 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Multiple-Relations in One-Pass with Pre-Trained Transformers
Feb 04, 2019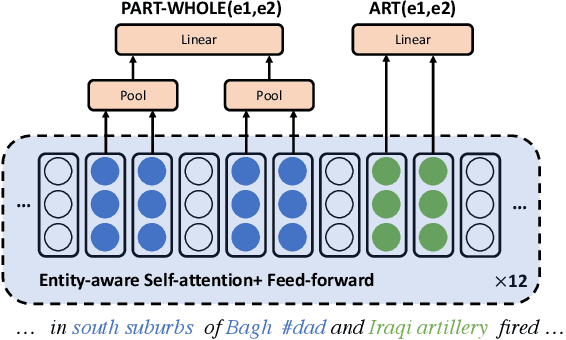
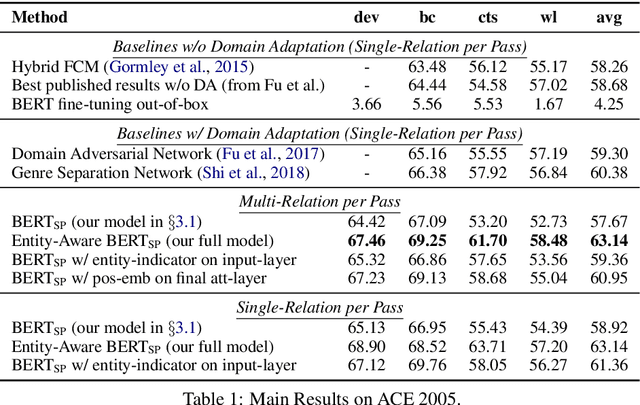

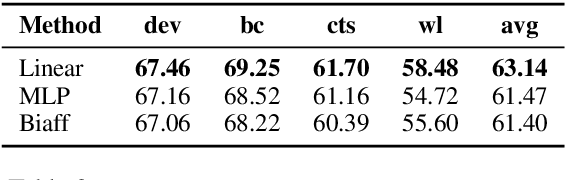
Most approaches to extraction multiple relations from a paragraph require multiple passes over the paragraph. In practice, multiple passes are computationally expensive and this makes difficult to scale to longer paragraphs and larger text corpora. In this work, we focus on the task of multiple relation extraction by encoding the paragraph only once (one-pass). We build our solution on the pre-trained self-attentive (Transformer) models, where we first add a structured prediction layer to handle extraction between multiple entity pairs, then enhance the paragraph embedding to capture multiple relational information associated with each entity with an entity-aware attention technique. We show that our approach is not only scalable but can also perform state-of-the-art on the standard benchmark ACE 2005.
Few-shot Learning with Meta Metric Learners
Jan 26, 2019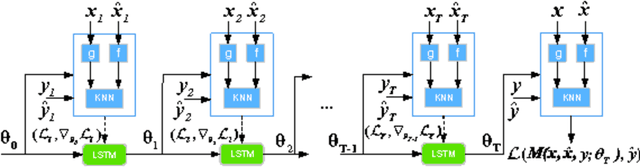
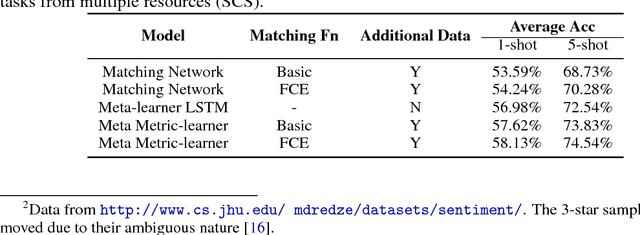

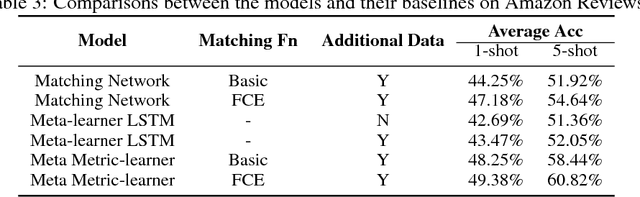
Few-shot Learning aims to learn classifiers for new classes with only a few training examples per class. Existing meta-learning or metric-learning based few-shot learning approaches are limited in handling diverse domains with various number of labels. The meta-learning approaches train a meta learner to predict weights of homogeneous-structured task-specific networks, requiring a uniform number of classes across tasks. The metric-learning approaches learn one task-invariant metric for all the tasks, and they fail if the tasks diverge. We propose to deal with these limitations with meta metric learning. Our meta metric learning approach consists of task-specific learners, that exploit metric learning to handle flexible labels, and a meta learner, that discovers good parameters and gradient decent to specify the metrics in task-specific learners. Thus the proposed model is able to handle unbalanced classes as well as to generate task-specific metrics. We test our approach in the `$k$-shot $N$-way' few-shot learning setting used in previous work and new realistic few-shot setting with diverse multi-domain tasks and flexible label numbers. Experiments show that our approach attains superior performances in both settings.
