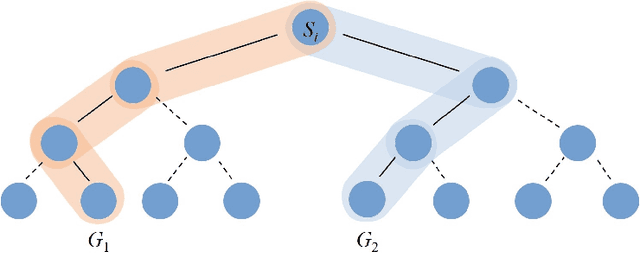

Combinatorial optimization problems have aroused extensive research interests due to its huge application potential. In practice, there are highly redundant patterns and characteristics during solving the combinatorial optimization problem, which can be captured by machine learning models. Thus, the 2021 NeurIPS Machine Learning for Combinatorial Optimization (ML4CO) competition is proposed with the goal of improving state-of-the-art combinatorial optimization solvers by replacing key heuristic components with machine learning techniques. This work presents our solution and insights gained by team qqy in the dual task of the competition. Our solution is a highly efficient imitation learning framework for performance improvement of Branch and Bound (B&B), named Yordle. It employs a hybrid sampling method and an efficient data selection method, which not only accelerates the model training but also improves the decision quality during branching variable selection. In our experiments, Yordle greatly outperforms the baseline algorithm adopted by the competition while requiring significantly less time and amounts of data to train the decision model. Specifically, we use only 1/4 of the amount of data compared to that required for the baseline algorithm, to achieve around 50% higher score than baseline algorithm. The proposed framework Yordle won the championship of the student leaderboard.
Introduction to The Dynamic Pickup and Delivery Problem Benchmark -- ICAPS 2021 Competition
Jan 19, 2022The Dynamic Pickup and Delivery Problem (DPDP) is an essential problem within the logistics domain. So far, research on this problem has mainly focused on using artificial data which fails to reflect the complexity of real-world problems. In this draft, we would like to introduce a new benchmark from real business scenarios as well as a simulator supporting the dynamic evaluation. The benchmark and simulator have been published and successfully supported the ICAPS 2021 Dynamic Pickup and Delivery Problem competition participated by 152 teams.