Dialog-based Interactive Image Retrieval
Nov 01, 2018

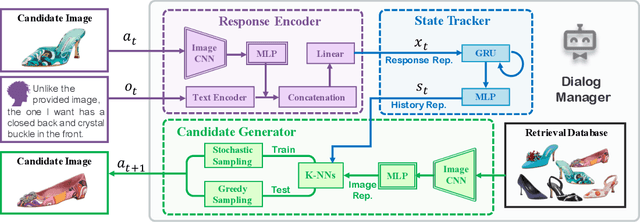
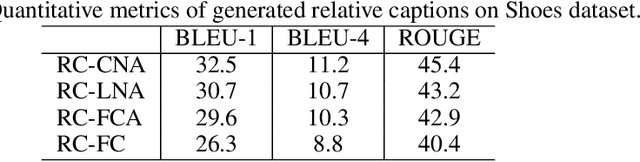
Existing methods for interactive image retrieval have demonstrated the merit of integrating user feedback, improving retrieval results. However, most current systems rely on restricted forms of user feedback, such as binary relevance responses, or feedback based on a fixed set of relative attributes, which limits their impact. In this paper, we introduce a new approach to interactive image search that enables users to provide feedback via natural language, allowing for more natural and effective interaction. We formulate the task of dialog-based interactive image retrieval as a reinforcement learning problem, and reward the dialog system for improving the rank of the target image during each dialog turn. To mitigate the cumbersome and costly process of collecting human-machine conversations as the dialog system learns, we train our system with a user simulator, which is itself trained to describe the differences between target and candidate images. The efficacy of our approach is demonstrated in a footwear retrieval application. Experiments on both simulated and real-world data show that 1) our proposed learning framework achieves better accuracy than other supervised and reinforcement learning baselines and 2) user feedback based on natural language rather than pre-specified attributes leads to more effective retrieval results, and a more natural and expressive communication interface.
One-Shot Relational Learning for Knowledge Graphs
Aug 27, 2018
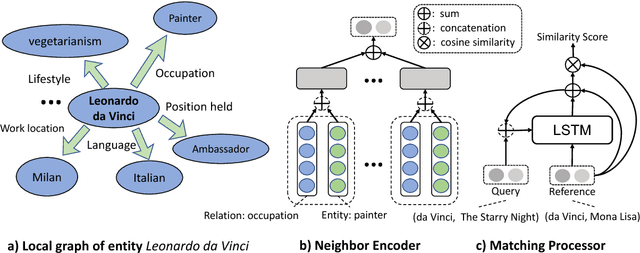
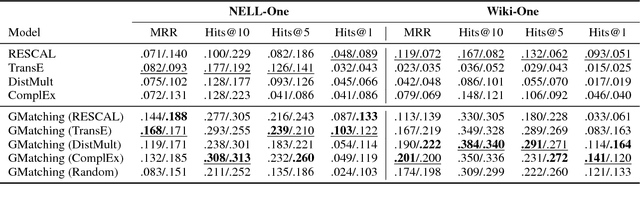
Knowledge graphs (KGs) are the key components of various natural language processing applications. To further expand KGs' coverage, previous studies on knowledge graph completion usually require a large number of training instances for each relation. However, we observe that long-tail relations are actually more common in KGs and those newly added relations often do not have many known triples for training. In this work, we aim at predicting new facts under a challenging setting where only one training instance is available. We propose a one-shot relational learning framework, which utilizes the knowledge extracted by embedding models and learns a matching metric by considering both the learned embeddings and one-hop graph structures. Empirically, our model yields considerable performance improvements over existing embedding models, and also eliminates the need of re-training the embedding models when dealing with newly added relations.
Scheduled Policy Optimization for Natural Language Communication with Intelligent Agents
Jul 07, 2018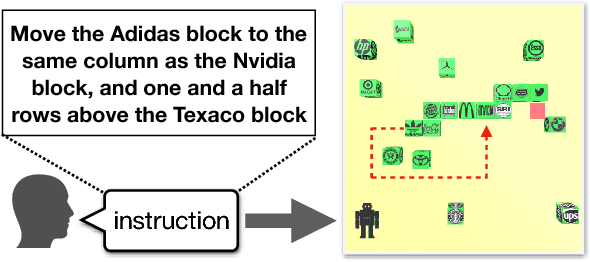
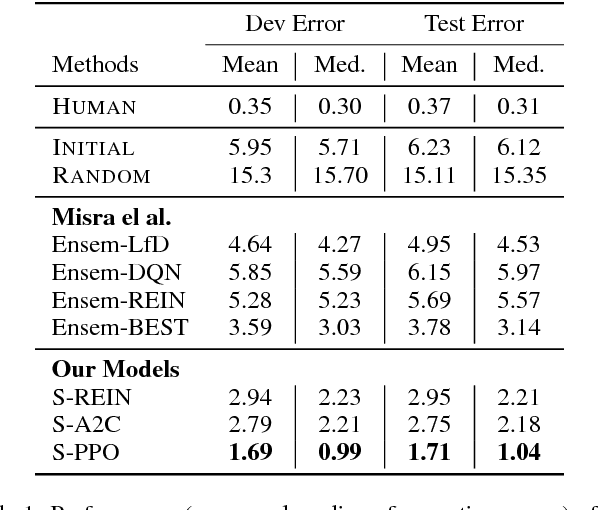
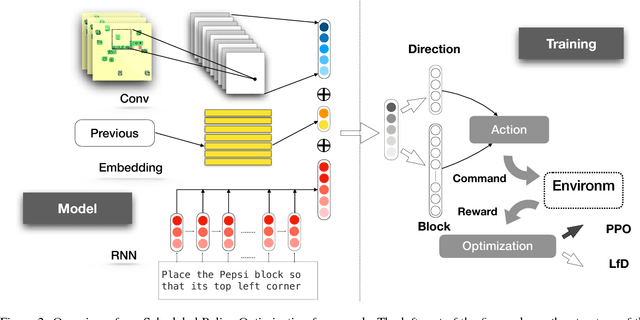
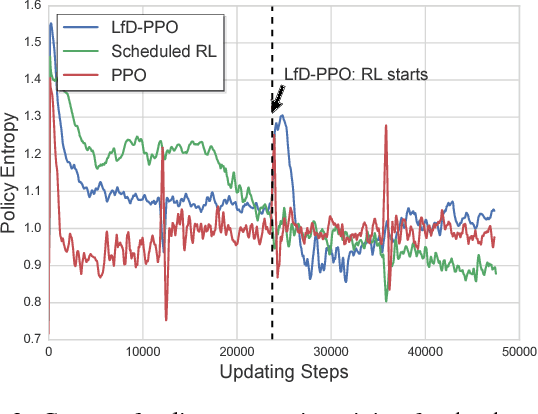
We investigate the task of learning to follow natural language instructions by jointly reasoning with visual observations and language inputs. In contrast to existing methods which start with learning from demonstrations (LfD) and then use reinforcement learning (RL) to fine-tune the model parameters, we propose a novel policy optimization algorithm which dynamically schedules demonstration learning and RL. The proposed training paradigm provides efficient exploration and better generalization beyond existing methods. Comparing to existing ensemble models, the best single model based on our proposed method tremendously decreases the execution error by over 50% on a block-world environment. To further illustrate the exploration strategy of our RL algorithm, We also include systematic studies on the evolution of policy entropy during training.