Learning to Reformulate for Linear Programming
Jan 17, 2022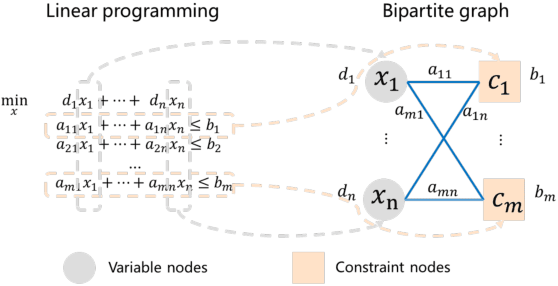

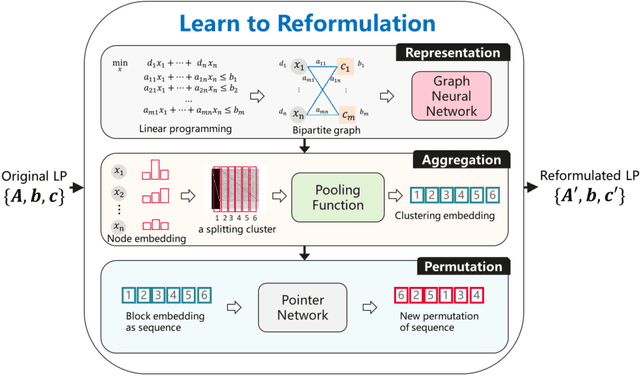
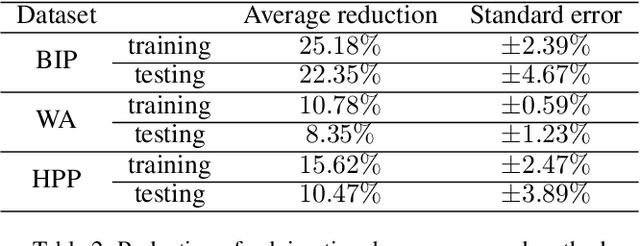
It has been verified that the linear programming (LP) is able to formulate many real-life optimization problems, which can obtain the optimum by resorting to corresponding solvers such as OptVerse, Gurobi and CPLEX. In the past decades, a serial of traditional operation research algorithms have been proposed to obtain the optimum of a given LP in a fewer solving time. Recently, there is a trend of using machine learning (ML) techniques to improve the performance of above solvers. However, almost no previous work takes advantage of ML techniques to improve the performance of solver from the front end, i.e., the modeling (or formulation). In this paper, we are the first to propose a reinforcement learning-based reformulation method for LP to improve the performance of solving process. Using an open-source solver COIN-OR LP (CLP) as an environment, we implement the proposed method over two public research LP datasets and one large-scale LP dataset collected from practical production planning scenario. The evaluation results suggest that the proposed method can effectively reduce both the solving iteration number ($25\%\downarrow$) and the solving time ($15\%\downarrow$) over above datasets in average, compared to directly solving the original LP instances.
An Improved Reinforcement Learning Algorithm for Learning to Branch
Jan 17, 2022Most combinatorial optimization problems can be formulated as mixed integer linear programming (MILP), in which branch-and-bound (B\&B) is a general and widely used method. Recently, learning to branch has become a hot research topic in the intersection of machine learning and combinatorial optimization. In this paper, we propose a novel reinforcement