Diverse Few-Shot Text Classification with Multiple Metrics
May 19, 2018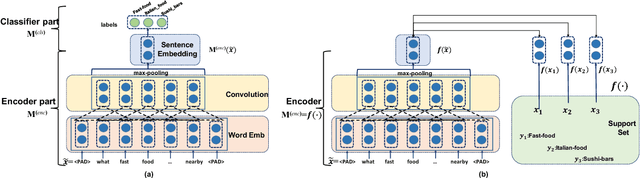
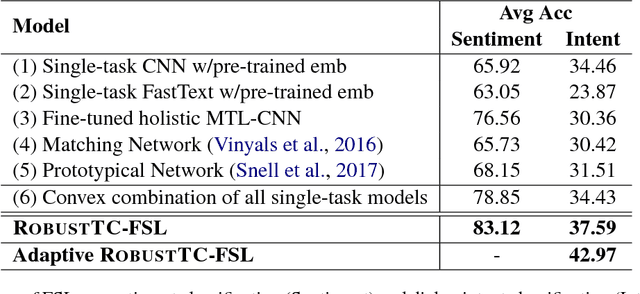
We study few-shot learning in natural language domains. Compared to many existing works that apply either metric-based or optimization-based meta-learning to image domain with low inter-task variance, we consider a more realistic setting, where tasks are diverse. However, it imposes tremendous difficulties to existing state-of-the-art metric-based algorithms since a single metric is insufficient to capture complex task variations in natural language domain. To alleviate the problem, we propose an adaptive metric learning approach that automatically determines the best weighted combination from a set of metrics obtained from meta-training tasks for a newly seen few-shot task. Extensive quantitative evaluations on real-world sentiment analysis and dialog intent classification datasets demonstrate that the proposed method performs favorably against state-of-the-art few shot learning algorithms in terms of predictive accuracy. We make our code and data available for further study.
Robust Task Clustering for Deep Many-Task Learning
May 18, 2018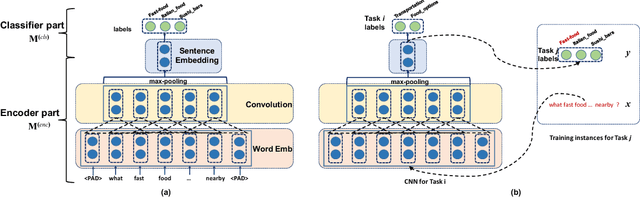
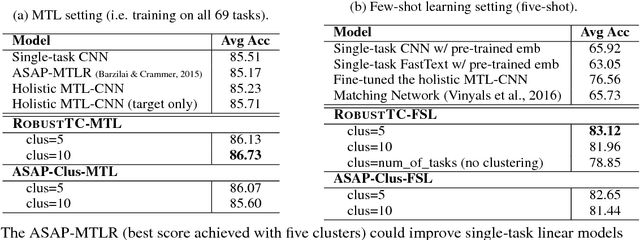
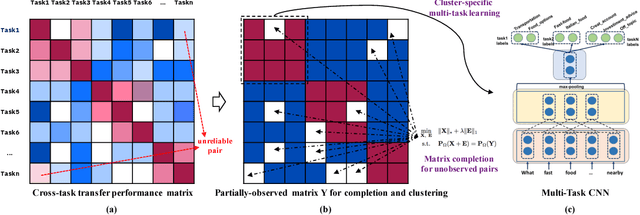
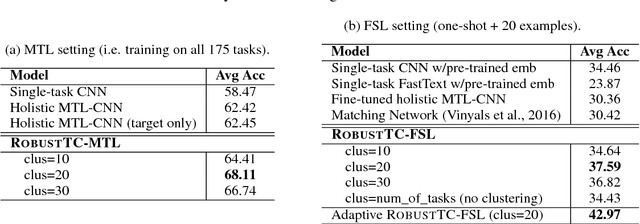
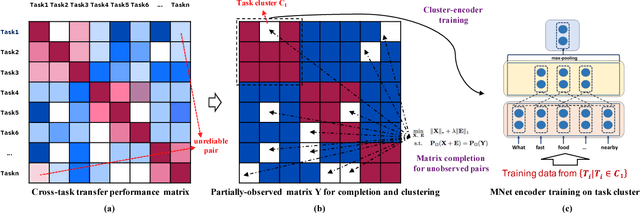
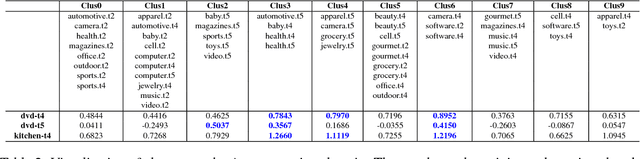
We investigate task clustering for deep-learning based multi-task and few-shot learning in a many-task setting. We propose a new method to measure task similarities with cross-task transfer performance matrix for the deep learning scenario. Although this matrix provides us critical information regarding similarity between tasks, its asymmetric property and unreliable performance scores can affect conventional clustering methods adversely. Additionally, the uncertain task-pairs, i.e., the ones with extremely asymmetric transfer scores, may collectively mislead clustering algorithms to output an inaccurate task-partition. To overcome these limitations, we propose a novel task-clustering algorithm by using the matrix completion technique. The proposed algorithm constructs a partially-observed similarity matrix based on the certainty of cluster membership of the task-pairs. We then use a matrix completion algorithm to complete the similarity matrix. Our theoretical analysis shows that under mild constraints, the proposed algorithm will perfectly recover the underlying "true" similarity matrix with a high probability. Our results show that the new task clustering method can discover task clusters for training flexible and superior neural network models in a multi-task learning setup for sentiment classification and dialog intent classification tasks. Our task clustering approach also extends metric-based few-shot learning methods to adapt multiple metrics, which demonstrates empirical advantages when the tasks are diverse.
Evidence Aggregation for Answer Re-Ranking in Open-Domain Question Answering
Apr 26, 2018

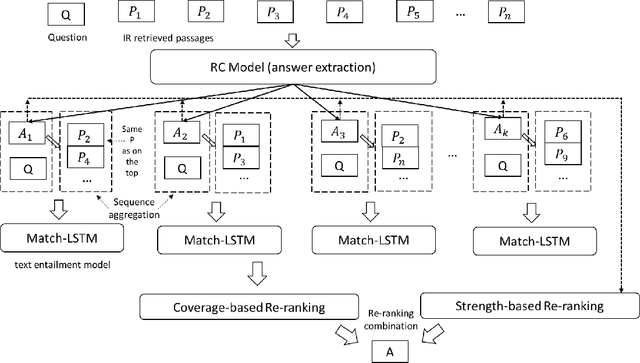
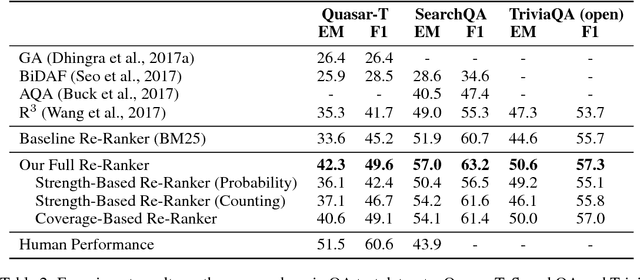
A popular recent approach to answering open-domain questions is to first search for question-related passages and then apply reading comprehension models to extract answers. Existing methods usually extract answers from single passages independently. But some questions require a combination of evidence from across different sources to answer correctly. In this paper, we propose two models which make use of multiple passages to generate their answers. Both use an answer-reranking approach which reorders the answer candidates generated by an existing state-of-the-art QA model. We propose two methods, namely, strength-based re-ranking and coverage-based re-ranking, to make use of the aggregated evidence from different passages to better determine the answer. Our models have achieved state-of-the-art results on three public open-domain QA datasets: Quasar-T, SearchQA and the open-domain version of TriviaQA, with about 8 percentage points of improvement over the former two datasets.