learning-based B\&B algorithm. Similar to offline reinforcement learning, we initially train on the demonstration data to accelerate learning massively. With the improvement of the training effect, the agent starts to interact with the environment with its learned policy gradually. It is critical to improve the performance of the algorithm by determining the mixing ratio between demonstration and self-generated data. Thus, we propose a prioritized storage mechanism to control this ratio automatically. In order to improve the robustness of the training process, a superior network is additionally introduced based on Double DQN, which always serves as a Q-network with competitive performance. We evaluate the performance of the proposed algorithm over three public research benchmarks and compare it against strong baselines, including three classical heuristics and one state-of-the-art imitation learning-based branching algorithm. The results show that the proposed algorithm achieves the best performance among compared algorithms and possesses the potential to improve B\&B algorithm performance continuously.
Learning-Aided Heuristics Design for Storage System
Jun 14, 2021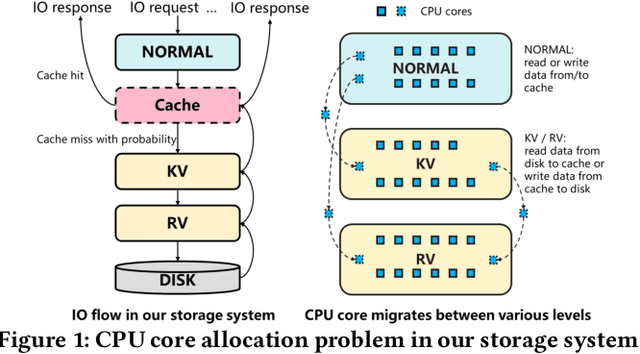
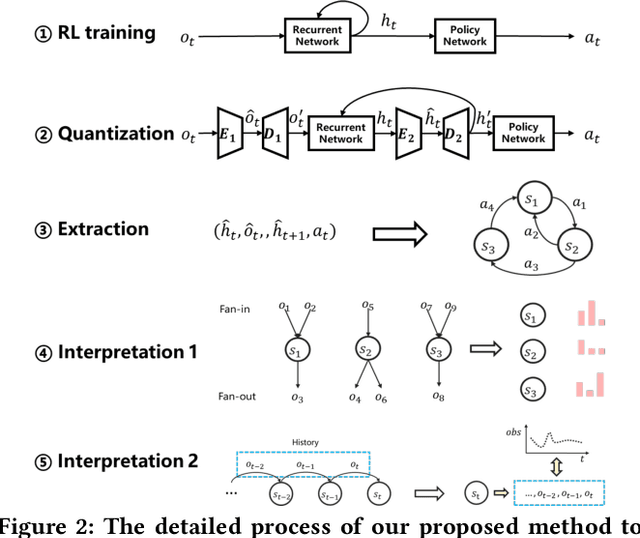
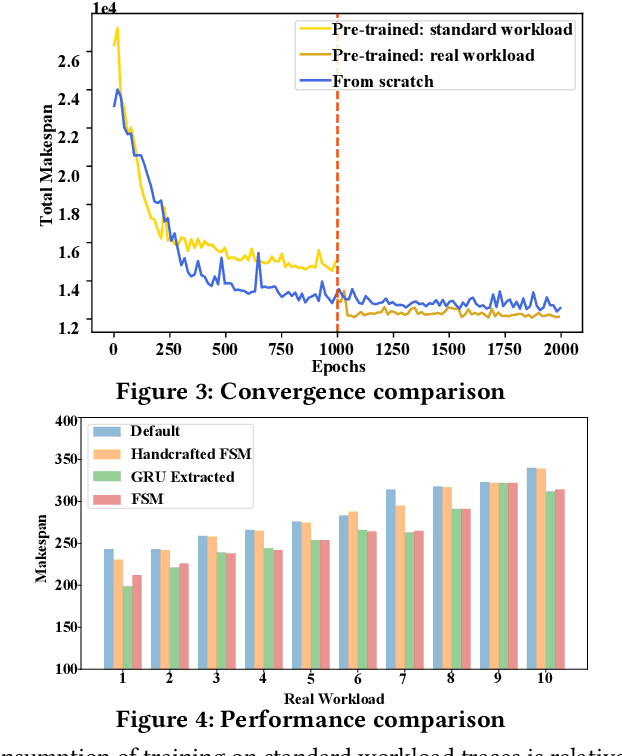
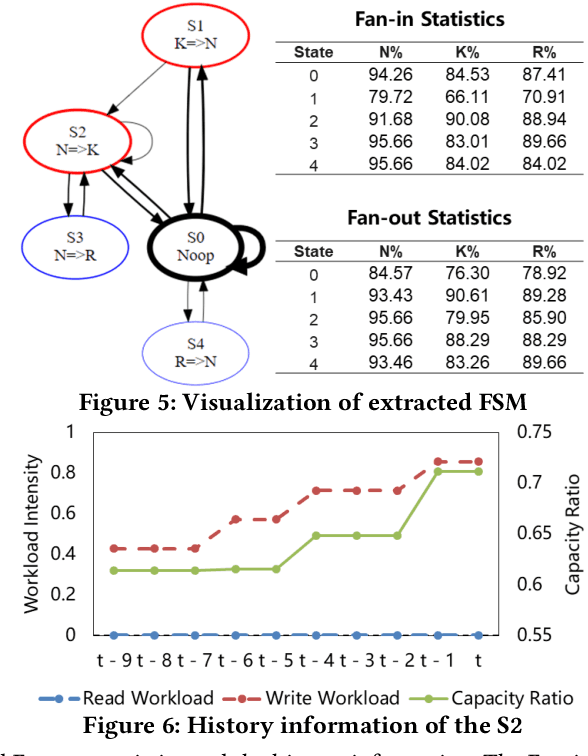
Computer systems such as storage systems normally require transparent white-box algorithms that are interpretable for human experts. In this work, we propose a learning-aided heuristic design method, which automatically generates human-readable strategies from Deep Reinforcement Learning (DRL) agents. This method benefits from the power of deep learning but avoids the shortcoming of its black-box property. Besides the white-box advantage, experiments in our storage productions resource allocation scenario also show that this solution outperforms the systems default settings and the elaborately handcrafted strategy by human experts.