Named Entities troubling your Neural Methods? Build NE-Table: A neural approach for handling Named Entities
Apr 22, 2018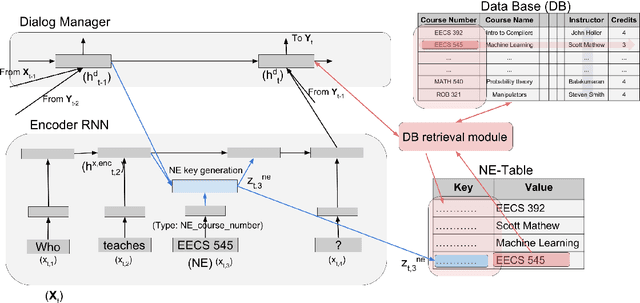
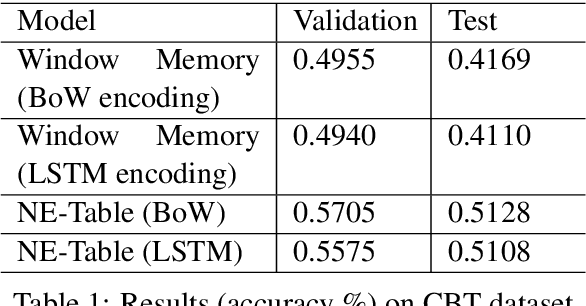
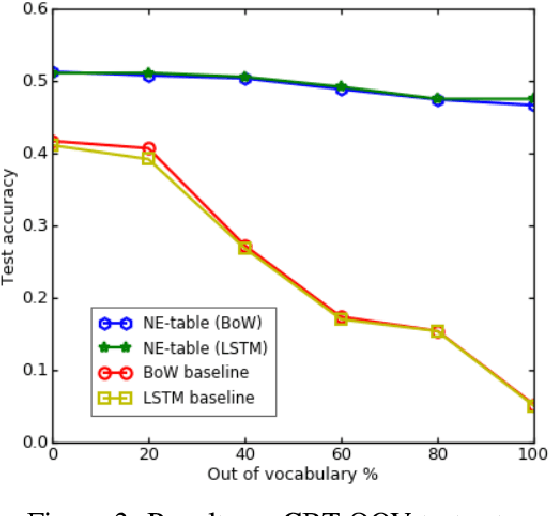
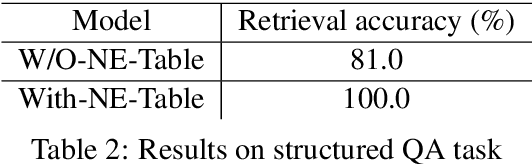
Many natural language processing tasks require dealing with Named Entities (NEs) in the texts themselves and sometimes also in external knowledge sources. While this is often easy for humans, recent neural methods that rely on learned word embeddings for NLP tasks have difficulty with it, especially with out of vocabulary or rare NEs. In this paper, we propose a new neural method for this problem, and present empirical evaluations on a structured Question-Answering task, three related Goal-Oriented dialog tasks and a reading-comprehension-based task. They show that our proposed method can be effective in dealing with both in-vocabulary and out of vocabulary (OOV) NEs. We create extended versions of dialog bAbI tasks 1,2 and 4 and Out-of-vocabulary (OOV) versions of the CBT test set which will be made publicly available online.
Eigenoption Discovery through the Deep Successor Representation
Feb 23, 2018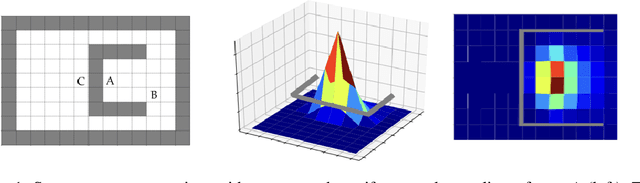
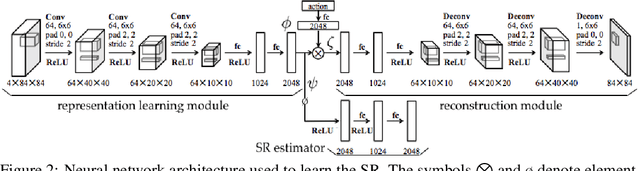
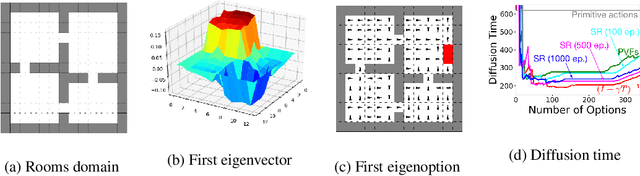
Options in reinforcement learning allow agents to hierarchically decompose a task into subtasks, having the potential to speed up learning and planning. However, autonomously learning effective sets of options is still a major challenge in the field. In this paper we focus on the recently introduced idea of using representation learning methods to guide the option discovery process. Specifically, we look at eigenoptions, options obtained from representations that encode diffusive information flow in the environment. We extend the existing algorithms for eigenoption discovery to settings with stochastic transitions and in which handcrafted features are not available. We propose an algorithm that discovers eigenoptions while learning non-linear state representations from raw pixels. It exploits recent successes in the deep reinforcement learning literature and the equivalence between proto-value functions and the successor representation. We use traditional tabular domains to provide intuition about our approach and Atari 2600 games to demonstrate its potential.